Data Analytics-Based Detection At Scale
Show original YouTube description
Show transcript [en]
welcome everyone and thank you for being here today my name is Pedro this is my colleague Ian who came all of the way from Germany to be here today we both work at Siemens cyber defence centre as for myself I began at Siemens two years ago as master thesis intern I developed a proof-of-concept rules engine in our working mainly as a developer for a next-generation detection platform that we are going to talk today yeah do you want to introduce yourself to it later yeah okay so um sudden just just my microphone a little bit yeah it's fine so before we start I want to talk a little bit about the Siemens cyber defence centre our team and what we do
so we are responsible for monitoring all of the Siemens infrastructure worldwide what this roughly means is that we collect all of the data from Siemens infrastructure in order to analyze it and detect security threats the Siemens cyber defence centre is a joint venture between Germany Portugal and the United States in Portugal we are very proud to be the largest team we are really very motivated to drive Siemens cyber security topic forward by the way if you see someone wearing a shirt like mine with that unicorn over there they are part of the Siemens cyber defence centre we are located in alpha jeans in the outskirts of Lisbon where we do a lot of cool activities like we have little
workshops on lock lock peeking we assemble our own 3d printer and we have people with different interests like we have little concerts on Wednesdays and that is to say that we have a place for everyone we also do other outdoor activities like hunting for unicorns we are not really just painting playing paintball but yeah we do a lot of cool stuff so what drove us to build a new detection platform cbins is a very large company located in more than 200 countries with more than 3 150,000 employees and this translates to a very large volume of data that we need to analyze currently we have about 60,000 events per second oops this is my micro is falling about
60,000 events per second at an average peak and to further aggravate the issue we are seeing that more and more attacks lately and there's those attacks are being even more sophisticated in 2016 2,000 malware samples we were identified each day on average and this rate increased by 328 in 2017 if we want to fight back we want to be able to detect more stuff and be able to to increase our capabilities but in order to do that how can we efficiently scale our platform how can we employ new techniques in this constantly changing environment in order to detect more stuff and how can we quickly react when once we identify a security threat before I dive into our new
infrastructure I want to talk about the old one what did you have and why did we need it to change so we started off with a pretty common set up nowadays we have a cm instance with a set of rules and lists those lists can be whitelist likely it's indicators of compromised and that all of our data from our infrastructure will be sent to this cm and be correlated once we detect something using the rule set then a new alert is generated but because our infrastructure is so large we have a very large rule set our lists of millions of entries we have a lot of events same instance will not suffice oh we don't have one
we actually have three instances and once we deployed these architecture the problems started to become apparent first of all these CMS do not scale Horizonte meaning that the computations cannot be distributed across several machines our events are simply splitted across these three instances meaning that if you want to make a calculation based on all of the events we can really do that on this platform moreover this license software is a very closed box and we cannot tailor it to our particular needs and we offer really an API for us to automate things so what this means is that every time we need to change a rule in 1 cm we have to replicate this change on the other CMS
so besides the lack of scalability and flexibility we have replicated data and replicated code moreover every time someone needs to access this infrastructure it has to access it via three access consoles moreover to abbreviate this problem there is no really analytics and AI integration so our goal was to build something that could be scalable we needed to improve the overall performance of this old architecture we need to improve the detection capabilities and the solution really needed to be flexible customizable because we need we need to be able to detect new use cases and if you can't detect them we simply change our solution to anyone and of course it also has to be cost-effective so we set
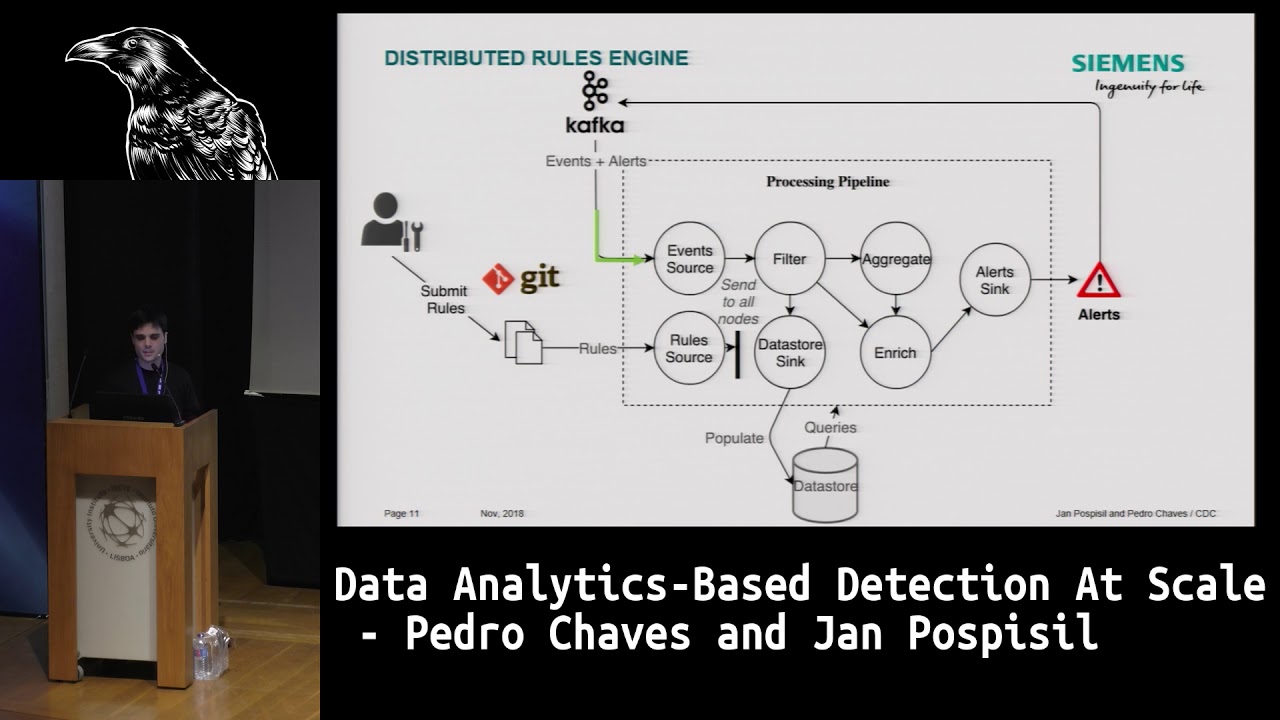
out and we try to build a new detection platform and this is what it looks like on the left side right here on the log sources are the network components and servers and sensors and everything that we need to monitor from our infrastructure and they are sent to a set of collectors collectors which parts the those logs and for them as an event the first big change that we made was to add a message broker in this case Kappa Kafka was built by LinkedIn to transport massive amounts of data from one place to another and this was very useful for us because we want to keep our events flowing moreover Kafka is highly scalable so it
can easily handle our current throughput and in the future if we need to have more consumers and have more data we can simply add a new server and that's it Kafka off also allowed us to have several consumers consuming data directly from Kafka what this means is that every time we need to build a new application we don't need to configure all of the collectors to send data to that application we simply send all of the data to Kafka and then the application will simply read that data the second change that we needed to make was to replace our cm with something new the current commercial solutions didn't really offer all of the features that we
