Deep Adversarial Architectures for Detecting and Generating Maliciousness
Show original YouTube description
Show transcript [en]
hey everybody uh Welcome To The Ground truth track besides Las Vegas uh please remember to visit our sponsors out in the chill out area because uh they're awesome and this couldn't happen without them uh without further Ado this is ham Anderson he's a principal data scientist at endgame and the alternate title of his talk which he told me should have been the real title is deep learning red teaming thanks give it up
thanks um grateful for to Ken if you caught the previous talk in this session was really good and um with apologies to Ken um my name is ham and I am a data scientist that's a confession and I do like tomatoes I guess so the purpose of my talk today is is really threefold and I hope that you'll find at least one of them interesting number one is that I'm going to spend a little bit of time uh simplifying and demystifying hopefully what is deep learning which is uh being touted fairly or not as one of the key enablers for you know signature malare malware detection and other threat detection Technologies so we're going to
bring it down a little bit simplify that that's objective number one objective number two is that I want to show that like all defensive Technologies machine learning and and deep learning um have vulnerabilities and actually what makes deep learning so great for a data science to train with also makes it really convenient to exploit and so we're going to exploit a bit of our own deep learning models today and uh the third thing that the third takeaway from this talk is that um what we're actually going to do is build two deep learning models one of which will will exploit one will take the place of a blue team one of the red team and they'll play an
adversarial game against each other and we'll use this to be able to patch some of the vulnerabilities in our deep learning model so I've just given you my talk if you want to leave you could do that now but if you want details stick around for the remaining uh parts of this talk so Andre if she raised her hand made me put the slide and I'm going to spend 30 seconds on it my name's hyam I'm a a data scientist at endgame I've spent some time in the National Labs and at other infoset companies um and uh I have research interests uh and you can follow me on Twitter okay so let me motivate this talk today uh by a a not a
machine Lear anything we're going to release a product and uh we want to make darn sure that when we release this product to our customers that it doesn't fall over so we have one of our um our spooky internal Red Team guys uh start uh throwing in this case uh domains at it and make sure that ame.com passes through our product successfully but that um a malicious website uh you know some some fishing website endg game-2 2016 is properly detected as bad um and then my goodness he does find one that should be bad in MD gain.com but our product product says that it's good he finds a problem so of course he then takes uh this feedback to the products
team and they patch that whole so that hopefully the product that he releases doesn't have that that vulnerability now this is no different than what we do and and if you caught Ken's talk previously what we do when we're releasing a machine learning model uh there's a there's a similar process of validation where a human is in the loop and is trying to make our model fall over so uh replace product with machine learning model the process is almost identical this process will never go away we'll always need our super smart security guide to poke holes to find holes and to patch vulnerabilities in our machine learning models but part of the thesis today is that we can enable and scale by
um giving that human also the extra power of an additional red team model and the red team model is going to be specifically designed designed to poke holes in our blue team model and uh by poking holes and discovering those we can go ahead and turn around patch those holes and feel safer about releasing our machine learning product to our customers so that's the 40,000 ft overview and here here's the outline I'm going to spend just a few minutes on introducing some of the concepts behind deep learning hopefully simplify a little bit um and demystify what can sometimes seem like Hocus Pocus um I'll I'll uh then sort of jump into the meat of the talk today about
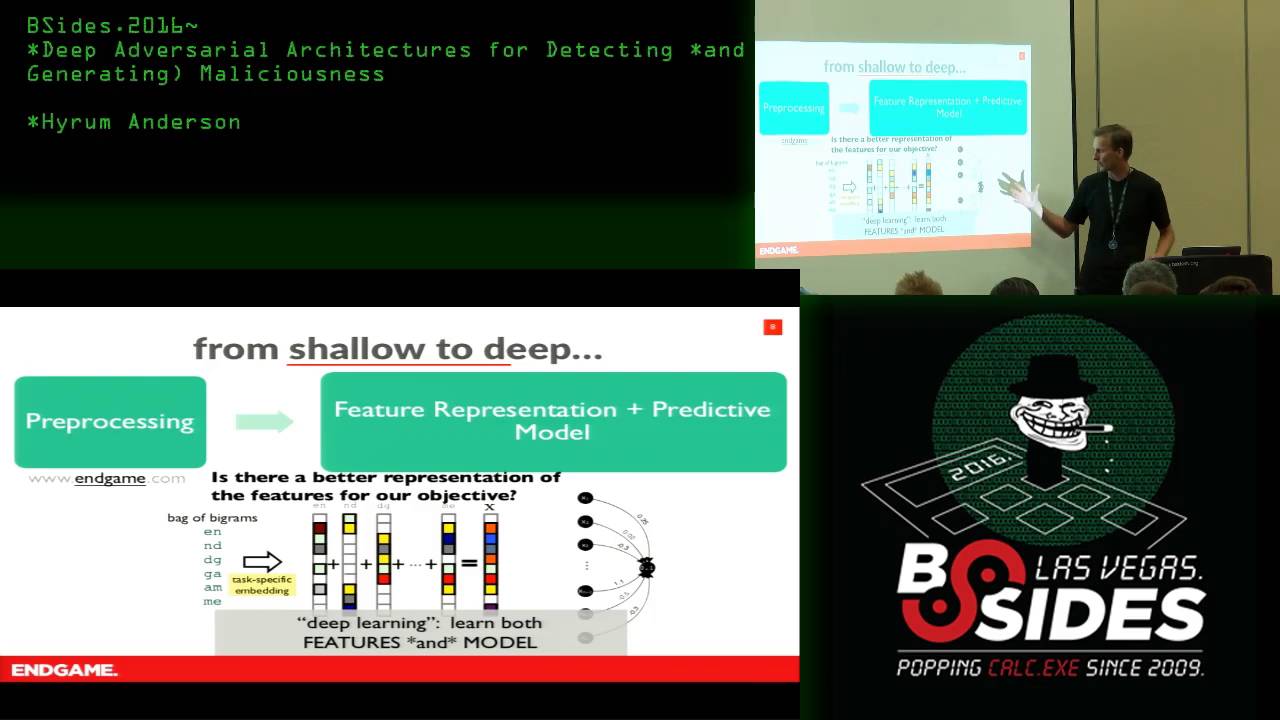
how to assemble these deep learning components to form this adversarial game that where two models play against each other and then the the sort of the application today we're going to be talking about is detecting uh dynamically generated domain names that malware sometimes us just to establish C2 channels call home so um without further Ado to talk about deep learning I'm going to take you back to what deep learning people call shallow learning so shallow learning goes like this first uh there's there three General steps there's a pre-processing step there's a feature representation step and there's a modeling step so the pre-processing step are things like um we don't care about dubdub duub or. let's get rid of
