BSides Warsaw 2017 Friday

Show transcript [en]
Okay, let's start. So, good morning. Very early, early. Yeah, filling in, so trying to keep it mostly brief. Hopefully the actual speaker will show up not too long from now. Apparently there was some talk about the difficulty in recording conferences, which as it so happens, I know a thing or two about. So I am a software engineer in regular life. I have a full-time job with that. But on top of that, I also record conferences. And I've been doing them throughout for the past two years, just quite literally everywhere. I've been in England, Singapore, India, but also I do pretty much all the B-Sides conferences in Europe, at least the ones that allow recording. So yeah, I know a thing or two about this. So what does it actually
take record a conference. Not a lot. This is a conference that is being recorded. What you're seeing down there is a smartphone on a tripod. Boom, you're done. You're recording a conference. It really can be just that simple. The wire that you see coming here from the side leads to a power pack so that thing lasts long enough. But yeah, that's it. You got audio, you got video. If you position it properly to also look at the screen, you're also capturing the slides, you're done. But of course, you want to do nicer, if at all possible. So, we improve audio. Now, most, not all, but most conferences have one of these lovely things, a mixer and microphones and such, and you want to plug into
that. All these things work off of something called XLR. It's a three-pin connector and you plug that in over there. And IronGeek uses something that is a bit mangled together whereby the balanced audio coming from here is actually possible to be understood by the microphone input of your computer. So you need a little bit of gizmos for that, but it's like 10 bucks 10 euros to put that together and you can take in the actual pro signal you get from a mixer. Failing that I also usually go to conferences with a small microphone that just plugs into there and does everything. In this particular instance I'm actually using, it's the cigar shaped thing over there, it's on one of the later images that I will show you. This one
has the downside of the left input being the left channel and the right input the right channel of a stereo bit and I was I only plug in on plug in one side so I use software to make that mono signal actual stereo again but that lowers the volume a bit but now things you solve Getting the video. So there are in effect two video sources. There's the camera, obviously, and the laptop's slides. You want to capture those individually. That is at least the way to get it nicer, because if you have the smartphone just looking at the screen, it'll be fairly faded. And sometimes, particularly when you have something like red text over a black background, that tends to be really difficult to
pick up. So you want to have a direct feed off of that. The way we do it is you have the image coming off the laptop. Usually you decide on a format. My advice would be just to go with HDMI. There are really cheap, like, five-year-old splitters on AliExpress. Split them up. One side goes to the projector. The other side goes to you. And you feed that into one of these things. Top left is an Elgato. IronGig uses that. Does full HD, I think, but at a low frame rate, meaning that if you have a upscale laptop, that thing won't be able to capture it, won't be able to understand it. The one on the right is an AVRMedia.
It is USB 3.0, so it has enough bandwidth. That's the problem with the El Cato. It's USB 2.0, so not enough bandwidth to take a full HD image for the full 50 to 60 frames a second. So the AVRMedia does not have that problem. I use the thing on the bottom, which is a Magewell Pro Capture USB. It's a USB thing again. You'll notice that it only has a hole on one end, and I will get to that in a moment, because I use... The top two, you just plug in an HDMI cable, and everybody has an HDMI cable. The problem is, in my opinion, with HDMI cables, once you make them long, they really quickly break. And you'd be like, well, it worked
like five minutes ago, like on the same setup, and all of a sudden it's like, sorry, no. So I use this. This is STI. It's basically digital coax. Hopefully a lot of you people know it from the old days, 10-bay-C and all that, and network-y bits. I use the connector on the right. The left one is for fairly new kit, which, as it happens, is close to, but not identical, what that USB thing was using. So moving on. I captured one of these. The USB thing, again, it has a
small connector, it's MCX, to the SDI connector, which is that thing. You might think that the card on the top has two inputs. It does not. The top one is the input, and the bottom one is the output. Again, it loops the signal so multiple devices can stand in tandem. Yeah.
sad part is these things are kind of pricey they're about 300 euros each so um and well you need two um
let's not go there just yet um so you need two um the i feed everything of into a pc um that's why i'm using pcie cards if you want to use a laptop you already like you need to use usb devices just by default. I chose not to do that, to go the laptop route. IronGeek does, I don't. Mainly because I need the horsepower of a really full-powered CPU and the mobile devices just can't keep up with the way I want to record my things. So one of the things I do, you will notice with the camera over there that it's tilted, I'm filming in portrait. And for one, the camera itself doesn't like that, but
the reason I do this is if you look at my streams, you will notice that the camera section is a small vertical bit.
Knowing that, you can either film in landscape and cut out the section that you need, by which you would then throw out a fair chunk
of the data provided to you by the camera sensor. By tilting it, you can use the full sensor, so you get more image data put in. If you then downsize that and denoise it a little bit, you get really nice, smooth images, as opposed to, because, This is a not particularly expensive camera and before this I was using quite literally the cheapest HDMI camera you can find, which is about 200 euros-ish. Those things make a lot of noise. So there's speckling going on and as a result your video compresses really poorly and it kind of looks very busy even at times when there's nothing going on, particularly when you have a black background. So if you just
tilt the camera, you get just a better image. One of the things I used to do before to do that was to use a 3D printed mount, and that had the downside of breaking. By the way, if you have a chance, avoid Charles de Gaulle Airport, because no, I went through there and two of them broke. I don't know, they throw with your suitcase or whatever. Combining it all, usually when I go with my so-called fixed setup, you get this. Full-on PC. Yeah, it's big, but this is, so as a result, this is what I use when I just drive to places. Yes, I did drive from Apple in the Netherlands to Warsaw. Took two days. But...
It's compact enough. I have four of these fixed things and I have an additional three mobile, which I'll show in a picture later. And
I can fit all six of those in the boot of my car and it'll close and it'll look nice and no problems. So let's quickly go over the screen. The B-Size logo that you see here, because yes, this image was just taken. This is OBS, that's the logo. That's what I used to record the combination of everything. But just in case, I have those four little externs here on the top, which individually record the camera, the laptop, the audio and another, there's a third capture card in there because redundancy. So even if OBS were to fail, I still have everything I need to combine to make a proper video. Because the one mistake that people tend to make
when I'm using multiple setups, I have volunteers operating the thing, they need to tell it to start recording, to stop recording. And people forget, or they're just too late, or whatever. So I can just go to the separate recordings I make, combine everything, and done. Obviously when OBS does everything, it's much, much faster to edit in the end, but yeah. So the mobile thing looks like this, and most people would find this kind of scary. The audio thing is that thing over there. Here you have that capture card. There's another one near it, but I don't see it right now. What you basically have is the PC without the box. I ask venues to provide me
with the power supply unit because it's bulky and heavy, hence not very nice for planes. I ask them to provide the tripod because it's, again, so big it's difficult to bring with you. And usually also ask them to provide the screen. In this particular case, it happens to be my own.
record everything on SSD which is there because of weight not because you need the speed because you really don't. Yeah, put it all together, throw it online and yeah, Bob's your uncle. So that's kind of what I think I wanted to say. Yep. Because I had to keep it brief. I hope this was sufficiently brief. Angelica.
So are there questions? The best question? Well, the best experience I had involved the HackerCon t-shirt. So I have from the Nolcon conference, I have this really cool t-shirt that has some scribbles at the front. And people always are first assuming like, oh, this looks Arabic or something. Maybe he's a terrorist. It reads hacker phonetically in Hindi.
So I'm there at an airport in India for Nolkong Goa. And over there, airport security is of the type where they basically need a reason not to shoot you. And I'm standing there waiting for the guy with the wand to do his thing. So he's standing like that. And he does, zzzm, zzzm. Hacker. Awesome. So yeah, and I also didn't like the fact that my suitcase at that point, so Nolkongoa is three tracks, so I needed to bring three rigs. I can fit two in a single Pelican, but the Pelican that is the size of carry-on luggage, which is great for each of you who doesn't care about the weight, because this is, I think, 28 kilos.
in that. It's like a big hunk of metal, basically. So when I tried to take that through, when I went to India, I had everything in a regular suitcase. And that thing weighed 36 kilos coming in. Coming back, I took a few bottles of booze. I mean, hey, tourists. So yeah, hey, I do am human. So yeah, all of a sudden it was like too heavy and you needed to take something out. So of all the gizmos you see down here which do all sorts of conversions to go from whatever the laptop provides to HDMI and the capture cards and the sound capturing thing is in there. Again, just a big heavy little box of metal and try to take that through security and
as a separate thing now, as carry-on, and going to the security booth, it's like, yeah, I don't think you want to put this through the machine. Oh, no, no, no, no, it'll be fine. Okay, okay, I warned you. So they put through it, yeah, the thing blinks, and it's like, yeah, I think we're going to have to inspect that. Yes, I think you do. Anymore?
how many gadgets do you have with you every time you go? What was the second question? What's the typical compatibility issue that you have with all sorts of mixers, cables? I usually have problems with old MacBooks because for some reason they have a frame rate in their output to HDMI that is not standard. And as a result, what I get is like, smooth image, hey, nothing. Smooth image, hey, nothing. Which is really annoying to fix. What often also happens is that people show up with a laptop going like, yeah, this thing only does VGA. And in 98%
of situations, the only thing they ever worked with was VGA. But there is a plug for something else. The only exception is that thing, which actually
Genuinely only as VGA. Oh, and at Hardware.io, which was last September, there was a guy who coming up with a laptop which was suitably ancient, it ran XP.
So quick fix. Yeah, that doesn't often happen. Now, audio-wise, things tend to be easy. The main problem is the combination of whatever the laptop provides getting that in and the compatibility of the projector, which tends to be kind of lacking. This particular one, for instance, we're now feeding at 720p, whereas everything here tends to be 180p. Yeah, so that's the sort of thing you need to fix. Just noticing that this machine is making noise, which is probably because I'm looking at the live stream. Oh yes, we're doing live stream. It's a default feature of OBS and highly recommended. Anything else?
Okay, the last one. How do you max all the videos, combine them? When you stream, do you... mix all the videos at once or then and then you don't edit the video afterwards or you edit the videos afterwards I don't know I do both so first of all when you live stream that is literally just a very long video and that goes straight to YouTube and I don't touch it anymore because one of the things YouTube uses is it compresses the video this is also sort of required because the video I produce here is about 10 megabits a second and If you were to look at that, view that on your mobile or whatever, A,
it would eat through your bundle like you wouldn't believe, and B, you'd need a fairly quick connection to be able to smoothly view that. So instead, what goes to YouTube is theirs, but I also store locally. And when I'm not live streaming, the thing that I'm storing locally is the exact same thing that I'm streaming. And the only thing I have to do which is for myself just to make it easier to edit later, is I tell OBS to, in between talks, I say, okay, stop recording, start recording, makes a new file, and then the file that is made, I can then quickly go and like, cut here, cut there, clean up the audio, done. To go from a recording to an actual video that
we later publish on YouTube takes about five minutes,
Chwila na to aż przepnie się pan Litwin, zapraszamy go.
Минутка, я с тобой.
Ok, dzień dobry. Bardzo przepraszam za spóźnienie. Niestety okazuje się, że taksówki mogą zawieźć nawet w Warszawie. I to piekielnie. Pewnie część Państwa mnie pamięta z zeszłego roku. Ja nazywam się Mariusz Litwin. W zeszłym roku również mówiłem o Bitcoinach. Różnica polega, znaczy moim zdaniem różnica jest radykalna, ponieważ gdy w zeszłym roku dopiero hobbystycznie interesowają się tematem, to jak zwykle, gdy życzymy sobie czegoś, to bardzo szybko dostajemy to w formie, która nie jest do końca akceptowalna. Od zeszłego roku miałem okazję popracować nad Bikoniem trochę praktycznie, plus też jakby moja fascynacja zaowocowała większym ilościem przeczytanego materiału, większym przygotowaniem. Mam nadzieję Państwu dzisiaj opowiedzieć troszeczkę o ostatnich zmianach. Jeżeli coś będzie niejasne, to proszę o pytania na bieżąco, ponieważ nie obiecuję, że będę
miał możliwość odpowiedzieć na nie na samym końcu oraz że będę w kuluarach zaraz po mojej prezentacji. Postaram się wrócić, jak tylko obowiązki służbowe mi to umożliwią. Teraz zanim zaczniemy to chciałbym określić pewną jakby kłopotliwą kwestię. W tym momencie jakby mówiąc o Bitcoinie ciężko jest mówić, o którym Bitcoinie mówimy. Jest ich co najmniej dwa, niedługo będzie co najmniej trzy, a niewykluczone, że w pewnym momencie pojawi się co najmniej cztery. Kiedy ja będę mówił Bitcoin, chyba że powiem inaczej, to mam na myśli wersję Core. czyli tą, którą mamy od 2009 roku mniej więcej stycznia. Nie mam na myśli Bitcoin Cash, nie mam na myśli nowego fork'a nadchodzącego, mam na myśli po prostu klasycznego Bitcoina. Jednak, tak jakby Bitcoina
można rozpatrywać na wiele sposobów. Punkt pierwszy to jest jakby ten wymiar ekonomiczny, prawdopodobnie dla tutaj zgromadzonego gremium odrobinkę nudniejsze. Niezależnie od tego jakby ilekroć rozmawiam z ludźmi, którzy są mniej lub bardziej techniczni to spotykam się z bardzo skrajnymi opiniami. Niektórzy mówią, że Bitcoin jest pieniądzem przyszłości i to ten konkretny Bitcoin. Nie pieniądz oparty na blockchainie, tylko ten konkretny Bitcoin. Kiedyś pozwoli nam zostać miliarderami, jeżeli ktoś w tym momencie ma Bitcoiny. Kiedyś tylko nim będziemy płacić. Z drugiej strony pojawiają się osoby, które mówią nic nie wyjaśnia tak radykalnego wzrostu Bitcoina i Moim zdaniem to jest bańka spekulacyjna. Jednocześnie spotkałem się z opinią, że Bitcoin jest dla cyfrowego pieniądza tym, czym dla lotnictwa był pierwszy samolot dla C-Ride.