needed and the ones that offer the features that we needed lack flexibility for us to really tailor the solution to our particular means so instead we set out and we built a new one the new rules engine using fling link with Flinx API you can develop an application in all of your competitions in data can get distributed across a fling server for several a fling cluster with several servers I will talk a little bit about slink in later slides and this particular solution but fundamentally we were able to replace our cm with distributed rules engine with a simple set as our cm incapable of generating the same alerting and where we could build the same use cases besides sending
all of the events to this rule engine we also send the events to the cloud more specifically we send the events to Athena where they can require by our analysts and this data can also be used by the machine learning algorithms to detect new use cases which again we'll talk about next finally all of our alerts are also sent to a distinct link job which enrich enriches the data and creates tickets for our analysis to triage so I will talk a little bit about flink so what the heck is think many of you probably never heard about it and those who did heard about it maybe they you don't know how it works out what it does so basically
there are two ways to process a continuous stream of data okay you can basically gather continuous together a set of data once you have a bucket you can process it that finite set so this is called the batch processing or you can continuously please process events as they come in this is called stream processing flink was built as a real stream processor as it can continuously process events and generate results with flink you can build you can program a direct acyclic graph to build your application this graph can have a source node which fetches data from yet outside you can have a set of operational nodes and a set of sync nodes to export data
to the outside as an example you could for instance created a very simple sync application which the source will be simply reading data from a socket which let's assume that our bytes which represent strings and then you could have an operational mode called a field filter which will forward events to the sync if a string contains the token Evo right the cool thing about is is that you can set a level of parallelism for a specific operator for instance if I set the parallelism to 2 for the filter node this means that the the source node can split its data to the to filter notes that can process the events in parallels okay you can have
two or more machines in a fling cluster and then this node will be replicated across these two machines the data can be sent to both these nodes in parallel and then the computations can be applied in parallel and this is how we scale our applications so why did we choose Apache Fling and not something else first of all flink is provides something called exactly once semantics which no other sim processing engine offered at a time this means that of our application files when it recovers it can recover exactly from once from where it was before the failure with no duplicated data in no event loss moreover it is scalable and offers low-level mechanisms to access even time which for instance
Esper cannot be distributed out of a box and storm does not offer such low-level mechanisms we also have it also as a an availability solution in it's very flexible so we don't out in both distributed rules engine I won't go into much detail about this engine if you have questions you can talk to me later but I will give a general idea of how you build it and how you can do it yourself so we basically have a source node that reads data from Kafka and we started to build a static pipeline to detect a specific use case for instance you can build a filter to try to grab all of the events that represent user
failed logins and you can build this pipeline in order to try to understand if a user is trying to log in more than a next number of times to specific machine indeed spelling and it can represent a malicious behavior and we want to detect it so we build this sample pipeline statically which can be used to generate alerts but we didn't want to have a static pipeline because we don't want to change the code to detect new use cases every time and you a new use case you wanted to build a new use case so instead we found a way to dynamically compile code inside of these operators so that we can change their behavior so we have created an event
processing language that I'm going to talk about in the next slides but our users can use that this simple language to upload rules to note that rules read rules from it and sends it to all of the nodes in flink and then when a node receives this rule it is able to compile it and then dynamically apply a specific function of the rule to the incoming events and this is our with an 'm from a static pipeline we change to dynamic pipeline and then we can have rules flowing in dynamically without having to stop and start the job the good thing about this is that we can add a new server to the flink cluster and we don't