those we're going to prepare our data the feature representation step is all about uh our our models are good with numbers and we need to express in this case our domain name using numbers and then our our predictive modeling step is going to be how do we use those n numbers to predict on more numbers more domain names that have been pre-processed and represent features so in Shallow learning the process is a bit like this let's take uh endgame just the root of our domain and we'll break it down into a bag of byrams every uh consecutive pair of characters so e n n d d g g a m m and then we're going to
sort of arbitrarily at this point um and this is kind of the point figure out a way to express these these byrams as numbers so what we're going to do is Express every Byram as a vector a stack of zeros where one bin in that stack of numbers is is a is a one that one that bin corresponds in the first Vector to Y the second to and so on and then let's you know for the sake of being completely arbitrary we'll just add those all together to get our our feature representation the vector X which now is a a bag of these diagrams that represents endgame so there are problems with this right you could you
could um scramble the letters of ingame a bit and get vectors either very close to or identical to this but this this is one way to express uh endgame as as a as a bag of numbers that's now suitable to a to a model and so um the the model that I'm going to just show really briefly today is based a little bit on uh uh the linear model that kin showed in the previous talk and all it is is this essentially we're going to take this bin of vector and we're going to learn weights for every bin and do a multiply weight by bin bin value add them all up squash that number between 0 and one and you
now have a one means bad and zero means good for example and this is called logistic regression and what I've just explained to you is a can be a really time consuming process because if I learn a model it doesn't give me the right answers I'm going to probably blame the way I represented my features or or I can blame the model but there's these kind of two moving Parts three moving parts of I can't pre-processing so this is what we call uh well what deep learning people call shallow learning I have done this separate step of trying to figure out a way convenient way to express endgame so that my model can ingest it and then
make predictions so deep learning deep learning all all it is in a nutshell is trying to jointly learn both the model and the way that we express things in our model the way that we represent them and it's so-called deep because um it requires not just sort of this one layer of of logic but another layer to EXP um how we how we represent uh those features so deep learning in an learning both the features and the model so uh if if you if you could if you were to spend um 30 minutes today firing up deep learning is become it's becoming commoditized there are software packages that are excellent that can allow you to assemble uh deep learning
models in in relatively short order and um just as as a you know kind of an anecdote um with something like uh two hours of coding and 12 hours of training a model at ingame we produced a hip chat Trump bot that you talk to it and it it talks back to you in slightly racial overtones and so uh but but the idea here is that the the the the big win comes that you spend only a little time developing model and data is the key ingredient to making this thing go and uh you assemble these things kind of like you assm Legos or uh you know these would be your resistors and capacitors and transistors of a circuit board once
you get the basic idea about how they work you sort of plug them together and you know it just kind of works because of the hard work that's been done by a lot of these folks and and preparing these you know commoditizing deep learning packages that'll I'll explain to you in just a moment but the first the first lay let me just go through these five here because they'll become uh useful in a moment but the first one I already described is called logistic regression I take an input vector and I I add add the uh the inputs together and I squash it with some squashing function and have an output the next layer is called a fully
connected layer and it's just like a logistic regression layer but repeated the output is repeated three times so there are three different outputs and this is useful when you want to express uh the to reexpress the input as some intermediate representation and the key here is you don't tell it how to represent the model learns how to represent based on the task that you're trying to solve okay then another useful layer that that uh is really popular and you should know about is called the convolutional layer and it's you know very much like a connected layer except uh where these blue arrows are colored uh they all share the same weights so this gives kind of two things um one is