Idea piękna, piękna realizacja, niezależnie od tego, no tak jak wiemy pierwszy samolot za daleko nie poleciał. Też bardzo często spotykam się z taką zabawną sytuacją, kiedy kiedy rozmawiam z ludźmi szczególnie nietechnicznymi i mówię no cóż, tak jakby inwestycja w Bitcoina, bardzo ciekawa rzecz. To oni mówią no dobra, ale w co inwestujemy? Czy ja po prostu dostanę plik, który gdzieś tam, to tak jakby chciałbym od razu powiedzieć, nie. To wszystko odpiera się na pewnych regułach, których niestety z braku czasu nie przytoczę. To jest zmienia faktu, że nie chodzi o kupowanie plików. Niezależnie od tego od 2008 bodaj listopada, kiedy został opublikowany white paper, czy też od stycznia 2009, kiedy powstała pierwsza implementacja klienta protokołu. Tak jakby Bitcoin przeszedł drogę
od nowinki technologicznej, od czegoś czym interesowałem się może ja i moi koledzy na Politechnice do rzeczy, o której mówi się w zasadzie co tydzień. Czy to ze względu na to, że coś się w sieci dzieje. Czy ze względu na to, że Bitcoin bije kolejne rekordy, jeżeli chodzi o cenę. Bo jeżeli chodzi o cenę, Moim zdaniem jest w tym momencie imponująca. Jeszcze niedawno była powyżej 5 tysięcy dolarów. A to na co warto zwrócić uwagę to, że jeszcze na początku tego roku była poniżej 2 tysięcy. Jednak tak jakby ciężko jest mówić o tych liczbach, kiedy nie ma się jakiegoś odnośnika. Kiedy nie patrzymy w pewnej perspektywie. Kapitalizacja Bitcoina o ile liczbą jest ogromną to na przykład bardzo słabo wypada
w kontekście Apple'a. którego kapitalizacja jest na poziomie 800 miliardów. Jednocześnie jeżeli porównać aktualną, mam na myśli kapitalizację
wszystkich akcji notowanych jako Apple. Jednocześnie Bitcoin bije Adobe, Netflixa, od niedawna American Express. Więc mówimy tu już o sile, która w jakimś stopniu jest
jest warta uwzględnienia. Teraz mam nadzieję, że ten wykres będzie czytelny, ale pokazuje to, co chciałem właśnie powiedzieć. Bitcoin w 2013 roku miał swój pierwszy sukces. To znaczy był notowany powyżej 1000 dolarów za jednego Bitcoina. Potem mieliśmy radykalny spadek. Nie będę wchodził w detale dlaczego tak mogło być. Możemy porozmawiać o tym później i dywagować. Niezależnie od tego w tym roku mamy radykalny wzrost. z poziomu w zasadzie poniżej 1000 na początku roku. W tym momencie mówimy o 5000 dolarów za jednego Bitcoina. Oczywiście pytanie jest, czy będziemy od tego punktu rośli w górę, czy spadali w dół. Niezależnie od tego moim zdaniem świadczy to o radykalnym sukcesie. O tym, że Bitcoin przestał być też taką technologiczną nowinką świadczy też fakt, że To jakby ważne osoby
ze świata finansjery wypowiadają się o nim. I oczywiście te opinie są bardzo spolaryzowane. Niedawno Jamie Dimon, czyli prezes JP Morgan bardzo krytycznie wypowiedział się na temat Bitcoina, mówiąc, że to jest bańka i że każdego tradera, który używałby w swoim portfelu
Bitcoinów bądź ogólnie kryptowalut wyrzuciłby z pracy za niekompetencje. Przy czym on chyba ujął to w ten sposób, że wyrzuciłby go za głupotę. Co jest dość mocnymi słowami. Jednocześnie jakby z drugiej strony Lloyd Blankfane, przepraszam, nie jestem najlepszy w nazwiskach, czyli prezes Goldman Sachs. Co prawda nie wyraził wprost, że jest bardzo zainteresowany Bitcoinem, uważa to za pieniądz w przyszłości czy cokolwiek, co nie zmiana faktu, że stwierdził codziennie myślę o Bitcoinie i zastanawiam się w którą stronę z tego punktu pójdziemy. I ujął to w taki dość zabawny sposób, kiedy stwierdził że kiedy ludzkość przechodziła ze standardu złota na pieniądz papierowy to też wszyscy uważali, że coś tutaj śmierdzi. Więc tak jakby mamy mocne spolaryzowanie świata finansjera, ale też to spolaryzowanie widać w polityce różnych
państw. Kiedy pojedziemy do Szwajcarii Bitcoin jest wszędzie. Miałem przyjemność kupić Bitcoina w bankomacie szwajcarskim w ten sposób, że po prostu włożyłem euro, a wyciągnąłem portfel w formie klucza prywatnego i publicznego. z jakąś tam doładowaną kwotą. To akurat było wtedy, kiedy były odrobinę tańsze. Takich bankomatów na przykład w USA działa ponad 1000. Łącznie chyba na świecie jest ich około 2000.
W Polsce, w Warszawie są dwa bodaj. A tylko w Warszawie. Polska nie zaadaptowała się najlepiej do tego jakby technicznego trendu. Jednocześnie według IRS amerykańskiego Bitcoin podlega odpodatkowaniu jak każda własność. Czyli został rozpoznany.
We wrześniu tego roku, to zresztą było bardzo widoczne na wykresie, który pokazałem, mieliśmy bardzo duży spadek wartości Bitcoina. Związane było to z tym, że chińscy regulatorzy rozpoczęli, znaczy nikt nie powiedział tego wprost, ale rozpoczęła się pewna kontrola tego jak Bitcoin ma działać i w jaki sposób będzie wykorzystywane w państwie środka. Zaczęło się od tego, że na pewno zakazano tam tak zwanych initial coin offering, czyli czegoś w stylu funduszy inwestycyjnych w ramach kryptowalut. By niedługo później na tyle zacząć regulować giełdy, że cóż zaczęły się one bardzo szybko zamykać. Bitcoin niezależnie od tego przetrwał jakby ten to zawirowanie. Co nie zmienia faktu, że to też pokazuje pewien trend. Ostatni z punktów, który chciałem pokazać jest moim ulubionym, ponieważ w Wenezueli, która jak
wiadomo jest teraz w dość w tym głębokim kryzysie finansowym, mimo że Bitcoin formalnie nie jest nielegalny, to znaczy nie ma żadnych zakazujących go praw, to kopacze, którzy w celu jakby utrzymania swojej rodziny, w celu zarabiania na życie w formie cyfrowych walut, to gdy zostaną oni przyłapani, to zostają aresztowani za kontrabandę i kradzież prądu elektrycznego.
Wracając na chwileczkę do Polski. bardziej do Unii Europejskiej. W Polsce nie ma żadnej legislacji, która jednoznacznie wypowiadałaby się na temat tego czym jest Bitcoin. Na pewno transakcje z nim są zwolnione z VAT-u. Ale na przykład Unia Europejska bardzo aktywnie działa, żeby podpiąć kryptowaluty pod czwartą dyrektywę przeciwko pełeniu brudnych pieniędzy. To znaczy, że jakby rozpoznany jest ten problem, że Jak to się kiedyś popularnie mówiło Bitcoin jest walutą przestępców. Co oczywiście też nie do końca jest prawdą, bo na jakby kanwie tego wzrostu świadomości tego fenomenu, czy też wzrostu dojrzałości operacji w ramach takiej sieci wiele giełd jakby podchodzi do tego tematu już coraz bardziej odpowiedzialnie. Większość europejskich giełd na przykład jest zobowiązuje się wobec pira z okoł właśnie tej czwartej dyrektywy ML-owej i dba o procedury
KYC, czyli Know Your Customer i AML, czyli Anti-Money Laundering. Jednocześnie pojawia się mnóstwo firm, które tego typu problemami się zajmują. Ja pozwoliłem sobie wylistować ich kilka, oczywiście googlując bardziej można by znaleźć więcej. Z częścią z nich miałem okazję pracować, więc Też mam nadzieję Państwu pokazać jak taka usługa działa w praktyce. W tym celu przygotowałem sobie adres, który znalazłem w internecie. Nie jest on w żaden sposób złośliwy ani nieprzyjemny. Co nie zmienia faktu, że posłuży mi za przykład.
Ponieważ w Internecie istnieją, przepraszam, czy wszystko jest widoczne na ekranie, bo mam wrażenie, że jest troszkę wyblakły tak patrząc z tej perspektywy.
Pierwszy z nich o bardzo wdzięcznej nazwie Bitcoin WhoisWho. Pozwala nam co do zasady zidentyfikować znane portfele. Jak to się dzieje?
Oczywiście tak jakby technik wiążący, pozwalających wiązać podmioty jakby z życia naszego codziennego z tym wirtualnym bytem bitcoinowym jest multum. Mówimy tutaj zarówno o crawlowaniu różnych fork, mówiących o tym, że pozwalających zidentyfikować na podstawie metadanych właścicieli danych adresów, ale też na przykład o klastrowaniu adresów i tym podobnych. W tym momencie jakby z uwagi na to, że chcę zidentyfikować ten adres, no to chciałbym wrzucić Bitcoin WhoisWho i o ile nie ma tutaj rozstrzygającej informacji, mówiącej kim jest właściciel tego adresu, to prawdopodobnie to jest nieczytelne. ale mamy informację, że ten adres pojawił się na stronie xkcd.com.oneprz.bitcoin. Tak, chodziło o Randall'a Monroe, przy czym jest wdzięcznym tematem, ponieważ jego portfel był dość intensywny i dość długo używany. Zależnie od tego,
gdy już… Słuchaliście mnie w tym momencie, przepraszam? Bo ja na chwileczkę muszę odłożyć mikrofon.
Dobrze, to spróbuję jedną ręką. Dziękuję. Niezależnie od tego przy analizie, przy analizie niekiedy przydają się inne sposoby spojrzenia na
ten problem. że nie była celowa złośliwość, skończyłem myśl. I moim zdaniem tutaj bardzo pomaga analiza za pomocą grafów. Ten sam adres mogłem wpisać w ramach Blogsir, to jest ciągle darmowa usługa. I klikając tutaj w zasadzie byle co, nie jest to najbardziej intuicyjny interfejs. Mogę zacząć wizualizować sobie sieć powiązań między moim adresem, czyli tym 14TR4, a jakimikolwiek innymi.
Myślę, że nie ma co przedłużać i od razu pokażemy, że jesteśmy w stanie zidentyfikować powiązania między XKCD, a mam na myśli tutaj wiele różnych portfeli, które Renald Monroe używał w różnym okresie czasu. I jak to się rozchodziło w sieci, gdy już te co ojny wydawał. Ostatnia usługa, którą chciałbym Państwu pokazać, ona już nie jest darmowa.
Firma Chainalysis jest ogólnie liderem na rynku takich usług KYC, EML i tym podobnych. I ich narzędzie pokazuje dlaczego tym liderem zostali, ponieważ bazując na tym adresie nawet niekoniecznie muszę cokolwiek rozwijać, ponieważ ona, ponieważ sama ta platforma pozwala mi na przykład sprawdzić
skąd te pieniądze się wzięły, wzięły przepraszam, w taki dość wygodny sposób. Widzimy, że mieliśmy tu pewien wpływ z kopania bitcoinów. Jednocześnie gdzie one się podziały. Jeżeli interesuje nas gdzie dokładnie to wiemy, że na przykład Coinbase. Oczywiście teraz dorysowane zostanie dość oczywiste powiązanie.
Jednak Bitcoin to nie tylko ekonomia i nie tylko takie fajne narzędzie, ale też jakby pewne techniczne wyzwania, które stają przed autorami całego tego pomysłu.
Tak oczywiście. Potrzebujemy wrócić do
To znaczy pytanie dotyczy, czy można zostać anonimowym w ramach sieci Bitcoin. I teraz odpowiedź jest i tak i nie, ponieważ to wszystko zależy od tego jak my podchodzimy do tej sprawy. Jest zbiór pewnych takich zasad higieny związanych z Bitcoinem. Pierwszym z nich jest, żeby nie wykorzystywać tego samego adresu dwa razy. Czyli kiedy wysyłamy jedną płatność to wykorzystujemy ten adres i już nigdy do niego nie wracamy. To jest zresztą wbudowane w większość portfeli. Drugi problem jest taki, że większość portfeli kiedy już ma, powiedzmy, że płacimy pierwszy raz zostaje nam troszkę reszty, która trafia na jeszcze jedno osobny adres, który nie jest powiązany z poprzednim. Drugi, trzeci, piąty. W pewnym momencie okazuje się, że mamy zgromadzone na przykład sześć adresów. Na
których są pewne niewielkie kwoty, a my chcielibyśmy zapłacić całość. Oznacza to, że wszystkie te adresy muszą uczestniczyć w tej transakcji. to znaczy będą identyfikowane jako wejście. Teraz w takim wypadku w większości przypadków wystarczy, że zidentyfikowany zostanie jeden z tych adresów. Na zasadzie należy do Pana albo należy do mnie i skompromitowane zostają wszystkie.