need to restart anything and it will simply be one more server that we can use and then all of the rules are also dynamic so there are no restarts required to make upgrades to upload rules and to do all sorts of things which is really cool so this is mother saw our event processing language it looks like you can create three types of rules standard rules data star rules and aggregation rules the standard rules are your just our simple match please action what this means is that it's such for specific tokens in an event and when it finds them it triggers an alert which can be enriched the data store rule is very similar but instead of triggering
an alert all of the events are as for lead to a data store then we have aggregation rules which are a little bit more complex so that application rules can be used to get avenging in time windows so we can aggravate events for an arbitrary amount of time and at the end you can apply a computation to all of those all of those events for instance you can count how many events fall into that window and if that the dead count surpasses a certain threshold that you define then an alert is generated I have here a simple of a rule of an aggregation rule which was created using our own language so you specify in the sources which type of
which types of events will be processed by this aggregation rule in this case we are filtering we are processing VPN events then we have a filter function which is such for such for search searches for a specific token in these events in this case it's looking for session starts in the field name of an event if it's assessment session start then the event is further processed otherwise it's discarded then we do we have here an aggregation window which is aggregating session starts for 8 hours and then applying a computation every 30 minutes this is trying to look for a Newser that is trying to log two session start indistinct oats if he attempts to start
the session in more than three the more than two hosts then an alert is generated then we can enrich these alerts by pairing a data store in this case to add more information regarding that user so we will get a user ID and then we'll worry later storing at its name in region and then we called in richly event with a certain message saying that we found the user on this region which was attempting to start the Rypien session from multiple posts in that this is how we we developed or are we develop our news cases and then these these rules can then be injected into our rule rules engine so I will give you
the stage here thank you Peter can everybody hear me up there okay perfect so my name is young I'm the chief data scientist and cyber defence centre of Siemens my background is in artificial intelligence and in big data I start the presentation with a statistics you have already heard from Pedro of the 2016-2017 strong increase of attacks in cyber security actually I would like to point you to even one more statistics and this statistics which shows you the time lag between initial attack to the containment so which line is very important for us it's the middle line here so actually this line why it is important for us because it four or five years ago the big red bubbles here
have been right in the middle so from initial compromise to discovery it took days or weeks sometimes but today you have something like weeks months or even years so why is it that way so what we detected is that it takes today get are much higher sophisticated and increasingly get automated and we have to fight back with the same weapons actually let me guide you through a well-known use case who are well known attack and how to fight it so a large corporate network like the Siemens one is protected from the Internet we're big firewall a very powerful fire what this means basically you can create connection from the inside to outside not vice versa the same thing goes for
malware basically so if a host is compromised inside the network the malware tries to connect to its c2 hosts outside the corporate network on a regular basis let's see two hosts itself tries to hide behind some kind of domain like I am evil calm it's a stupid name right but even if the name wouldn't be that obvious the it's never a good idea to hide behind only one domain because we would at any time we would track the traffic and blacklist the domain in game of a player one right so what does a malware malware keeps changing its domain continuously like a pending index zero one zero two or three and so on again not a very good idea it's too
predictable if it's zero eight you would predict zero zero nine and one zero and also on so maybe usually uses something like domain generation algorithms this one is taking actually from Wikipedia it's a very simple one it's initialized with year month and day and then it produces every day a new string like the orange one on January seventh and the blue one on January 8th you append a domain register restore main top-level domain you register the whole domain and start you have a connection okay in reality the algorithm is not that easy and reality it's not that easy to distinguish between manifest domain and normal domains on this slide you see a mixture of normal domains negative
mental mains and malicious domains and you can try to find out which of these domains are really malicious so I think the task is not easy here right so it's by the way not easy for any human human cognition is not made for things like this is not made for detecting things like this so in fact humans detect the malicious domains only by chance so the orange ones are the malicious ones all the other ones are legal domains Lego tomato means they are the normal domains including the very long one at the bottom of the slide it's the name of a city in Wales actually that they prove that the weather forecast on British TV