that um convolutional layers are good at detecting that there is something but not where it is there's a translational invariance and and second is that because there are fewer weights involved this becomes a really compact model I don't have to store as much so that's kind of an implementation issue so the the top three layer Legos are all so-called feed forward they take an input and transform it to an output and the the model and the objective learn how to tune those weights the weights in this case being the edges between the input and output nodes on the bottom layer I'm showing just two simple recurrent neural networks where the output is a function of both the
input and the output itself and so this is really interesting because if I instead of feeding one input Vector if I feed a sequence so first I feed it A1 B1 C1 and then A2 B2 C2 and then A3 B3 C3 in that sequence it's going to learn in these output States d and e some kind of you know State some notion to capture meaning about the sequence of things plugged in because there's this feedback part of it and this thing is looks very complicated I'll not say much about it but it turns out that these simple sort of recurrent networks are very hard to train and uh there are other mechanisms and in fact the the Deep learning folks
have have taken this from computer so so they have read and write Gates that allow one to train and store information efficiently over a sequence so that's all say these These are Legos these are Legos and once you learn what the Legos do you can stack them together and and write write really small code so I'm going to just give a shout out to this package called Caris which you can write in Python uh a deep learning model in about I don't know 10 lines of code and uh so what you do here is uh I'm going to define a shallow model first the the model will just be an input so I say model. add this this input layer and
I've chosen the the number of the number of uh Dimensions with which to EXP express my input that's called embedding Dimension and then I'll have a single output layer again that's called the logistic regression layer a single output with with a sigmoid activation and that will uh that will give me a number between 0 and one so all I have to do now is feed it uh input data and labels and it will learn by twiddling these weights which ones it should assign to zero and which ones it should assign to one so this is really easy if if we can you know add this shallow learning with just a few lines of code we can certainly add
um we can certainly add another layer this this second layer now will have some some other intermediate representation about about how to to express our data and and here's the key to deep learning now is internally in-game we actually call this Brute Force differentiable learning because why not add a million layers because the software is going to do its best to try to uh try to optimize your the output you give it for the inputs you give it and just learn all these weights and um so uh this this becomes just kind of an engineering game you you try things and and usually it'll kind of work and then you Flip Flip some you know replace some
Legos and it kind of works a little better and at the end of the day you you can build a a hip chat Trump bot so um you know just uh incidentally I think our hip chat Trump bot was uh was just about 20 lines of code and and looked very much like this and it was really the data that make made it work okay so a dirty secret about machine learning and about deep learning is that um they have uh they they have vulnerabilities like all defensive products and there there is there is not a machine learning model unless your data is trivial that will will not make a mistake it's a fact in fact uh um one thing that makes deep
learning so attractive is that I can solve these massive problems and take on these big models because the model is different iable and if if you took high school calculus remember a chain rule if you differentiate something you with respect to another function you you do this chain Rule and that is all that deep learning is solving that is just the chain Rule and application but guess what because of calculus # thank you calculus we can also exploit uh deep learning and it because machine learning and deep learning have these blind spots I'm going to show you exactly how to do that so just just for fun there's a deep learning model and image credit here that uh with 57% confidence
believes that image is a panda now I'm going to just add the tiniest fraction of noise um if you'll notice it's this is what the noise looks like but it's scaled by 71000 so it would look black to you you you wouldn't notice what the additive noise even looked like and incidentally if you fed this uh almost black image that's scaled for visibility if you fed this to a deep learning model it they would say that's a Neiman to with 88.2% confidence and if you add those two together well my goodness now the Deep learning model thinks that you have uh a gibbon which is not a panda with 99.3% confidence so this is a