A takie powiązania nie muszą być wcale oczywiste. Spotkałem się bodaj ostatnio oglądałem prezentację, gdy Niestety nie zapomniałem nazwę grupy, która się tym zajęła, ale bardzo szczegółowo przeanalizowała przypadek włamania do MT-GOX, znaczy serii włamań. I oni tam pokazali taki dość oczywisty, gdy się już o tym pomyśli, ale tak jakby zaskakujący przykład, kiedy skanowali support forum MT-GOXa, czy też innych giełd pod kątem wiadomości pod tytułem, nie wiem, 5 bloków temu wysłałem transakcję na 0,0132567
bitcoina i ona jeszcze dotąd nie została potwierdzona. Czy moglibyście to sprawdzić? Na podstawie tych metadanych możemy się troszeczkę cofnąć w czasie i zobaczyć czy taka transakcja i kiedy została wysłana, z jakiego adresu. To pozwala nam skompromitować ten adres i wszystkie z nim powiązane w ten sposób, w którym powiedziałem.
Ok, tutaj może powtórzę pytanie, czy to był może błąd ludzi, którzy jakby tworzyli Bitcoina, że jest ich ograniczona ilość, czy to było raczej na tyle inteligentne, że przez to teraz Bitcoin staje się takim dobrym jak złoto, że jest jego ograniczona ilość i przez to wartość Bitcoina nigdy nie będzie spadała, bo tak jak złoto, nigdy nie będzie spadała, bo jest po prostu jego ograniczona ilość, a chętnych jest coraz więcej. Czy, no nie wiem, czy jest jakieś takie… Nie wiem, ktoś to analizował na zasadzie, czy to było mądre, czy to niemądre było podejście na zasadzie. To znaczy ja nie jestem ekonomistem i nie chcę, żeby moja opinia była brana jako opinia wiążąca, jeżeli chodzi o takie kwestie właśnie czysto ekonomiczne. Bitcoin z założenia jest walutą deflacyjną,
co moim zdaniem stoi trochę w opozycji do tego, jak zostało pisane w tym oryginalnym white paperze, czyli jako Electronical Money. Electronical Cash, tam było takie określenie. Musimy jakby rozróżnić sytuację, kiedy mówimy o pieniądzach, którymi płacimy codziennie, o których nie chcemy, żeby były deflacyjne. Japonia bardzo długo z tym walczyła, ponieważ z jakby deflacyjnego charakteru ich waluty wynikał bardzo duży problem dla ich ekonomii.
A jakby środkiem, w którym przechowujemy wartość. I teraz porównanie do złota jest bardziej trafne niż do tej waluty, o której powiedziałem wcześniej. Czy ostatecznie Bitcoin takim złotem zostanie? O ile wiem większość biznesów, które zajmują się adaptacją Bitcoina, które zajmują się Bitcoinem w ramach swoich, nie wiem, portfeli inwestycyjnych i tak dalej i tak dalej. Jednak oczekuję tego, że ostateczna formuła to będzie jednak waluta, którą będziemy płacić codziennie bądź przy różnych okazjach. Nie jako sposób przechowywania wartości. Co oznacza, że ta deflacyjna natura nie jest zbyt odpowiednia dla takiego charakteru Bitcoina. Z drugiej strony nie jest wykluczone, szczególnie w kontekście nowości, do których chciałbym wrócić za chwileczkę, że Bitcoin tak naprawdę okaże się tym przechowywaniem, tym sposobem przechowywania wartości dla tak zwanych rozwiązań drugiego protokołu, to
znaczy znajdujących się nad blockchainem. Albo okaże się, że Bitcoin będzie złotem dla codziennej gotówki Litecoina. Oczywiście tutaj nazwa jest czysto z głowy i na potrzeby chwili. Myślę, że ogólnie tak już abstrahując od mojej prezentacji, która jest skupiona na tym, o czym czytałem najwięcej. Nie powinniśmy traktować kryptowalut jako tej jednej kryptowaluty. Oczywiście ona ma największą kapitalizację, odniosła nazwijmy to największy sukces. Co nie zmienia faktu, że w międzyczasie powstało wiele różnych, które oferują większą anonimowość jak Monero, które umożliwiają większą elastyczność jak Ethereum. Czy wiele innych ciekawych zastosowań jak na przykład Namecoin, który pozwala rejestrować nazwy pi razy oko DNS w ramach blockchaina. Więc czy w kontekście Bitcoina ten deflacyjny charakter jest wskazany? Zależnie od tego jak to się potoczy.
Okej, ale tak jak wspomniałem niezależnie od tego, że Bitcoin mierzy się z pewnym jakby ekonomicznym wymiarem samego siebie to istnieje też szereg problemów technologicznych bądź jak za chwileczkę pokaże problemów wynikających z jakby governance modelu tworzenia Bitcoina. Pierwszym i chyba największym najczęściej odmianym przez przypadki problemem Bitcoina jest jego skalowalność. Ponieważ przy, znaczy być może zmieni się to wraz z adopcją Segregation Witness, o którym zaraz powiem, ale generalnie takie luźne estymacje odnośnie ilości transakcji na sekundę dla Bitcoina to są 3-4 transakcje. Wynika to z tego, że blok pojawia się co 10 minut i
W dużym skrócie może zawierać tylko jeden megabajt danych. To oznacza, że tych transakcji zmieści się tam skończona ilość. A to oznacza, że w czasie jednej sekundy możemy obsłużyć tylko trzy lub cztery z nich. Przykładowym Ethereum, którego przykład już podniosłem takich transakcji można zrobić dwadzieścia, ponieważ bloki pojawiają się znacznie częściej, chociaż są troszeczkę mniejsze. Jednak Te liczby nie jak się mają do tego jak działa nasz dzisiejszy system jakby wymiany walut, ponieważ PayPal obsługuje takich transakcji 193 na sekundę. Oczywiście to jest pewna średnia jestymacja, co zmienia faktu, że widać, że jest to jakby parę rzędów wartości więcej. Jednak wszystkie te trzy nie jak się mają do na przykład wizy, która w ramach kart obsługuje ich ponad półtora tysiąca.
Oczywiście tu też jest duża różnica, ponieważ gdy Bitcoin wymaga wypchnięcia takiej transakcji, znaczy pokazanie, że taka transakcja miała miejsce, to płacąc kartą tylko udostępniamy możliwość zapytania banku, czy można ściągnąć z naszego konta daną kwotę. Niezależnie od tego, jeżeli mamy mówić o jakby Electronical Cash liczby coś mówią. I teraz ten problem próbowano adresować na wiele różnych sposobów, co zresztą podzieliło bardzo społeczność. I o ile do niedawna mówiliśmy o dość spójnym jednym kliencie Bitcoin bądź o jednej jakby wzorcowej implementacji, na której wszyscy się opierali, no to w tym momencie to nie jest wcale oczywiste. Do sierpnia 2015 podejmowane były różne próby jakby standaryzacji protokołu w ten sposób, żeby zwiększyć tą skalowalność. Usunięto z sieci malutkie transakcje, mówię o tu
naprawdę niewielkich transakcjach, kiedy jeden Satoshi, który wspominam to jest inaczej, jeden Bitcoin to jest 100 milionów Satoshi. Więc tak małych transakcji nie można już wykonywać. W pewnym momencie w wyniku takiego dość dużego fluodu małych transakcji, wszystkie kopacze i fullnody zdecydowały się, że okej, od teraz pójdźmy w maksymalny rozmiar broku dopuszczony przez system, czyli jeden megabajt, a potem było już tylko gorzej. Ponieważ jeżeli chodzi o skalowanie to można to robić prosto i być może skutecznie albo w pewien bardziej zaawansowany sposób, ale to wymaga czasu i przemyślenia. I bardzo często w historii Bitcoina pojawiali się ludzie, którzy mówili jeden megabajt nie wystarczy, zwiększmy do dwóch, albo zwiększmy do czterech, albo zwiększmy do ośmiu. Z drugiej strony ten core'owy zespół, te bodaj dziesięć osób, które pracuje nad
wzorcową implementacją klienta Bitcoina mówiło nie tędy droga, tak jakby spróbujmy to zrobić mądrzej, spróbujmy wprowadzić segregation witness, spróbujmy przenieść wszystko na drugi nad blockchain, tam spróbujmy się skalować, ponieważ jakby zwiększanie wartości bloku oczywiście pomoże krótkofalowo, jednak niedługo później zostaniemy znowu z zapchanymi blokami, i blockchainem, który waży już nie gigabajtach, ale być może terabajtach. I no cóż w tym roku szczególnie podniosła się dyskusja tak jakby gdzie powinien zmierzać Bitcoin. Jedna z dróg to był Segregation Witness i to była droga, którą proponował Core Team. Druga droga to było powiększmy bloki i tutaj za tym rozwiązaniem optowali głównie duzi kopacze. W sierpniu zgodzono się, że wprowadzony zostanie segregation witness na zasadzie user activated software, soft forku, to znaczy mniej więcej tyle, że dopiero gdy zgodzi się 95% sieci
to ta zmiana zostanie uznana za obowiązującą. W międzyczasie obowiązujące będą obie wersje, to znaczy zarówno stara jedno megabajtowy rozmiar bloku z podpisami w ramach
z podpisaniami związanymi z transakcjami wyjściowymi albo segregation witness, czyli podpisy poza. Do tego za chwileczkę wrócę. I wydawałoby się, że wszystko byłoby w porządku, gdyby nie to, że w tym samym sierpniu tego roku pewna grupa deweloperów stwierdziła niezależnie od tego co Wy robicie, niezależnie od tego jak Wy rozwijacie Bitcoina, mamy zupełnie inne zdanie na ten temat i aktywujemy hard fork. To znaczy de facto wydali alternatywnego klienta i powiedzieli od tego czasu, ktokolwiek chce być z nami, to niech zainstaluje tego klienta i my tak jakby idziemy drogą 8-megabajtowego bloku.
Gdy wstępnie jakby była pewna dyskusja odnośnie tego, który z tych blockchainów jest teraz obowiązujący, no to w tym momencie liczby przemawiają za Bitcoin Core'em. Niezależnie od tego byłoby zbyt piękne, gdyby w ten łatwy sposób osiągnęlibyśmy konsensus, ponieważ kopacze w tym momencie optują za kolejną zmianą, która prawdopodobnie będzie hard forkiem. Ta zmiana mówi ok, aktywowaliście segregated witness, ale my i tak chcemy większego bloku. Więc w listopadzie tego roku zapowiedzieli wydanie kolejnego klienta, który to znów będzie zawierał zawnątrz segreality witness, jak i powiększony blok. Gdzieś tam na horyzoncie jeszcze pojawia się Bitcoin Gold, który do końca jeszcze nie określił co chce zrobić oprócz tego, że chce ukrócić kopanie za pomocą dedykowanych układów, czyli ASICów. I znowu oni chyba mówią coś o grudniu, ale nie
jestem pewien. Czyli tak jakby konsensus w sieci jest stanowczo nie zachowany.
Ja osobiście optuję jakby za tym rozwiązaniem Segwit, ponieważ segregation witness oczywiście, ponieważ jakby estetycznie bardziej mi się podoba z matematycznego punktu widzenia. Ale oczywiście i ludzi tyle zdań. Jednak co tak naprawdę, czym naprawdę jest segregation witness i co adresuje? Oczywiście oprócz skalowania w Bitcoin pojawiają się różne inne problemy. Tak jakby
Z mojej perspektywy ciekawym problemem jest właśnie transaction malleability. Znaczy to mniej więcej tyle, że kiedy ja wysyłam transakcję w ramach jakby pre-seguid to ktoś kto przekazuje moją transakcję dalej na przykład node do którego zapłukałem i powiedziałem hej to jest moja transakcja przekaż ją do wykopania i potwierdzenia w bloku może w niewielki sposób zmodyfikować tą transakcję w ten sposób, że jej treść się nie zmieni. To znaczy będzie opiewać na te same transakcje wejściowe i na te same transakcje wejściowe. Ale zmieni się jej hash, czyli identyfikator. To znaczy mniej więcej tyle, że jeżeli ja po drugiej stronie oczekuję, że mój kolega wysłał mi transakcję o takim identyfikatorze, to mogę jej nigdy nie otrzymać. To wynika choćby z tego, że generalnie
jakby sposób w jaki można wydać potem takie transakcje jest opisany pewnym skryptem. Jeżeli ktokolwiek kiedykolwiek pisał w assemblerze no to odnalazłby się tam bardzo dobrze. Jeżeli ktokolwiek kiedykolwiek pisał w assemblerze no to wie, że istnieją przeróżne operacje, które tak jakby nie zmieniając treści skryptu mogą dodać do niego długość. Pomyślmy tutaj o takich NOP-ach tylko w Bitcoinie. Dopisując takie NOP-y można zmienić hash transakcji, a w ten sposób stworzyć jakby nową transakcję, która opiewa na to samo. Segregation witness rozwiązuje ten problem w ten sposób, że kiedy w przeszłości do wejściowych transakcji był dołączany podpis, czyli potwierdzenie tego skryptu i to wszystko było haszowane. Segregation witness wydzielił blok, który mówi tu są dane, tu jest to co jest gęste,
tu są transakcje, a potem jest taki blok witness, w którym te wszystkie potwierdzenia się znajdują. Rozwiązanie jest o tyle banalne, tak samo banalne jak i genialne, ponieważ pozwoliło to rozwiązać szereg problemów. Oprócz transaction maleability tak samo zwiększyło rozmiar bloku.