so as we fight out that humans are not able to distinguish the domains from normal domains so we decided to bring a tie to the fight we took several approaches actually some more traditional approaches on a most left-hand side here so you let you let some experts design stir mystical features on the domain name like changes from well to consonants and similar statistical properties feed it into our machine learning algorithm like a random forest or a gradient boosting machine or something like this and check what happens can they distinguished DJs from normal domains and actually here the occurrence is not bad it's 85% it's actually better than NAU in Kundu next approach you take an approach from
natural language processing actually more specifically from sentiment analysis so if you type in your comments to Netflix on a on a movie or something like this they do something like this so they extract engrams from a domain string which means this are snippets from the domain string of length or fixed length we or something like this so we extract wwwww dot W dot F and so on and so on you get approximately 54,000 of these features you encode everything into a frequency vector again feed it into a machine loader and again looks what happens 88 percent accuracy that's even better this one then this one approach but both approaches have a big disadvantage and it's in the third
column of both algorithms it's a false positive rate so false positive rate means this one 9% and 30% this means basically the rate of false alarms so in our case 30% or 9% leads to several thousand false alarms per day and this is completely unacceptable actually because every every alarm has to be tracked by a security analyst and we would drive this guy's crazy basically so we moved a little bit further down the road to a little bit higher advanced AI algorithms called deep learning deep learning is the latest development in neural networks actually and deep learners have several beautiful properties one of the beautiful properties is they learn their features on their own if you gave them the right
data the other beautiful property is that they can push down their false positive rate close to zero only if you give them enough data to learn in our case below is even 0.7% let's result in a false positive rate around 50 false alarms per day into this acceptor and people are basically set up looks like this one you feed you know from a top layer you feed in their domain again all the domains I'm evil calm you're talking i that you converted to ASCII code or something like this then you reduce a little bit in dimensionality who embeddings your remember they're very high dimensional stuff the forty fifty four thousand in the previous example and then you use
one of the famous deep learning algorithms which are used today something like the LST mo GRU they are from the domain of recurrent neural networks recurrent you and networks are for example used for machine translation so if you type in a Portuguese text into Google you get an English text you usually have an LST M model behind this one so it's all called sequence to sequence learner and you but you can also use something like a convolutional neural network this is from the picture processing domain actually from picture classification so all these applications like detecting uncredible cute cats in YouTube videos go with convolutional neural networks usually something like this you run it for and classification
layer and get an output for example a sigmoid function where you classify is it in DGA or not softmax function is usually use if you want to know which type of dg8 is getting one step deeper we try to find out how it works actually or if the all the specific vga algorithms we found around 6465 around from the database from the fluorophore institute it's a German Research Institute they reverse engineers all the DJ's let it run and they give you and they give you a database how the created domains look like so the upper left side here is again the deep Lerner on the left-hand side you fit in their domains on the right hand side you have
1 euro per VGA type and if you get an output here from the DGA type the final layer the final hidden layer inside this neural network has to came contain the whole information so it took this layer method to a two-dimensional space using a technique called multi-dimensional scaling and looked if they are well separated and you can see yes for example DJ of type 1 here the yellow one is far away from the other ones here and here then you have for example the you know the blue one which is type 3 it's also very well separated so the only one which is not very well separated the green one here and this is a special type of EGA so-called
dictionary based DJ's they use google dictionaries or regular dictionaries permute their words for building up the new domains and not shifting around letters like the code from Wikipedia I've shown you in a previous one of a previous slide anyway they can be handled by different deep learners and you can fix this as well so we have to cope with other problems that a large corporate network like Siemens pedra already mentioned we have 60,000 events per second which means we have to ask the d-plan of 60,000 times per second is it an ETA or not and what type of the year it is for example we capture 6.2 terabytes of data and we do it 24 by 7 of course there's
always sunlight somewhere around the world right for this we built a big powerful platform on top on Amazon Web Services we used only a subset of the Amazon path services so-called serverless path services these services have some properties where they are fully managed they are auto scaling and they are how to fail over we wanted to get rid of this task syndrome we divided this whole platform into three zones in ingestions own storage zone in the serving zone the congestion zone consists mainly of a kinetic stream engine and there we get the data in from Peters part actually from a Fink engine we pass it through to a landing zone there is picked up by a blue angel this