problem this is a problem for those people trying to tell the difference between pandas and Gibbons obviously but think about the problem in information security where uh these kind of images um instead of images we we're working with we're working against an adversary so this is an important slide if you remember nothing else remember this slide all machine learning models have blind spots they have vulnerabilities Because deep learning is makes this these challenging problems simple to solve it also makes them especially uh well suited for exploitation um what a third thing that we're going to exploit in this talk is that if I and it's kind of scary if I can find an adversarial example for deep
learning there's a good chance that that adversarial example will also fool a completely different model be it deep learning or random forest or support Vector machine whatever there's a good chance that the these can uh translate across different machine learning models so that's a bit scary that means that the adversary doesn't need your model he just needs a model and maybe he can begin to find these so a key difference this has been studied in in Academia for the last years this notion of adversarial examples but there's a difference between adversarial examples for an image classifier and adversarial examples in an information security domain and the key is that if we don't patch it somebody will
find it um very unlikely that this you know this picture is going to show up in the wild and an image classifier will you know make a big mistake calling a panda a given but information secur to the cost are different we're working against an adversary so what we're going to do is try to be proactive and discover those vulnerabilities ourself in our own models and try to patch them okay machine learning talk is mostly over we're going to move on to an application and dive into a little bit of the details about how we construct this adversarial game so just as a review that the application we're talking about today is going to be
detecting uh DGA so uh domain generation algorithms used by malware to call home um they they're really it's not not a fair fight because the adversary has to you know register one out of a million domains but the malware only has to success successfully connect to one of those right so it's really important to find them otherwise they'll they'll establish a C2 channel so kind of this how it works you know the um the the malware on your laptop and the the server share a key and they pseudo randomly generate a list of domain names one at a time in the same order and the the malware will try one doesn't exist he'll try another
one doesn't exist and finally he'll be successful in establishing connection be able to call home what we're going to do in this talk is uh develop a model that looks only at the domain name and tries to determine whether that has been generated pseudo randomly or if that is a legitimate you know human hand-coded domain so that's that's the problem the way we're going to do this as I alluded to previously is by setting up this game of red versus blue so the blue the blue team's job obviously is to um take as as input a domain and try to tell if it's a DGA or not a DGA the red team's job is only one thing
and it's to fool The Blue Team okay so all I'm going to do is I'm going to have two models I'm going to connect them together and this is again Brute Force differentiable learning uh deep learning by uh by giving it a random seed and saying that uh what whatever domain comes out at the output I want to call that I want to fool The Blue Team and make it call it good so that's move number one by the red team train this generator to randomly generate a domain an impostor that will trick the blue team move number number two is by the blue team and he will take that impostor the the red team has served his purpose
he will feed now these impostor samples to The Blue Team who will retrain with an augmented data set with these vulnerabilities now exposed and Harden plug those holes so that's move two and we'll do this over and over and over and over again so um now I need to tell you that uh I told you that if you you know if you go home tonight and play for about a half hour you can get pretty dangerous at at creating your own Trump bot or whatever um you can do that the these these more sophisticated networks are can be hard and uh hard to train and so there's some tricks that we employ to try to make the
training simpler and one of those is a is what's called an autoencoder an autoencoder is nothing more than um a tool in which we input a domain and try to Output the same domain and it's just trying to learn the right representation for all of the domains in our data set so that it can accurately reproduce it this is if you listen to the last talk this is an example of unsupervised learning where we need no labels but we can train the weights of our model based on on just Globs of data so in this case we will train our our Auto encoder on the Alexa top 10,000 or Alexa top 1 million and it will learn an efficient