Ponieważ pojawił się, dobrze ja pozwolę sobie pominąć demo. Ponieważ w tym momencie oblicza się rozmiar transakcji nie jako rozmiar w megabajtach, a bardziej jako coś w stylu wagi. I ta waga mówi tyle, że blok może zawierać 4 miliony pewnych jednostek. A jedna transakcja zajmuje tyle jednostek co trzy razy jej rozmiar w megabajtach, znaczy w bajtach bez bloku witness, czyli bez podpisów plus rozmiar całej transakcji. Efektywnie oznacza to tyle, że dla starych transakcji, które ciągle mają podpisy przywiązane do transakcji do wejść, nie zmienia się nic. Czyli ciągle możemy
zmieścić w bloku jeden megabyte transakcji, ale kiedy zaczynamy ucinać ten blok witness, ten blok podpisów to okazuje się, że Nowych transakcji mieści się tam więcej. Mówimy tutaj o 60%, 100% więcej transakcji w jednym bloku.
Teraz wracając na chwileczkę do tej historii z kopaczami i aktywowaniem Segwit z powiększonym blokiem. Oni chcą po prostu zwiększenia tego limitu wagi do 4 milionów. Przepraszam do 8 milionów. Jednak co tak naprawdę wynika z Segwit. Rozwiązaliśmy skalowanie, rozwiązaliśmy transaction alliability, czyli mamy większy rozmiar bloku. Pojawia się też taka ciekawostka jak podpisy Schnora czy też sygnatury Schnora. Oznacza to tyle, że gdy dotychczas każda transakcja musiała być podpisywana pojedynczo. W tym sensie, że do każdej transakcji musiał być dołączony osobny podpis to w ramach krypto systemu Schnora, już nie zagłębiałem się w szczegóły, bo zaczyna mi brakować czasu. Takie transakcje, takie podpisy można złączyć w jeden zbiorczy podpis. I to też trochę odpowiada na problem anonimowości, ponieważ tak jak wspomniałem trochę odrobinę wcześniej, gdy widzimy
wiele adresów wejściowych w jednej transakcji no to możemy swobodnie założyć z większym lub mniejszym prawdopodobieństwem, że mówimy o jednym autorze tej transakcji. Jednak gdzieś tam w międzyczasie pojawił się pomysł tego, żeby wprowadzić system, który nazywa się CoinJane. CoinJane mówi mniej więcej tyle, że możemy umówić się tutaj na tej sali, że wszyscy wyślemy transakcje tam gdzie chcemy, wszyscy będziemy dołączali swoje transakcje wyjściowe i wszyscy będziemy dołączali wszystkie osoby do których chcemy to wysłać. Ostatecznie oznacza to tyle, że to moje podstawowe założenie, że jeżeli jest wiele adresów wejściowych do tej samej transakcji to mamy do czynienia z jednym autorem, no staje się fałszywe, ponieważ wszyscy się na to złożyliśmy. To wygląda mniej więcej tak jakbyśmy Byli na wakacjach
i chcieli się umówić na zakupy, więc wszyscy tą wymienioną walutę wrzucili do jednego koszyka, po czym poszli do sklepu, dostali wszyscy do ręki to co chcieliśmy, ale nie da się jednoznacznie powiązać za czyje pieniądze został kupiony dany produkt. W przypadku Sygnatur Schnora jakby ta identyfikacja staje się jeszcze bardziej kłopotliwa, ponieważ wszystkie podpisy zostaną złączone do jednego. Dodatkowo tak jakby ze względu na to, że nie da się już podrobić tego identyfikatora transakcji, nie da się go przerobić w ruchu. Mogą być wprowadzone przeróżne pomysły jakby budowania blockchainu nad blockchainem bądź sieci finansowej nad blockchainem. Tutaj najlepszymi przykładami jest chyba Lightning Network, który mówi mniej więcej tyle, że w danym okresie czasu mogę się umówić z moim kolegą, że przelewamy
na taką wspólną transakcję która wymaga obu naszych podpisów jakąś kwotę, po czym już poza blockchainem wymieniamy się przeróżnymi poprawkami do tej transakcji, by na końcu opublikować to wszystko i powiedzieć w tym momencie to ma trafić do blockchainu, już się umówiliśmy, skończyliśmy nasze wszystkie transakcje. Taki jakby kanał Lightning Network może być otwarty miesiącami zapewniając rzeczywiście jakby
transakcje dziejące się w ciągu sekund. W ciągu mikrosekund, ponieważ wszystko jedyne co nas ogranicza to wymiana tych poprawek do transakcji. Na tej podstawie też pojawił się taki ciekawy pomysł Atomic Swap. To znaczy w tym momencie wymieniając kryptowaluty opieramy się na giełdach. Znaczy jeżeli ja mam Ethereum, mój kolega ma Bitcoina i ja chciałbym kupić jedno albo drugie no to musimy się ze sobą pogadać albo po prostu pójść na giełdę.
W ramach Atomic Swap bez żadnego zaufania możemy otworzyć w obu blockchainach taki kanał Lightning Network. Wymienić się w ramach już takiego powiązanego Lightning Network poprawkami do transakcji. Po czym odłożyć tą zmianę w obu blockchainach. W ten sposób ja zyskuję Bitcoiny, które chciałem kupić, a mój kolega Ethereum. Oczywiście takie korzyści można mnożyć niezależnie od tego. Chwileczkę chciałbym poświęcić na ewentualne pytanie, jeżeli jakieś się pojawiły.
Ten anatomic swap tak jak zabrzmiało przez chwilę jakby to te pieniądze mogły znikąd przyjść. Na zasadzie to ja sobie wymienię Bitcoina na Ethereum i magle dobra to mi się pojawiają blockchainy tu, a tu się pojawiają
tu mi się pojawiają bitcoiny, a tam mi się pojawiają ethereum i tak. Czyli jest jakiś taki rejestr, musiałby być rejestr między wymiany między tymi jakby dwoma walutami, czyli tak naprawdę taka giełda, tylko że bez giełdy. Czyli nie wiem jak to, czy dobrze to... Właśnie coś mi mówiło, że jednak potrzebuję obrazka, żeby to dobrze wytłumaczyć. Niezależnie od tego wyobraźmy sobie, że w pewnym momencie tworzymy takie subkonto wiszące nad blockchainem pod tytułem otwieramy transakcję, ja Panu przelewam jednego Bitcoina i Pan mi jednego Bitcoina. A potem na przykład zmieniamy troszkę balans, ale już wymieniając się transakcjami między sobą, nie odkładając ich w blockchainie. Czyli na przykład ja mówię, ok, tam nie wiem, byliśmy w hotelu, Pan zapłacił, więc
ja teraz oddaję tam jakąś część tego Bitcoina, ale tylko Pan jakby przechowuje transakcję, którą ja Panu przesłałem jako jako bajty, tak? Potem okazuje się, że nie wiem, ja dla Pana coś kupiłem, Pan dla mnie i tak dalej i tak dalej i tak dalej i tak dalej. Nawymienialiśmy się w ten sposób, że na przykład wyszło, że mi zostało pół Bitcoina w ramach tej transakcji, a Panu jeden, jeden i pół, przepraszam. I w tym momencie mówimy dobra publikujemy te wszystkie transakcje. I one trafiają do blockchainu. I teraz w ramach braku zaufania dwóch osób, które chcą się wymienić między blockchainami. Taką samą strukturę można zbudować w ramach jednego, a potem drugiego blockchainu. Wymieniając się transakcjami w końcu dojść do konsensusu i stwierdzić okej to tak jakby sprawdzam, sprzedaję i
kończymy tę wymianę.
Okej, tak jak wspomniałem w miarę możliwości postaram się być gdzieś w okolicy. niezależnie od tego, jeżeli mi się nie pojawił, na pewno pojawia się później, chętnie podajemy dodatkową dyskusję. A póki co bardzo dziękuję.
Dziękujemy bardzo. Taka informacja dla osób, które nas oglądają za pośrednictwem serwisu YouTube. Następna że lekcja będzie niedostępna tym kanałem ze względów takich, że Pan Dudek sobie tego nie życzył. Także to jest informacja dla osób, które nas oglądają. Kolejna sprawa, osoby, które mają identyfikatory są proszone na przerwie o zejście na dół, ponieważ już doszły, jak widać. Prelegentów proszę o podejście do stolika organizacyjnego, gdyż dla Was mamy po prostu już na miejscu.
Myślę, że dosłownie dwie minuty na przepinkę i lecimy z drugą prezentacją. Gotowe?
No to zaczynamy, zapraszamy Pana Dudka. wszystkim. Znaczy nie do końca jest tak, że nie chcę, ale tak trochę z charakteru na, jakie się tutaj będą znajdowały obrazki na tej prezentacji, to wolałbym, żeby ona nie była na żywo, gdzie każdy anonimowo może ją obejść. Oczywiście też jesteście anonimowo, ale to jednak trochę inaczej twarz do twarzy.
Ja nazywam się
Ktoś patrzy? Chyba, dajmy na to. Okej, jeszcze ktoś się schodzi, dajmy chwilkę.
Dobra, to cześć, dzień dobry. Ja nazywam się Dariusz Jakubowski, nie wiem, czy ktoś mnie kojarzy, możecie mnie znać z IRCA, spodniku Nekro666. W zeszłym roku na prezentacji moim zdaniem zupełnie nie wyszła, ale jakby chciałem tylko zrobić, nie śmiej się, chciałem zrobić rozeznanie po prostu jak to wygląda, tak? Nie byłem na B-sidecie wcześniej, nie bardzo jestem w tematach security. Generalnie zrobiłem dzisiaj taką podstawkę ogólnikową, jeżeli chodzi o jakąkolwiek zachowanie prywatności i bezpieczeństwa w sieci, w terenie. To będzie bardzo proste. Troszkę żałuję, że kolegę wcisnęli przede mnie, bo on zrobił to bardzo fajnie szczegółowo i to byłoby takie super rozwinięcie do tego, co chcę dzisiaj pokazać. I teraz tak, rzeczy, które pokażę są bardzo proste, takie, które znacie albo może gdzieś
słyszeliście, niemniej jest tego tak dużo, że na pewno ktoś zauważy coś tam zawsze nowego. Zainspirował mnie do tego taki pewien szczegół. Nie komentujcie, niech podniesie rękę ktoś, kto widział saszetkę taką cukru waniliowego. Dużo. No i właśnie w tym rzecz, że gówno widzieliście, bo cukier waniliowy... cukier wanilinowy. Ja się o tym dowiedziałem po 20 latach. Całe życie w kłamstwie, niby szczegół, ale jak to daje do myślenia, że można mieć coś w życiu w ręku przez 20 lat i nie mieć zielonego pojęcia, jak to się nazywa. Wszyscy popełniają ten błąd. Kto wiedział, że to jest wanilinowy? No bez jaj. No dobra, to wyszedłem na idiotę. Ale kilka osób nie wiedziało, rozumiecie sens, tak? Okej, tak więc dokładnie idąc tym tropem, żeby nie robić tutaj za bardzo, nie zanudzać
was przed lunchem, chciałem zrobić taki bardziej lightning talk, myślę, że to 15-20 minut potrwa, tu jest kilkanaście slajdów. Więc tak, podzielona prezentacja jest na sekcje, co robić, w jakich sytuacjach, zacząłem od rozpowszechnianych materiałów, moim zdaniem to jest chyba najbardziej wyczerpany przeze mnie temat, najciekawszy, bo tutaj jest dużo rzeczy, na które trzeba uważać, które są znane, ale są tak stare, że już dawno ich nie ma na żadnych nowych artykułach, na Z3Sie, na niebezpieczniku, to po prostu było dawno, dawno, dawno temu pokazane i zapomniane. I teraz jak ludzie rozpowszechniają takie materiały, to potrafią zrobić taką gafę, o której powinni byli wiedzieć. Pierwsza, to jest chyba takie największe wow, o czym mało kto wie, jest przedźwięk. Kto słyszał kiedykolwiek o takim zjawisku? No.