is a managed SPARC version basically there we do all the cleaning of the data and we do the complex pre-processing which is usually needed for machine learning for artificial intelligence from this point on we move everything through our AI prediction system is mainly based on tensorflow tens of lawyers from Google um somebody may know it so maybe it's famous for if you know it probably from alphago that engine which has beaten all the world best goal players so it was basically the same engine it's open source we enrich all the data inside here detainer database and then these results are presented to our incident analyst or security analyst these guys can use it either for better decisions
for faster decisions or we create them certain alarms which then point them to certain types of text for example types of ETS or something like this the security analysts are not only actually I'm very important part in the whole platform here we do not they do not have only the task to find the right attack and somehow to contain it but they also are a source of final truth for a platform actually so when they decide so molecular this way so when tens of law decides this is an attack of type a and security analysts decide no it's wrong we feed back all this information back to tens of law weary label the data sets
retrain the whole system and next time it won't make this mistake again that way we increasingly get better results and then nearly
yeah thank you that's it any question hi so basically when you're using machine learning are something like AI in security you have to have the presumptions that you know what is good and what is not and then you can teach the the system how to distinguish between one of the other have you ever how do you do that and how do you prevent that the system learns something where there's good and then exponentially keeps using a loop of keeping bad behavior over and over ahead and then minimizing the efficacy of of detection to possibilities you have like in every machine learning or AI you have the possibility to use either unsupervised learning so you train you
train the algorithm to learn the normal state somehow and then everything what deviates is usually something that that's one possibility but it produces usually a higher amount of false positives so the other possibility is of course you give you have the information in the data set what is good or what is bad in that case you need to have labeled data so something like in the case of domains you have a data set its domain is good this domain is bad this domain is good or something like this and then you get usually very low false positive right so if you do not have if if you do not have label data you can only go with the unsupervised case but
in that case you strongly have to rely on the specialist and I have to keep them constantly in the loop that you improve the system constant they give their feedback and that way that's the same basically father-like for the DJ's so we constantly keep them in a little bit so we take them as final truth if they say no that's not a DJ but you said it's a DJ we correct the whole data set and say ok we train it so right the end there you are saying that you use human input determine whether the end result is a true positive a false positive do you have any detections for false negatives sure so the statistics of getting all
this information are there I do not have it with me today but if you are interested in we can have a discussion on this later on do I have it for sure somewhere my computer hi good stuff like ours Marla from the University of the autumn I have a question of three questions actually how do you consider the adversarial nature of the attacker regarding the complexity of the VGA and an idea of the levels of your deep learning that that the attacker may may know so can the attacker trick your your AI system and you consider that that's one second one is do you have an idea for it didn't the first one fully okay
so can the attacker trick your AI system basically did you consider that and what are you doing without to that the second one is do you have an idea of how many DNS requests are not going in plaintext and are going encrypted so ciphered so that means you cannot really use the AI to make predictions and and the final one is I didn't get under to understand where are you using AI in other non DGA non DNS domains in networking reason thank you okay first one can you trick somehow the deep learners it depends it depends on the way how they're trained and so it's it's a task of the data science team here to make the D plan of somehow not
memorizing all this information by generalizing and then it's really difficult because what we found out that if you make this deep learners generalizing they do not learn that they do not memorize the string simply by the reverse engineer somehow the way how the DGA works and that's what we found out so in our training set most of the DJ's we detect today is not available so it's really so they learn somehow the way how the DJ algorithm works and there are currently approximately 60 65 different DGA types around which are used actually and if you bring a completely new DJ algorithm they may be trick definitely yes so then we need again to take the
new examples in our database and retrain all that stuff second question was so ciphering the so there's DNS over HTTP and other so so basically how far how much do you know in your network yeah or DNS is being used in plaintext versus not maybe you don't know actually so yes if the Texas cyber nodes usually if you take the whole URL into the into account at all a domain the domain is usual but yes so we had some experimenting with whole URLs where the whole content of behind flesh and all these tough arguments is encrypted works as well so for some for some reasons obviously the structure of the encrypted text still has some properties which can be