way to represent all of these domains in the knobs and dials of deep learning uh in order to correctly reexpress those after that's done we have uh we have successfully solved a key part of our adversarial problem most of the meat of this model is learning how to represent things remember deep learning is about representing things once we' solved that problem we can repurpose our Auto encoder and just add these tiny top layers the the purpose of this top layer is to transform a random seed to that same kind of representation for a domain that was learned and the purpose of this last layer is to decode a representation and and classify it as either being
pseudo randomly generated or human generated so that that's a that's one trick we we've used to uh train our so-called generative adversarial Network okay technical deep dive is is mostly over I I want to show you what I think are kind of curious results from this game of adversarial deep learning so on on the left hand side I'm showing you the results of the auto encoder so remember input a domain name try to reproduce that same domain name and it's going to make mistakes because if it didn't make mistakes we'd be overfitting and have a bad model so the top here are are uh successful examples of our autoencoder representing those domains so kayak goes to kayak and the bottom
are some I think kind of hilarious mistakes that it makes so input Gillan Anderson and output G giland Delson which is kind of cool looks kind of real but it's a completely artificial domain um one interesting thing about this we are in inputting characters and outputting characters it has no knowledge about um about English language it's learning this all from the data okay on the right hand side so this this was step one we trained an auto encoder and then we re-engineered our little Network to play an adversarial game and at the end of that adversarial game the red team has learned to bypass the blue team and these are the kinds of domains that it
generates that are totally random so I just want to impress upon you the input to this was a random seed and the output is a domain name that says fire F APS which could totally be legitimate if if one look at it again there there a lot of actually one of these ler.com is actually a register domain that was generated from just a random number which is kind of cool the point of this talk of course is not to develop a develop a DG algorithm but uh to harden our classifier um before I before I move on to that I want to compare for a moment what these uh these DGA uh domains look like compared to an actual
DJ so here here's cryptool Locker right ransomware that um here's the code to generate it but its domains look like this and if you were to look at that you could tell right away you know sort of fixed length random randomly choosing characters kind of easy for a model to tell um here's another example the Sim DGA here's here's the code to produce it fixed length kind of easy to tell some of them are clever because they you know alternate consonants and vowels but um you know I think you'd agree that sort of this list is a more compelling list of of domain names that could fool a classifier okay so in what follows I'm going to
first train not a deep learning model a totally different model a random force model to detect deep GGA domains uh deep G GGA is what we're calling these these adversar generated domains and only those so as one job detect these domains and you can see as we play a number of aders Serial games with our model its ability to detect these things decreases uh this is a by the way this is a rock curve and it's showing the a trade-off between the false positive and false negative rate so performance increases as you move to the upper left hand corner and decreases as you as you sort of shrink that curve another interesting example so now
instead of trying to detect uh you know our method and only our method let's build a general purpose classifier to detect all DGA and and might and you'll see that it can detect almost everything except with a rate of less than half it detects AR thing okay so let's let's flip this on his head now uh the all of these families by the way in this this uh plot were equally represented in the trading set what we're going to do now is Harden our classifier and add a disproportionate amount of these uh these samples we've generated to our model to try to harden it and the results were like this so before hardening we can detect um a