cztery osoby. Pięknie. Przedźwięk na pewno znacie z praktyki, jeżeli przesuniecie za bardzo mikrofon do głośników, do komputera stacjonarnego, zaczyna się takie typowe brzęczenie. Sprawa jest taka z tym brzęczeniem, że to jest brzęczenie o częstotliwości sieci. Sieć ma, jak dobrze kojarzę u nas, 50 Hz, prawda? I to jest taka przyjęta częstotliwość naszej sieci elektrycznej, ale w rzeczywistości nie jest stała. Jeżeli turbiny dostają więcej, powiedzmy, wody, działają troszkę szybciej, częstotliwość się waha o 5 Hz w T3WT. I to wszystko jest rejestrowane. Te takie wahania, pewne zmiany w częstotliwości sieci elektrycznej są rejestrowane na konkretną elektrownię w konkretnym czasie. Jeżeli wysyłamy, budujemy jakikolwiek materiał wideo i nagrywamy go powiedzmy na komputerze stacjonarnym, ten przedźwięk może być słyszalny, może być nawet niesłyszalny, ale jest do wyłuskania w softie
takim jak Audacity na przykład. I generalnie bardzo ludzi to omija. Tak jak widzieliście, cztery osoby tylko to znają, a to jest w zasadzie pierwsze po co sięga policja, jacykolwiek inni funkcjonariusze. Sprawdzają te niskie częstotliwości, sprawdzają kiedy i która elektrownia nadawała sygnał w takiej częstotliwości i już mam dosyć mocno zawężony krąg. Napisałem tutaj tak, od stu do kilkunastu kilometrów to zależy od tego, w którym miejscu było nagrane, bo na północy Polski tych elektrowni jest zdecydowanie mniej, także tam mamy, no wiemy, że do tej elektrowni to poszło, ale to jest okrąg takich stu kilometrów. Tutaj na południu mamy bardzo dużo elektrowni, więc bardzo łatwo sobie zawęzić krąg, nawet do dzielnicy miasta czasem. Identyfikacja daty godziny, to powiedziałem i generalnie można się przed tym chronić,
nawet bardzo łatwo. Chodzi o to, żeby nie używać prądu z sieci bezpośrednio. To jest jasne, że akumulatory i takie rzeczy tego przy dźwięku nie powodują. My możemy go łatwo przeoczyć, ale w tym przypadku, jeżeli złożmy ten komputer, jest podpięty do sieci, to już idzie, już te zakłócenia są wyczuwalne w komputerze, można je wyłuskać. Jeżeli ja wyłączę ładowarkę, on nie ma połączenia z siecią. Nigdzie to nie przejdzie, może teraz jest trochę blisko, bo pewnie tam są mikrofony i będą, w sensie głośniki, które będą wpływać na mój mikrofon, może to tam być, więc trzymać się jak najbardziej z dala od sieci elektrycznych, rozpowszechniając materiały wideo, audio, gdzie chcielibyśmy zachować... Tak, kolega pyta?
Rejestracja, tak. Może mikrofon, chwilkę, może mikrofon. Bo bardzo mi się to podoba, możemy zadawać pytania w trakcie prezentacji. Pewnie też wielu rzeczy, nie wiem, może ktoś coś dodaje, będzie więcej merytoryki. Bardzo mnie zastanawia kwestia monitorowania tego, co elektrownie pchają do sieci energetycznej. Jestem ciekaw, czy faktycznie są takie rejestracje prowadzone i na jakie potrzeby przede wszystkim. Po to, że później z tego publicznego może skorzystać, Generalnie tak, wiem o co Ci chodzi, danych tam nie ma dużo, bo tak naprawdę to są takie zwykłe logi, które i tak i tak się przechowuje, to nie jest na potrzeby tylko na mierzania złych ludzi, tak w zasadzie nawet nie, po prostu chcą sprawdzać. Tam jest sprawa, że miasto, pobór tego prądu też ma wpływ na częstotliwość pracy sieci, bo jakby turbiny są
bardziej obciążone, wolniej się obracają, więc oni muszą jakby dostosowywać do aktualnego zapotrzebowania na pracy swoich turbin, ich obciążenie, nie tylko turbin, ta masy innych agregatów prądotwórczych, no i na potrzeby statystyczne też oczywiście. Przy czym to jest fakt, że te bazy są znane, można je, znaczy publicznego dostępu nie ma, ale wiemy, jak takie rzeczy są chronione, prawda? To nie był żart, chwilkę na pieszy. Strasznie tutaj mamy gorąco. Kolejna jest manipulacja głosem, to jest temat w Polsce jeszcze służby bezpieczeństwa tego aż tak mocno nie obcykały, ale wiemy, że wszystko przechodzi zazwyczaj przez Zachód, ten daleki Zachód i tam się robią problemy. System PRISM jest znany, jest faktem, większość wie jak działa i inni nie wiedzą jak działa, tylko
to skrócę, że jeżeli zrobimy, posiada bardzo dużą bazę próbek głosu i potrafi po próbkach głosów też wyszukiwać inne materiały, czyli jeżeli umieścimy gdzieś jakieś wideo czy plik audio, w którym mówimy coś, czego nie powinniśmy byli mówić, tak sądzę?
Zielonego pojęcia nie mam, ale nie zdziwiłbym się, naprawdę nie zdziwiłbym się. Wiesz, co generalnie, choćby może nawet nieświadomie, bo Prism kontroluje cały ruch taki internetowy w szeci Stanów Zjednoczonych i wszystko, co przez nie przechodzi. Jeżeli nasze, chociaż nie, Siri na pewno ma lokalnie rozpoznawanie głosu, więc te próbki by nie wychodziły. Siri rozpoznaje głos lokalnie. Nie wiem, jak w androidowym, podejrzewam, że też, bo to nie jest jakaś taka super skomplikowana sprawa. Chyba w sumie nie. Niemniej, jeżeli mamy jakiś filmik na YouTubie, mogą sprawdzić, skojarzyć nasz plik audio z jakimś naszym filmikiem na YouTubie. Z dosyć wysoką skutecznością to udowodniono. Teraz tak, dodatkowo ludzie sobie często robią taką zmianę głosu, typu takie bardzo obniżone głosy, tak jak
w uwadze zakryta twarz i głos bardzo obniżony, to nie działa. To można bardzo łatwo taki proces odwrócić. uważa, że się zrobi to dobrze, ale zazwyczaj się tego dobrze nie robi, łatwo ten proces odwrócić i uzyskać znowu oryginalny głos. Znowu wrzucany jest w Prisma albo inne alternatywne systemy, bo takich jest więcej i możemy uzyskać takiego delikwenta. Następnie są urządzenia skrambulujące, to jest to samo, też zmiana głosu, tylko hardware'owo. One są skomplikowane w użyciu, zdrowo wymagają sterylnych warunków typu przydźwięk, ma znowu na to wpływ, więc z deszczu pod rynne wpadamy. Są drogie Ciężko się ich używa, raczej bym odradzał. No i nadal, tak, nie gwarantują nam stuprocentowej bezpieczności. W zasadzie, jeżeli chcemy rozpowszechniać takie materiały wideo, które powinny nam zachować jakąś anonimowość, prywatność, generator
mowy, nic innego. Open source'owe generatory mowy, wiemy, żadnych metadanych, jakichś ukrytych danych nigdzie nam nie doklejają, także tutaj jesteśmy zupełnie bezpieczni, bo ani to użycie nigdzie nie wychodzi. Po prostu nie ma się do czego przyczepić. Także nawet zupełnie żadnego dźwięku w jakichś klipach wideo i tym podobnych sam dźwięk z generatora mowy i to tyle. Kolejne pytanie, spoko. A propos tych generatorów mowy, czyli co, Iwona i tego typu rzeczy, tak? Dokładnie tak, dokładnie Iwona tego typu rzeczy. Akurat Iwona Open Source, nie wiem czy nie, dokleja czegoś, ale bardzo bym w to wątpiał. Okej, czyli wszystkie śmieszki, które nagrywają te śmieszne filmiki na YouTube'a są bardziej bezpłaszne niż taś prosty YouTuberzy. W zasadzie tak, w zasadzie tak.
W zasadzie dokładnie tak jest. Okej. Dobra, dalej obraz. Tutaj też wiele osób bardzo sobie pozwala w dobie kamer 4K, 60 fps, robimy bardzo ładnej jakości materiał wideo i to też jest bardzo duży błąd, bo nawet płynność wideo dostarcza bardzo wielu informacji z takiego bardzo płynnego wideo. Moglibyśmy sobie bez problemu, naprawdę bez najmniejszego problemu zrobić model 3D całego pomieszczenia. że nie z każdego kąta, ale wystarczająco, żeby dostarczyło dodatkowych informacji dodatkowo, tak jak znamy CSI, na pewno każdy widział bardzo zapikselowany klip wideo, jest powiększenie, powiększmy kwadrat B4 i tam jest wyraźna twarz delikwenta, to jest możliwe. W rzeczywistości to jest możliwe, bo jeżeli mamy wideo niskiej jakości, ale albo jest wystarczająco dużo klatek, albo mamy dużo tego materiału, pomiędzy klatkami możemy sobie połączyć
pewne tak to nazwijmy, i uzyskać dużo wyraźniejsze zdjęcie niż jest tylko na jednej klatce. Także na to też trzeba uważać i takie materiały ograniczać do jak najgorszej jakości i jak najmniejszej ilości klatek na sekundę. Takie zakłócenia są bardzo przyjazne. I teraz tak, mamy to. Kolejno, odbicia. Na MIT opracowano bardzo fajny algorytm, który w przypadku tego, jak na przykład tutaj jestem nagrywany, nie ma żadnych odbić, ale w drugą stronę jest szyba, nasze oko tego nie widzi, nasz mózg nie rejestruje tych odbić, ale te algorytmy bardzo łatwo potrafią wyłuskać zupełnie drugi obraz z odbicia szyby. Nie wiem, czy ktoś się spotkał z czymś takim, z tym algorytmem, bardzo fajna sprawa, także cieszę się, że coś nowego. Przekazujemy mu zdjęcie, klip wideo, algorytm nam
wyciąga jedno wideo, które jest nagrane jakby to, co chcemy, samo odbicie, albo pierwsze bez żadnego odbicia, także też dodatkowe dane, które możemy przeoczyć, bo my nie zauważymy, że coś się odbija, że my się odbijamy, że jakieś szczegóły się tam odbijają, ten algorytm to wyłapie. Oczywiście trzeba unikać też jakichkolwiek warunków naturalnych typu pogoda, wiatr, słońce, samoloty, w ogóle niebo. Bardzo głośny był przykład, jak Forchanowcy znaleźli flagę wywieszoną przez Chie'e Leboeuf. Widzę, że dokładnie, dosyć znany przykład. Wystarczyło zdjęcie flagi i jakiś samolot, który przelatywał tylko w tle. Od razu namierzyli w zasadzie, gdzie ta flaga jest. Mimo, że była ukrata gdzieś w środku pola, bez problemu na podstawie kątu, pory dnia, słońca i tego lecącego samolotu namierzyli, gdzie one się
znajdują sobie zerwali. Drugą później też, ale to już było nudne. Następnie tak, zniekształcać obraz. Jeżeli robimy coś takiego, zniekształcać obraz narzędziami typu... Photoshop, w sensie ten afterlight od Photoshopa, od Adobe, to działa, bo to nie są generowane na żywo jakieś szumy zakłócenia, po których też moglibyśmy potencjalnie namierzyć, tylko to są nałożone statyczne obrazki, które się tam... poruszają i kamera nieruchoma. Tak jak mówiłem, żeby jak najbardziej zniwelować ruch, bo to dostarcza wielu szczegółów, typu możemy sobie zmapować jakąś scenę na 3D, to też widać czasem w CSI i też to jest możliwe. Naprawdę takie rzeczy się dzieją, a służby nam nie raz udowodniły, że potrafią zrobić taką magię, o jakiej nam się nawet nieśli. Drukarki. To jest
w miarę nowy temat, przy czym on ma jeszcze drugie dno, o którym mało kto wie. Ktoś spotkał się z takimi żółtymi? Słabo to tutaj widać. One są... zaznaczone i trochę zostawiam niezaznaczonych, bo nie wiedziałem jaka będzie jakość na projektorze, ktoś to widzi? Czy to jest widoczne? Ten Pan widzi. Dobrze. Generalnie sprawa jest taka, że bardzo wiele drukarek wzorowało się na systemie, który mamy na obecnych banknotach, nazywa się Eurion, zaraz o nim opowiem i robi bardzo niewielkie kropeczki na niewielkim fragmencie kartki, żółte, które są zupełnie teraz niedostrzegalne. My robimy setki takich wydruków, te kropeczki tam są. Tam jest data godzina wydruku, numer seryjny drukarki, często jej nazwa albo nazwa komputera. Coś, co pozwoli służbom ewentualnie jakiś list z żądaniami i tak dalej namierzyć, skąd on pochodzi. Już sobie
robią takie dodatkowe zabezpieczenie. Kto słyszał o tym mechanizmie? Nie, źle, ale nie wszyscy. Pytanie? Proszę, super. Tutaj było pytanie, tak? Skąd żółte kropy, które tak monochromatyczne? Nie, monochromatycznych ich nie ma. Znaczy, z tego co wiem, pewnie jest jakiś inny mechanizm. Ale mechanizm działa w drugą stronę, bo on został najpierw zrobiony w skanerach, nazywa się Eurion. Widzieliście nowe banknoty, mają takie śmieszne, nawet polskie, polskie złotówki mają kropy żółte, takie kółeczka. To jest oznaczenie do skanerów. Jeżeli skaner wykryje te kółeczka, nie pozwoli na zeskanowanie banknotu. Pamiętamy, takie anegdotki były, że Photoshop nie pozwala na przerabianie banknotów i drukowanie ich. To jest zalążek tej technologii. Tylko, że to działało tylko w przypadku dolarów. Teraz każdy banknot, który ma na sobie te
kropeczki w ułożeniu konstelacji Oriona, dlatego się Eurion nazywa, nie będą zeskanowane. tylko taka ciekawostka. Na EFF, na pewno znacie tą stronę, jest lista drukarek znanych, które dodają te kropeczki, bo można, jak się o nich wie, to można je w miarę łatwo namierzyć. Na pewno trzeba też używać drukarek sieciowych, no tego chyba nie muszę tłumaczyć dlaczego, tak, bo możemy sobie dodać sami takie kropeczki albo zmodyfikować wydruk. Pytanie jakieś było? Tam jest napisane nie używać drukarek sieciowych. No tak, ale to nie w związku z kropeczkami. Czyli jak wezmę zwykłą, standardową drukarkę z lat 90. podepnę ją pod kapsa na Linuxie, ja jestem bezpieczny, tak? Czy kaps na Linuxie jest bezpieczny? Zadaj sobie to pytanie, bo mi nie chodzi o te kropki. Mi nie chodzi o te kropki.