detected by deep learners the hit rate is not as high as with a pure domain stuff definitely but it's helpful at least for analysts to find out it gives him a hint to where to point to or where to look to actually and if the final thing is did we do something I did we do applied ai in other domains not very much like right now we actually the plan was to first build up the platform with this high performance platform for this stuff and we are going into new use cases like actually finding also communication to see two hosts which if it goes for example Twitter or something like a link in or something like this
and that would be a case like this one that you have to take into account the whole URL information the information which is usually encrypted and find out if you can also get properties the few deep learners can learn properties from exactly this string its encrypted string and pointed to this one definitely a much more complicated huh thank you very much welcome hi my question is how long did it take to go from the old architecture to the new to the new one yeah so we actually started that development during my master thesis so it was nine months it was to develop a proof of concepts in order to replace our current infrastructure so we were able to set up
Kafka we able to set up our collectors and we were able to set up the rules engine in just this interval right so it took about nine months for this first PLC and then more nine months around more around a year just to fine-tune stuff to improve the language and then the operational stuff like if it is something is done or if there is a problem detector we need to detect time on almost two years hi thank you for the talk but I need to know one thing do mark a bit domain or good mine only by the URL or by the content of the domain only domain oh it only domain not a URL
the URL is a bit different case actually there are two reasons for now to not use the whole URL one reason is that there are not a really good data sets available for the whole URL stuff it would be necessary actually for example for the case that the communication go through Twitter through I don't know through LinkedIn through Facebook or something like this or would like it would like if you have to such a data set and but and there is a deviated a set which is available or multiple digits which are available they they are labeled so the labeling is usually the most expensive task in machine learning so if you don't if you don't have it you
have to do Yuja frauds actually oh he said I don't know no okay so so labeling you could if you don't have some kind of source without labored datasets you do need to do the labeling yourself with simulation with help from other people and all this stuff or even by the data sets and the second reason simply it was not necessary for the parasite that domain was completely enough thank you [Music]
hello thank you for this presentation if I understood correctly your system is able to detect a pattern that generated a domain but how does the your machine gun deals with the mines that are not wood but are just random words from English this means that the mine is not tolerated that is just random words put together and therefore are not in writing how the system deals with them sorry I did not fully so what do you mean what type oh yeah when did I mean is just random words like for English words how does the system deals with these kind of mines when they are not a pattern when they are not generated because if I
understood correctly your system detects the generation algorithm the pattern of the generation right yeah and if the domain is just words like simple English words how does the system deals with this yes so that's one so this was one of the actually initial problems with the system of course that if you have a beautician of regular words they are not very well it detected but at the end you can also use for the machine learners dictionaries where they know actually the patterns from the words all you can combine it with an ensemble approach with with other learners like fast exiting thing like this and you and you use in one assemble approach a diploma too though together with a text
specialized learn or something like this so what we do in that case usually okay thank you [Music] well let us think if you like that's a good question also I guess the question is there are some DJ's that have different it's the same DGA but uses different seeds to initiate the DJ algorithm and the question is if the system is able to detect separate seeds of the 70g a Yantra is the training data that we use for the deep learners we didn't know actually which seeds have been used by the attackers surely so what you get from from the database for example from the throne or in-situ database as dataset they reverse engineer 60 types of TGS actually they
used some kind of random seat and this is definitely not the seat which is used by the attackers we have seen anyway the deep learners and that's one of the beautiful properties could reverse-engineer some other algorithm and somehow it detects also DJ's without with a completely different seat so that's that's a little bit downside of a deep Loden it's not really known how they work internally what they did and this results you have seen and about you know okay that's a 0.7% are done with seats we haven't seen before thank you any more questions let us thank the speakers please
Related talks
 49:41
49:41 55:25
55:25 29:03
29:03 50:58
50:58 26:05
26:05 31:52
31:52