family we've never seen with not not very well right um by the way this this is a especially difficult example because uh while we've trained on only characters character-based DJ we're trying to detect a DGA based on that that app pins random words together from the from the English dictionary and we've seen Improvement after we've trained adversarial this is uh even more Stark when we try our classifier against a method that's like the training data that is based on characters we see it jump from an 85% detection rate to Almost 100% okay so here's my conclusion slide number one all machine learning models have blind spots and uh the the nice thing about deep learning that makes the easy to
train makes it also easy to exploit and that's the differentiable nature um adversarial examples can be shared across models and this should scare you just a little bit that if I find an adversarial example for one model as I showed you I I found it for a deep learning model and it worked pretty well against a random force model number three uh we have come up with a way to try to harden these models by playing this adversarial game and the resulting domains from that game will'll use to add to our training set to to to robustify to strengthen our model against future attacks and unseen families um the way that you play these games are are actually really hard
problems and if if there are any data scientists in the room who'd like to take a deeper deeper di I do have slides I'm not presenting to the general audience because you'd fall asleep that maybe you'd find interesting about how to um you know how to do some of these tricks uh the oneliner is that you know instead of you know instead of trying to find Optimum we're trying to find this Nash equilibrium in a game theoretic setting where there's an equal competition between generate and detector so this game theory thing makes it really hard to train so enough of that that was actually three lines I apologize last uh cool applications we can both generate malicious domains that
I think are are pretty pretty uh pretty pretty cool and we can use those domains to harden our models um with that I'd love to take your questions and thank you for having me here at
bides so for questions please
just okay there um so um going back to to the going back to Bo if I can talk today going back to each of going back to each of your iteration layers are they all equally weighted uh the layers the layers themselves those um do you mean the iterations or the layers of the model iterations the iterations uh they we we generated the same number they were equally weighted y okay um why um that's good so in the in the hardening we only used the last iteration like after the game had concluded okay those were the best that the most devious domain names came from the last round I guess how do you measure how that last was the best
um like this so um this this is a measure about how well a model can detect those when it wasn't trained on when it was trained on those and only those so it's its ability to catch them decreases as you play this game yeah okay well all right okay thanks yep you bet all right cool awesome talk um so you spoke a bit about Auto encoders to encode domains into embeddings have you tried using them for like uh other you know contexts like malware or Sim logs or anything like that yeah um we have we have tried things so we've tried I think many times unsuccessfully like HTP headers Mal works hard because they're there's big in variety but after
featuing the Mal so representing instead of a sequence of bites you know stripping out PE information for PE files whatever those we can Auto encode also to to some extent it's a good question hey hi Alex I have a question um if I understood correctly um the there was a very low detection rate on the Deep DGA because you're actually withholding the the training data that would um I mean of the things that were generated by it right um this one here yeah yeah yeah so you were not you actually had uh deep DJ represented on the training set as well was in the training set the difference between this slide and the previous slide is the
classifier is trying to catch all the things not just deep DJ so when we have a a broad defense it it has a hard time these are the sneakiest one of all of them to catch yeah even though these the training set yeah I have to look a little bit closer on how you did this generation because this is this is if if so it's this is definitely interesting this is a there 10,000 samples in every from every family equally weighted yeah in this model yeah because on the next slide you were like plus deep DGA it got me the impression that you had actually withheld the Deep DGA once the difference here it's a really good
question Alex deep GJ is not we're not trying to catch deep GGA it's not in the test set uhhuh so this is how I can catch only this family volatile that was not in the training set but I've added deep DGA to the training set does that make sense trained on I trained on all all the things all the things plus deep DGA and that allowed me to catch this family I didn't train on that's interesting okay okay now yeah this is so same thing here this is actually a really bad example CU we're still only getting 50% this is a really hard one this is pretty astounding it means that you know my my uh false negative rate