Tutaj to jest po prostu dodatkowy punkt nie używać drukarek sieciowych, bo nie wiemy co ta drukarka sieciowa robi i nie wiemy kto ma do niej dostęp. Więc jeżeli my zrobimy sobie coś takiego, ktoś się prześwieć może do jakiegoś keszla dostać, a drukarka może już coś takiego wysyłać, znamy takie historie. To zupełnie poza tym. Fałszywa tożsamość. Od tego momentu się robi nudno, ale jeszcze to przerobimy dla samej zasady, dla samego faktu, bo jak mówię, każdy czegoś nowego się nauczy. Uważam, że są takie trzy sensowne. Trzy sensowne sposoby na uzyskiwanie fałszywej tożsamości do różnych celów. Każdy ma swoje plusy dodatnie i plusy ujemne. Zależy do czego tego potrzebujemy. Warto korzystać z generatorów danych przy każdej najmniejszej operacji. Zapisujemy sobie wygenerowaną tożsamość. Mamy internetowe generatory, które nam
bardzo dużo fajnych rzeczy z góry generują. Miejsce zamieszkania, PESEL-e, numery dokumentów, numery ubezpieczeń. Pełna kartoteka fikcyjnego człowieka. Plusem jest to, że to jest szybkie. Słucham kolegę? Głośno musisz.
Nie mogę, bo nie znam, co są długie adresy, nie pamiętam. Fake name generator, fake id generator, jest tego masa, tego jest naprawdę dużo. Pierwszy, który wyskoczy na pewno się nazywa fakenamegenerator.com i on jest bardzo fajny, bo potrafi nam wygenerować nawet skrzynkę mailową, do której mamy fizyczny dostęp. Czyli mamy maila przypisanego do fałszywej osoby i ta skrzynka faktycznie istnieje. Szczegółów jest bardzo dużo. Warto to mieć, bo jeżeli dzwonimy, robimy, znaczy ktoś robi jakiś scamming, dzwoni gdzieś przez telefon, próbuje wyłudzić jakieś dane, od razu żadne pytanie go nie zaskoczy. A skąd pan jest? Stąd i stąd. Jakie wykształcenie? To i to. Może numer PESEL mogę poprosić? Jasne, wszystko ma przed sobą i przy powielonym takim pytaniu nadal ma to przed sobą, tak, czyli nie
wymyśli nowego, jest spójność danych. Problemem jest to, że taka osoba, jeżeli będzie wygooglowana w internecie, nie istnieje. Jej dokumenty, mają wygenerowane numery, nie istnieją, także jakiekolwiek chwilówki tego typu rzeczy na to odpadają, chyba nie muszę tego tłumaczyć, ale plusem jest to, że to jest bardzo szybkie, darmowe i niezwykle wygodne w użyciu, nawet w codziennym użyciu, jak robicie, rejestrujecie się na jakiś newsletter czy coś, warto czegoś takiego używać i mieć święty spokój na przyszłość, żeby was nie kojarzono cały czas tą samą osobą i tym samym profilem. Dalej, to pokazał kolega, mi się bardzo to podobało, dlatego żałuję, że nie ma go po tym. To jest kradzież dokumentów, pokazał bardzo fajne sposoby kradzieży dokumentów. Ja się bałem tego trochę robić. Pozdrawiam niektórych gości. I tak, plusem,
takiego rozwiązania jak kradzież dokumentów jest to, że mamy istniejącego człowieka, którego po pierwsze możemy znaleźć w internecie, mniej lub gorzej, ale możemy go znaleźć w internecie, ale na pewno istnieje w bazach typu KRD, BIK i to wszystko, gdzie możemy na niego tą chwilówkę faktycznie wziąć, jeżeli ktoś potrzebuje gotówki do jakiejś operacji. Problemem jest to, że taka operacja jest czasochłonna i jest ryzykowna, stosunkowo ryzykowna, bo jak pokazałem można w miarę łatwo jakich ludzi namierzyć. Tutaj napisałem brak powiązanych kont internetowych, bo nie zawsze to gwarantuję, zazwyczaj przy wyłudzeniu takich danych, takich dokumentów trafia się na Januszy, którzy niekoniecznie prowadzą Instagrama czy mam swojego Twittera, prawda? Po prostu istnieją i sprzedają gdzieś Passata na Elixie. Kradzież kont internetowych, to jest moim zdaniem
chyba najlepsza opcja, jeżeli, bo Nie wiem, nigdy nie interesowałem się tematem, jak ludzie wyłudzają na kogoś chwilówki i tego typu rzeczy, bardziej kradzież tosamości faktycznie internetowej. Są strony, czy ktoś zna strony typu Willig.info i tego typu? Nie, o proszę, to zaskoczenie. Strony, które, have I been pound, stronę, gdzie wpisujemy swojego maila i pokazuje nam, czy zostaliśmy, czy nasze hasło gdziekolwiek wyciekło. To znacie? Doskonale. w drugą stronę. Tutaj wpisujemy sobie maila, którego hasło chcemy mieć, czyli te wszystkie bazy, które ta strona, o której wspomniałem, sprawdza, my nie możemy się do nich dostać, oni je mają i sobie sprawdzą, czy to tam istnieje, namówić, czy jest dobrze, czy nie jest dobrze. W stronach typu Wilkinfo faktycznie dostęp do takich informacji jest.
Różnie to wygląda z legalnością na terenie różnych krajów, ale nie mniej to istnieje, to jest bardzo tanie, bo widzicie tutaj kawlek cennika, za dzień nielimitowanego dostępu płacimy 8 złotych. w zasadzie miliony kont internetowych z hasłami, z powiązanymi, newralgicznymi danymi, które zazwyczaj działają. Naprawdę byłem bardzo zdziwany, że coś takiego w internecie normalnie otwartym istnieje. Przyjmują płatności bitcoinów. Bardzo dbałem też o nasze dane typu tak jak NordVPN, żadnego logowania ani takich rzeczy. Plusem jest to, że tutaj mamy opcję nie tak jak czekamy aż jakiś Janusz nam wyśle swój dowód osobisty czy prawo jazdy. Tutaj targetujemy ataki. Mamy czyjegoś maila, szukamy go. znajdziemy tutaj czy tam, po nazwisku, po niku zawsze coś się znajdzie i mamy konkretną osobę, którą ktoś chciałby zaatakować. Dalej, urządzenia
bezprzewodowe, tutaj też jest kilka rzeczy, o których okazuje się, że nie każdy coś kojarzy. SS7, ostatnio popularny temat, czy ktoś kojarzy? No, mniej niż połowa, ale i tak nieźle. SS7, jakby to kolokwialnie powiedzieć, internet telefonów komórkowych, internet GSM i te... tego typu. Generalnie polega to na tym, że mając operatorzy mają dostęp do tej sieci, gdzie mogą między sobą urządzenia komunikować, osoby prywatne nie mają takiego dostępu, nie powinny mieć, a można sobie go wykupić za mniej więcej 500 zł miesięcznie i mamy, myślałem, że ktoś zadał pytanie, przepraszam, mamy dostęp do tej sieci, możemy na niej wykonywać takie operacje typu mam czyjś numer e-mail albo mam czyjś numer telefonu, mogę się ci zapytać, Gdzie ta osoba jest? Do jakiego BTSa
z jaką siłą jest połączona? Czyli jeżeli ktoś jest tutaj na ulicy, to ja widzę, że on jest połączony do jakiegoś... Dostaje numerek tego BTSa, mapa BTSów jest... ogólnie publicznie dostępna, wpisuję sobie numerek BTSa, widzę gdzie ta osoba się znajduje. Mogę to robić w czasie rzeczywistym, bez żadnych ograniczeń, to jest nienamierzalne, bo nie wymaga żadnej ingerencji ze strony użytkownika. Są nawet serwisy, które pozwalają nie tylko na bezpośredni dostęp do sieci SS7, w której możemy podsłuchiwać rozmowy, możemy je przechwytywać i odpiąć czyjś telefon w bardzo prosty sposób. To jest bardzo stara sieć, ona jest bardzo źle zaprojektowana, ale ludzie mają założenie, że skoro i tak nikt do niej publicznie dostępu nie ma, to w sumie można tak zostawić. i błąd, jak widać. Teraz tak, analiza zmian,
podobnie jak w przypadku Policji, Policja ma troszkę inny sposób, o którym zaraz powiem, pozwala na, bo wiecie, BTS, jestem w promieniu 100 m od tego BTSa, ale jeżeli ja szybko przeskoczę na drugiego BTSa, to już mój algorytm, mój program może się zorientować, że jestem tego jednego BTS-a, więc jakby rysuję sobie linię i mamy taką triangulację, bardzo sobie zawężamy położenie jakiegoś człowieka, możemy go namierzyć z dokładnością co do kilku metrów w zasadzie. Policja robi to w odwrotny sposób, czyli pyta sześć, też SS7 z tego co kojarzę i wszystkie BTS-y do którego, który BTS widzi nasz telefon. I działa to dokładnie tak jak GPS, tylko na poziomie ulicy lokalnie, czyli do tego BTS mamy połączenie z taką siłą, do tamtego z taką siłą i bardzo łatwo sobie
policzyć, gdzie dokładnie delikwent przebywa. Też żadnej ingerencji w telefonie, nikt o tym nie wie, że coś takiego się dzieje. Jakieś pytania do tamtego? Bo skoro nie znacie SS7, może by coś było. Dobrze, miło mi. Inne sposoby na to, jak telefon może zdradzić naszą lokalizację, tutaj nie miałem już weny na obrazki, nudziła mi się, była noc. Po pierwsze włączone bluetooth, każdy prawdopodobnie, no dobra może nie każdy, ale zdecydowanie większość z Was ma włączone bluetooth, które widać. Jeżeli prowadziłbym lokal albo chciałbym wiedzieć czy ktoś niechciany zbliża się do mojej lokalizacji, zrobiłbym sobie po prostu nasłuch i widział jakie urządzenia bluetooth są, czy to są moje znane, czy nie są znane. sobie mogę odfiltrować i sprawa jest taka, że telefony szczególnie nowe, w nowych iPhone'ach to chyba dopiero wyszło, była
głośna sytuacja, nawet wyłączenie Bluetooth wcale nie wyłącza Bluetooth, ono cały czas pracuje, tylko nie przyjmuje nowych połączeń, co mnie nie interesuje, bo ja chcę tylko wiedzieć, czy ono istnieje. Także to Bluetooth jest dosyć newralgiczną rzeczą, o której się zupełnie zapomina, bo kto teraz korzysta z Bluetooth? W zasadzie nikt nie korzysta, nie przejmujemy się, że ona jest gdzieś tam włączona. Wi-Fi dokładnie na tej samej zasadzie Ile nie mamy rozgłoszonego żadnego adresu, że nasz telefon rozgłasza, że chce się z kimś połączyć, to nie jest to, czego szukamy. Nadal możemy zobaczyć, że jakieś urządzenie coś na jakieś częstotliwości nadaje, więc wykrywamy niechcianą obecność w naszym obszarze. Jeżeli ktoś robi jakąś operację w terenie, chce być bezpieczny, wiedzieć, że załóżmy na dachu parkingu nikt nie
stoi, w ten sposób możesz sobie ustawić naszuch zwykłym SDR-em, który jest do kupienia za 20 zł na Allegro. i widzi czy jakiekolwiek urządzenia z włączonym Wi-Fi czy Bluetooth się zbliżają. Działa to lepiej niż czujniki podczerwieni, niż wykrywanie człowieka. Telefon łatwiej wykryć. Teraz tak, telefon nawiązując połączenie zakłóci pracę pobliskich odbiorników. To się rzadko zdarza, ale pomyślałem, że o tym wspomnę. Typu, jeżeli kogoś tutaj z pierwszego rzędu zadzwoni telefon, ja to będę słyszał to buczenie, tak, o którym wspomnieliśmy wcześniej. Łatwo, znaczy łatwo na tym wpaść. Jest możliwość w tym wpaść. telefon bez naszej wiedzy połączy się z Honejpotem, z Honejpotem, BTS lub Femtocelem. To jest też druga sprawa, że bardzo mało jest telefonów, które w jakikolwiek sposób sprawdzają, czy BTS, czyli ta stacja nadawcza, bo w sumie tego nie wyjaśniłem,
czy jest autentyczna, czy ja sobie jej sam nie zbudowałem. W sensie ja mogę sobie zbudować, czy ktoś inny może sobie zbudować fałszywego BTS-a, który przekazuje połączenia dalej, ale jednocześnie odczytuje. To jest możliwe, a telefon tego nie sprawdzają. i łączą się po prostu do wszystkiego, do czego leci i nie mamy też na tym kontroli, bo nie widzimy. Niektóre telefony pokazują, że coś jest nie tak z tym BTS, że nie ma autoryzacji, to się rzadko zdarza. Kolega ma pytanie.