goes from 15% to almost zero because I've totally artificially created part of my data set with DDJ right so no no work except data science salary I'd be very curious yeah you didn't do a thing right uh I'm very curious to see how this impact the the false positive rate and I see the rock curve of course but uh but yeah this is this is this is really interesting I do have one I'm sorry I'm hogging the microphone I just have one more question U the especially when you say um an adversar example would be like you could generalize it over uh across different models yeah I mean assuming that people were doing the lazy thing on
deep learning where they don't actually think about the features they just hot and cod it and just feed it to anything else right it's uh it's the same the same principle right if someone actually sat down and try to to create different features and then feed them to to the thing not necessarily they would be yeah so I didn't have time Alex but this is kind of interesting I think you'll appreciate is that I used real deep learning to generate these things there there was a it learned the feature representation the random Forest that I'm using to test here was a feature handcrafted features in the manual sense which is kind of alarming to me that it turns out that
those adver sale examples for deep DJ worked against a handcrafted feature you know robust in that sense uh R of forest model yeah kind of kind of scary no no no yeah this this is yeah I didn't catch that that point as well man it's great work man congratulations hey um thanks for the awesome talk um so my question is uh also three fotes sorry that's great well the first one is that um what's what about the false negative rate yeah what I um it's a good question so all of these here were um um we we only yeah the results I've shown we're only trying to catch bad things but false negative rate is a is a
huge problem and so the only graphic I can show you today is this right so this is the kind of representation um if it's trying to cap deep GA but there is a false um The Talk today is not necessarily about that it's about hardening classifiers y I don't know right now but it's a good thing to look into how that might improve maybe the false neg the false negative rate or false positive rate yeah it's a really good question yep so so you know I've been doing this a while ago and so the second question would be um you know there's some Chinese cctld domains uh some Chinese domains with CN uh um that really looks like a DGA
domain but in in fact they're legit that's good to know um yeah um yeah puny code actually there there are Punic code and the alexop wiill that we trained on um I don't have any examples here but pun Punic code is hard for Auto encoder to represent and I imagine that the legit Chinese domains are also hard but that would be good thing to look into yeah because it's abbreviations um of Chinese pings so they really look like they even look like to my bare eyes yeah yeah yeah something like that all right well that' be a problem so the third question would be like um you said the model is PR has some vulnerabilities and do is it
getting any better if we use model oh what kind of model Ensemble Ensemble um yes but again Ensemble methods have vulnerabilities so I showed you one randomforest is an ensemble method yeah exactly so it it is prone not just to vulnerabilities but in fact some of the same vulnerabilities we discovered for a deep learning model mhm okay thank you you bet by the way I'm eating up your lunchtime I apologize minimally um so from a vulnerability standpoint if we think that models have vulnerabilities and we're continuously training um models def find them and models to um be protected against them and defended against them is it going to be like vulnerability assessment where there is always the next vulnerability
and if so are we what are we gaining by finding vulnerability in when there will always be vulnerability in plus one yeah um I maybe more of a philosophical question because um you know I don't think that anyone believes that there's one tool to catch all the bad things right yeah and kind of this layer defense is kind of back to the previous question this Ensemble of ways to catch things uh things will still get through from time to time but I think that's the way to go so um you harden the things that you have and you lots of them right so yeah and I guess more a technical question you're feeding in ultimately you using uh byrams uh to
represent the domains for that was just the shallow learning so that okay what were you using for a good question so what we did is we uh we allowed the Deep learning model to choose a representation in 20 dimensional space for every character okay and it it learned everything else okay so you're feeding the characters in like one by one yeah we feed it an integer that represents a character yep okay so okay yep thanks Gabe can I dismiss people to lunch
yes
Related talks
 26:12
26:12 57:27
57:27 37:33
37:33 50:08
50:08 56:42
56:42 13:00
13:00