To znaczy no nietrywialne jest, ale no wiesz, służby mają do tego jakiekolwiek możliwości, tak, bo To jest jedna z możliwości, ja nie mówię, że każdy, wiesz, każdy jakiś gimnazjalista takie rzeczy robi. To jest możliwość i trzeba o tym pamiętać, że taka rzecz istnieje. Spoofingi. Tutaj się robi jeszcze nudniej, ale jak dobrze kojarzę, to naprawdę kończymy już niedługo prezentację. Nie będę Was zanucał. Spoofing GSM i w zasadzie nazwijmy to po prostu GSM. Nie wiem, czy ktoś się spotkał z takim zjawiskiem, że ja powiedzmy, ja nawet legalnie dlatego mogę powiedzieć, mogę zadzwonić do każdego z Was, w taki sposób, że ja nawiążę to połączenie, ale numer nadawcy pokaże się jako kogokolwiek innego z tej publiczności. Znacie taki mechanizm? To jest możliwe. To działa tak samo jak
w przypadku spoofingu e-mail. Po prostu wystarczy nadpisać na guvet, o kogo to jest wysłane, ba nawet tak jak na poczcie. Na poczcie nikt nie sprawdza, czy my jako nadawca wpisaliśmy prawdziwe dane. Piszemy nadawcę i to po prostu przechodzi. Dokładnie tak samo działa to w przypadku sieci SS7. Mogę po prostu powiedzieć, żeby pokazał się tam inny numer niż mój faktycznie, bo sieci ten numer ITU, czyli ten taki normalny numer, który się pokazuje, nie interesuje. Interesuje e-mail, ona potem, tak jak po adresach MAC, kojarzy. I co ciekawe, w Polsce takie spoofingi są legalne. z tym zastrzeżeniem, że nie mogę do kogoś zadzwonić, nikt nie może do kogoś zadzwonić ze spufowanym numerem telefonu w celu oszustwa popełnienia przestępstwa. ale to jest jasne, że jak popełniam przestępstwo to przestaje być legalne, ale
dodatkowo mogą nas za to dupnąć. Mając dostęp do sieci SS7, o której wcześniej wspomniałem, mamy możliwość nie tyle spufowania, nie tylko spufowania tych adresów, ale nawet zrobienia tego w taki sposób, że sieć najpierw poprosi mój telefon zamiast faktycznego odbiorcy, ja to połączenie odbiorę i będzie przekazane dalej do faktycznego odbiorcy, a ja sobie siedzę w środku i słucham tej rozmowy. Tutaj szyfrowanie nie występuje. Jakieś pytanie tam było? Czy był jakieś pytanie? Ok, bo machałeś, przepraszam. I teraz tak, usługa spufowania, możemy to zrobić w swoim telefonie, naprawdę, możemy się dostać do sterownika modemu i po prostu poprosić, żeby za każdym razem podawał inny numer telefonu niż faktyczny. To jest troszkę skomplikowane, operacja moim zdaniem nieopłacalna, bo istnieją usługi, gdzie po prostu za mniej niż złotówkę
za minutę połączenia to mamy. Rejestrujemy się, doładowujemy sobie konto i wpisujemy z jakiego numeru chcemy sobie dzwonić. Ja tylko się wydzwoniam na bramkę i to połączenie jest wykonane. Plusem jest to, że to faktycznie nie wychodzi z mojego telefonu, tylko to są często jakieś zagraniczne serwery, więc tutaj znowu namierzenie jest utrudnione. Jeżeli potrzebujemy jakiejś, przepraszam, budzik, jeżeli potrzebujemy wykonać jakąś operację, niekoniecznie nawet nielegalną, ale zwyczajnie jakieś zachowanie prywatności i sprawdzić, kto do nas dzwonił, kto nas męczy, warto z tego korzystać. Nie da się na to oddzwonić, nie da się nas namierzyć. To tyle, spoofing IP, naprawdę mi się już nodiło. Teraz tak, spoofing IP... Temat prosty, chodzi o VPN-y i chodzi o proxy. Tylko sprawa jest taka, żeby proxy nie
używać z tych list 50 najszybszych darmowych proxy. Te serwery są po pierwsze często monitorowane, one są po drugie zbyt łatwo dostępne dla ogółu i te adresy się powielają. Po trzecie...
Po trzecie, będą blokowane na większości serwerów. Na IRCA się często nie połączymy z takiego serwera, bo ma listę proxy, które cały czas spamują, bo tam są niewłaściwe użycia i nas to odblokuje, ale można wejść na Shodana. Znacie, Shodana to jest taki Google urządzeń. Nie wiem, jak to inaczej opisać, możemy sobie wpisać, że chcemy znaleźć wszystkie serwery, które udostępniają taką usługę na tym porcie. Wyrzuci nam listę nawet amatorskich serwerów, o których mało kto wie, bo tam jakiś gimnazjalista sobie po prostu postawił serwer TB czy czegokolwiek innego. I z tego możemy korzystać w miarę bezpieczny sposób. Z legalnością ciężko mi powiedzieć, jak to wygląda, więc nie polecałbym. Oczywiście żadnej z tych technik nie polecam, chcę tylko uświadomić, że takie rzeczy są możliwe. I teraz tak, jeżeli chcemy mieć, bo warto też
mieć swój serwer proxy albo swój serwer VPN-a i warto go mieć w krajach, pytanie? Dlaczego kreę północną lepiej sobie odpuścić? To właśnie zacząłem tłumaczyć. Warto mieć VPN albo własny serwer po prostu proxy. w którym mamy kontrolę, wiemy, że nikt nam tego nie monitoruje, nikt nam się tam nie będzie chciał dostać. Interpol znacie, to jest taka Policja Międzynarodowa, to jest organizacja, która zrzesza wiele krajów i pomaga we współpracy między organami ścigania i innymi. I teraz istnieje kilka krajów, które do Interpolu nie należą, bo jeżeli nawet ktoś w Polsce dokona przestępstwa, które będzie de facto wykonane w innym kraju, tam ten kraj bez problemu może się zwrócić do Polski o udostępnienie pewnych materiałów, pomoc w ściganiu, będzie nawiązana współpraca
między tymi organami. Natomiast w tych krajach, które do Interpolu nie należą, ta sytuacja nie nastąpi. Więc jeżeli mamy tam serwer wykupiony i ktoś będzie się chciał do niego dostać, przykro mi, nie współpracujemy z wami, ta współpraca nie będzie nawiązana. Mamy tutaj Kiribati, to Micronesje, Palau, Palestynę. W Palestynie jest dosyć sporo serwerów i w Tuwalu też dosyć mocno serwerów nie działają. Jest Korea Północna, ale jakby z oczywistych względów, dobrze, Interpol nas nie będzie przeglądał, ale wiemy, kto inny będzie, więc naprawdę jest fakt, że do Interpolu nie należą, ale można to zignorować, tak? Znaczy odpuścić, jak odpuścić. Ja chciałbym zobaczyć kogoś, kto uzyska w ogóle szala na takim serwerze. Ty wiesz, że są tam całkiem mocne podrzemnie, działa się okazuje. W Korei Północnej działa naprawdę spore podrzemnie i takie rzeczy
tam są. To nie są oficjalne serwerownie, że płacimy im w bitcoinach, nie, nie, nie. Ale można tam faktycznie mieć usługi. Nawet ataki z Korei Północnej takie botnetowe wychodzą. Właśnie zrobiłeś mi plan na dzisiejszą noc. No podrzemne. Prywatne, właśnie w tym rzecz, że rządowe to jest jedno, oni mają dosyć mocną cybernetyczną, nie lubię słowa cyber, dosyć mocną armię cybernetyczną mają, niemniej tam działa też prywatne podziemie, często zdalnie, typu Rosjanie sobie tam pewne usługi przekazują itd. Dobrze, pomijając fakt, że trzeba często zmieniać punkty wyjścia, no bo nawet jeżeli mamy swój serwer, nie wiadomo, czy ktoś tam na mnie wejdzie, tak, zero daje istnieją, więc co jakiś czas go resetować, używać kolejnego, nie często wychodzić z tego samego miejsca, bo to się
robi podejrzane. Spoofing e-mail, tak jak mówiłem, to jest absolutnie banalna sprawa, po prostu chodzi o nadpisanie na główkę, ale skoro pokazałem tamte inne rzeczy, to dla formalności chcę też pokazać e-mail. Albański wirus, nie wiem, tak po prostu był pod ręką. Generalnie tak, opcje są dwie. A druga jest dosyć przyjaźniejsza, bo często spotykamy maile, gdzie są bardzo ciężko zrobione. To jest taki filtr, który nam, typu skamy, tak? Jakiś książe nigeryjski do nas pisze, ale robi masę literówek, to w ogóle się kupy nie trzyma. Tak naprawdę to jest zamierzone działanie, bo odfiltrowują ludzi, którzy mają trochę oleju w głowie i którzy się później, później w tej operacji zorientują, że coś jest nie tak i po prostu, żeby na nich od razu czasu nie tracić, odfiltrowują sobie tylko, żeby tacy
idioci że Wybekną coś takiego na początku dalej do nich pisali. Często jest wykorzystywany właśnie ten mechanizm pierwszy, czyli nadpisanie sendera, czyli e-mail, który ja do was wyślę, pokazuje się, że został wysłany z zupełnie prawdziwego, innego maila, ale nikt nie zwraca uwagi na ten kolejny nagłówek, czyli do kogo ma odpowiedzieć, a to jest już mój e-mail, czyli widzimy, że przez normalnego maila chcemy tam odpowiedzieć, ale w rzeczywistość ten mail wraca do mnie na zupełnie inną fejkową skrzynkę. Bardzo prosty mechanizm, często stosowany, Niektórzy pewnie i tak nie kojarzą. Druga opcja to jest troszkę bardziej wysublimowana i trzeba się troszkę bardziej przyłożyć, czyli robimy sobie adres prawie identyczny jak adres ofiary, warto sobie tutaj dodać jakiś certyfikat, żeby jeszcze
wzbudzić jakąś wiarygodność, czyli że to na pewno ofiara pisze, przecież ma wyrobione certyfikaty i pokaza się kłódeczka. Ludzie na to lecą. Jakieś pytanie to masz? Nie, okej, bo ty trzymasz mikrofon, przepraszam cię. To jest to. Ostatnią chyba sekcją są płatności. są bardzo proste. Bitcoin, każdy słyszał o Bitcoinie, tylko pytanie czy ktoś go faktycznie w takim życiu używa. Poza tym, że leży na giełdzie i na siebie zarabia, czy ktoś jest kto płaci Bitcoinem, płaci za usługi Bitcoinem? Nie ma, no właśnie.
Bo sprawa jest taka, że Bitcoin wcale nie jest taki wygodny jak się mówi. W darknecie się sprawdza, bo Wsługi w darknecie nie bardzo mają możliwość dołączenia sobie bramki PayPala, PayU, nawet MasterCardów i tak dalej. Zresztą nikt by tam nie chciał takich danych podawać. Toś tam słabo sprawdza, dlatego używa się Bitcoina, ale poza nim, jakby próbowałem sam osobiście używać Bitcoina, to jest powolne. Jeżeli chcemy dokonać jakiejś bezpiecznej operacji typu podpisana, znaczy wykonana na... na offline'owym urządzeniu, na offline'owym cold wallet, a tylko dołączam do sieci z drugiego, potrzebujemy dwóch urządzeń. To jest naprawdę dosyć upierdliwe, chyba że ma się drogie hardware'owe wallety. Bitcoin, wbrew temu, co się powszechnie myśli, także jest namierzalny wcale nie tak trudno, dosyć
łatwo go namierzyć. Można go wyprać, ale pranie znowu sporo kosztuje, jeżeli chcemy używać go legalnie lub troszkę mniej, niekoniecznie mamy duże środki. Musimy się liczyć z tym, że pranie bitcoinów nie jest gwarancją, a przynosi dosyć spore koszty. No i tak jak powiedziałem, wcale nie jest wygodny, tak jak w darknecie. Zresztą nawet tam wcale się nie tak super sprawdza. Dużo lepszą opcją dla osób, które chcą nas oczywiście zaatakować, to są wykupione z baz typu Willic Info wycieknięte karty kredytowe konta PayPal, bo było kilka breachów PayPalu. Takie konta kosztują grosze, oczywiście są nielegalne chyba w każdym kraju na świecie, północną, jak mniemam. Takie konto, czy karta jest do kupienia na darknecie za około 30 zł, więc to jest w zasadzie
nic. Problemem jest to, że ich użycie jest dosyć skomplikowane. Jeżeli ktoś ma kupione konto PayPala, które jest niewłaściwego pochodzenia, Musimy korzystać, musimy mieć jakieś informacje o tym użytkowniku, skąd on się do tej pory logowo, z jakiego miasta pochodzi w tym miejscu wyszukiwać proxy i przez to się łączy. Jeżeli to jest konto powiedzmy z Hiszpanii, my się połączymy z Polski, PayPal natychmiastowo to namierzy. PayPal ma bardzo silną sieć namierzania takich oszustw. Visa, Mastercard tak samo. Jeżeli operacja pochodzi z jakiegoś nietypowego źródła, od razu się temu przeglądają, bardzo są... na to nastawieni. I teraz tak, kamuflaż, to jest już dobrze, przepraszam, tamto miało być ostatnie, to będzie ostatnie. Kamuflaż, o co chodzi, czasem się zdarzają operacje w
terenie i sprawa jest taka, że wyglądamy jak wyglądamy, w sensie widać po nas, że coś kombinujemy, tak? Każdy z nas ma jakiś taki podejrzany wzrok, podejrzany ubiór. Nie obraźcie się, ale część tutaj wygląda jakby miała terabajt jeszcze dziecięcej pornografii na laptopie. To naprawdę, Teraz tak, o co chodzi? Po pierwsze ubiór, to są porady, które zresztą część z nich wymyślił nawet mitnik. Wydają się banalne, ale o nich się nie myśli, a działają na podświadomość ofiary. Na coś, na co ofiara zwraca uwagę. Musimy ukrywać tatuaże, kolczyki, czasem nawet biżuter, jeżeli jest jakaś nietypowa, bo to się zapamiętnie. To są szczegóły, które wpadają w pamięć. Jeżeli później policja przyjdzie i będzie wypytywała o atakującego, to ofiarcy przypomni miał tatuaż albo miał jakiś taki dziwny medalion, miał cokolwiek innego
dziwnego. Nie nawiązywać kontaktu wzrokowego. Jak przychodzicie przez miasto, nikt na was nie patrzy. Nie róbcie tego samego. W sensie atakując niech nie robią tego samego.
Naklejki zaraz do tego wrócimy. Następnie tak, z tego samego powodu co punkt pierwszy, nie nosić tematycznych ubrań. Nie nosić ubrań z gier, z zespołów, z jakimiś śmiesznymi napisami, Właśnie, to też są rzeczy, które zachodzą w pamięć ofierze. Jeżeli ktoś będzie pytał sekretarki, to ona będzie pamiętać, że był jakoś nietypowo ubrany. Zupełnie neutralne ubranie. Koszula... Całe czarne też wzbudza pewne... Też budza, tak, też wzbudza pewne podejrzenia. Zwykła, jednokolorowa koszulka, zwykłe dżinsy, trampki. Coś, co w ogóle się nikomu nie rzuca w oczy, co nawet nie ma szczegół, który można zapamiętać. Nie rozglądać się za dużo, podobnie. Jeżeli kombinujemy, a gdzie siedzi obok ochrona, Oni zauważą, że patrzymy na kamery, że szukamy jakichkolwiek skrzynek i tak dalej. To się przyda, jeżeli robimy jakieś pentesty na zlecenie oczywiście, bo
też warto jakąś operację w terenie zrobić, tak? Wiesz co, moje doświadczenie z ochroną fizyczną w Polsce gwarantuje ci, że nie zauważą. Gwarantuję to 100%. Wiem, ale nadal. Ok, i teraz tak, nie nosić gadżetów na widoku, co też często robimy podświadomie, gdzieś mamy jakieś kombinerki, ja noszę ze sobą czasami taki mały zestaw krętaków precyzyjnych, standardem są ThinkPady w My Little Pony albo naklejki Gentu, to po prostu od razu się rzuca w oczu, od razu wiadomo, że coś jest nie tak. Słuchawki w uszach też często warto mieć, bo to jest standard u ludzi. Teraz każdy chodzi ze słuchawkami, robimy dokładnie to samo. Kolorowe ubrania, tak jak powiedziałem wcześniej, samo czarne ubranie albo samo białe też jest jakąś dziwną rzeczą, pewną anomalią w
otoczeniu. Na to też się zwraca uwagę, także sorry. Dalej co? Przebrania. PEN-testy, jeżeli mamy naprawdę dryg i lubimy robić te PEN-testy, wielu ludzi lubi robić operacje w terenie, warto mieć jakiś taki zestaw oczywiście legalnego źródła przebrań.
Każdy ma swoje plusy dodatnie i plusy ujemne. Na pewno bardzo dużo nam daje zwykły strój sprzątacza, dlatego że ludzie nie bardzo chcą patrzeć na sprzątaczy. Większość czuje się lepsi, lepszymi od takiego zwykłego sprzątacza czy sprzątaczki, nie chcą ich krępować swoją obecność, po prostu unikają wzrokiem, nawet nie patrzą, co ta osoba robi, a jednocześnie obecność sprzątacza czy sprzątaczki w żadnym miejscu nie dziwi. Jeżeli wchodzi do serwerowni z mopem, spoko, wchodzi, musi tam cokolwiek zrobić. Spróbujcie wpuścić kogoś, kto przywozi jedzenie, z Uber, Itza czy czegokolwiek. To się od razu rzuca w oczy. Sam fakt bycia sprzątaczem to jest jedna wielka przepustka. Oczywiście problemem jest to, że trzeba nosić jakieś wiaderko czy coś, bo sam fartuszek niekoniecznie tutaj się nada. Kurier. Stroje kurierów są dosyć łatwe do zdobycia. Można je legalnie nosić,
więc nie ma w tym nic złego. A ich plusem jest to, że jeżeli stoimy przy recepcji, to wywiera pewną presję na ofierze. Jeżeli tej paczki, która jest zaadresowana powiedzmy do szefa czy do jakiegoś działu, nie dostarczę je na czas albo przyjadę z nią jutro, ktoś będzie miał problemy, to będzie prawdopodobnie ona. To wybiera taką podświadomą presję, że my i tak koniec końców, mimo że nie powinniśmy, możemy tam wejść. Strój kuriera działa. Strój policji często używany, ale w sumie nic nie daje się prawdopodobnie. Będziemy zbesztani za to, że w ogóle istniejemy, więc tego bym unikał. Ochrona. Ochrona. To się może przydać z tej przyczyny, że jakby też nam nie daje wyjątkowych uprawnień, ale jeżeli nam się powinien noga czy cokolwiek innego, ofiara, pierwsze co zrobi, zadzwoni po ochronę,
ale ochrona stoi przed nią, nigdzie nie zadzwoni. Mamy tutaj takie dodatkowe jakby drugie życie, tak? Możemy coś jeszcze wykombinować. I druga sprawa, dobry garnitur, naprawdę dobry garnitur, zrobiony na miarę, często budzi peszy ludzi. jakby nikt się nie będzie kłócił z kimś, kto wygląda na milionera, czy choćby prezesa jakiejś firmy. Z takimi ludźmi się nikt nie kłóci, bo oni prawdopodobnie mogą być nawet szefem tego biura, o którym my nie wiemy. Kto zna swojego szefa? W sensie dobra, okej, faktycznie możecie znać. Ja nie znałem, przez długi czas nie wiem, zielonego pojęcia nawet jak wygląda. I generalnie, gdyby ktoś w jakimś drogim garniturze powiedział mi, że on mnie zaraz wolnie, jeżeli go nie wpuszczę, to bym go nie
wpuścił, ale wiele osób by go wpuściło. I to będzie wszystko w takim razie. Dziękuję za wysłuchanie, to byłem ja, Dariusz Jakubowski.
Okej, dziękuję. Myślę, że jeszcze pytania. No właśnie, pytania?
Naprawdę nic, myślałem, że z takiej ilości coś ktoś... No dobra, jak nie to chyba...
W zasadzie tak, budowlaniec nie pomyślałem o tym, budowlaniec to też byłaby dobra opcja, hydraulik coś takiego. Prawda, masz zupełną rację. Wiertarka jest lepsza, bardziej poręczna, przecież musimy konserwować. Wydaje mi się, że drabina by wzbudza większe zaufanie. Większe, ale jakby drabinę się widzi często po biurowcach, zwykłą lampę wymienić, bo widzisz, ktoś to wierci, co będzie wiercił, a lampy co chwila się przepalają. Na YouTube jest taki filmik, koled z drabiną chodzi po różnych biurach, wszędzie sobie wchodzi, nagrywa. Prawda? To przebranie daje dużo. To przebranie naprawdę daje dużo. Jesteśmy zupełnie jako służbiści, nie jesteśmy w ogóle kontrolowani.
Taka anegdota właśnie z ochrony fizycznej wyciągnięta. Jeden z pracowników ochrony sprzedał mi taką opowieść. W latach 80. końcówka do jego mieszkania przyszedł pan, stwierdził, że przyszedł naprawiać Junkers. No i że był u sąsiadki i naprawia piecyk. Po chwili patrzy ten pracownik do jego torba, tam tylko młotek i kawałek piłki do metalu. Pyta sąsiadki z góry, czy był. No panie, przyszedł, mówi, że był u pana. Więc facet chodził po klatkach, obczają mieszkania w ten sposób mówiąc, że byłem sprzedał wyżej, niżej. Tak, nie bardzo dobry, Karczak. Tak, jak mówiłeś. Tylko, że niedopracowany, bo sam młotek tak miał. Trzeba myśleć, to nikt tego za nas nie zrobi. Dobra, ktoś chyba jeszcze podnosił rękę? Przeczanie się za ochronę może być czasem ryzykowne ze względu na to, że czasem ochrona się zna.
ludzie kojarzą te osoby. To jest jasne, to jest jasne. W stroju kuriera też nie wejdziemy do firmy kurierskiej, prawda? Więc najpierw się robi rozeznanie bez czegokolwiek, czyli to jest taki zupełnie neutralny ubiór, rozeznajemy się, jak to wszystko wygląda, a później obmyślamy scenariusz, które przebranie będzie najlepsze. Jeszcze taki jeden bajer. Kurierzy są względnie stali i ochrona zna kurierów, więc jak się pojawia nowa osoba, zapytają, ty, a gdzie jest Tomek, Kamil czy tam nie wiem, jak go tam nazwijmy. Nie głupie, ale można z tego łatwo wypronąć, dokładnie. Często mam stycznię z ochronami na poziomie osiedli i jest taka sytuacja, pojawia się nowy kurier, nowy pan kanapka i ta osoba jest naprawdę sprawdzana. Ale chciałbym zauważyć to, że
skoro ta sytuacja się pojawia, to znaczy, że ktoś faktycznie mógł tego wykorzystywać. Znaczy mógł to wykorzystać. Tak. Że takie sytuacje się dzieją, dokładnie. Więc jest to fakt.
Super, wszystko? Dobra, to zapraszam na lunch. W takim razie smacznego Wam życzę. Teraz mamy półtora godzinną przerwę. Proponuję opuścić salę ze względu na to, że znowu tu się zrobi za gorąco. I tak, jeżeli chodzi o prelegentów, to na dole będzie jedzonko od godziny 13. Do tej pory może każdy sobie iść, nie wiem, na kawę, na piwko, cokolwiek. Spotykamy się za półtora godziny w tej sali. Dzięki bardzo.
I need to stay put? Yes, because the camera doesn't move. So, as long as you stay here, fine. Yeah, that'll be a problem. You can breathe. Let's try and do that. You can point if you need to. They have three songs. Okay.
My signal.
więc czy możemy już zaczynać? Osoby z dołu proszone są o podejście do góry, jak jeszcze ktoś jest. Jeszcze rzeczy technicznych, czasami mówiliście tam z tyłu, że nic nie słychać. Niestety jak ktoś tu podszedł, to widział, że to jest na full. Po prostu prosimy prelegentów, aby bliżej trzymali mikrofon. Dobrze. Okej, także możemy już zaczynać. Maku, do dzieła. Także tego, no, witam po obiedzie, był, nie wiem, czy dla Państwa dobry, dla mnie całkiem okej. Ja powiem o dziwnych rzeczach. Problem jest taki, że przez to, że właśnie zmieniliśmy konfigurację, ja nic nie widzę na swoich slajdach, więc będę znowu, zobaczymy co z tego wyjdzie. Jeżeli ktoś mnie nie zna, to ja się nazywam Maciej Kotowicz, pracuję w CERCie jeszcze, zajmuję się dziwnymi rzeczami
związanymi z analizą malwareu, tak ponieważ wszystko teraz będzie szło do wojska, w związku z czym pewnie nie będzie już całego świata. Zajmuję się głównie analizą malwareu, eksploitacją, gramą w Dragon Sector, którego chyba nawet nie napisałem, napisałem. takie inne pierdoły. Jak wszyscy dobrze wiemy internet to jest bardzo niebezpieczne miejsce, prawda, jakieś trojany, wormy, spamy, no jedną z rzeczy, którą ja się zajmuję jest jakby wyszukiwanie tego wszystkiego i sprawdzanie, dowiedzenie się czy to jest faktycznie niebezpieczne i dużo zer, patrzysz na te bajty, zazwyczaj wygląda to tak, że jest dużo okienek, tam są jakieś kody, zróbmy jakieś małe, może zgadywanie, ktoś zajmował się analizą malwareu, ktoś wie o czym ja będę mówił, Pójść po prostu. To ja może jednak sobie pójdę, co?
No dobrze, to jeżeli ktoś się nie zajmował i nie ma pojęcia, o czym chodzi w rewersowaniu, no to to będzie faktycznie dziwna prezentacja, ale spróbujemy coś z tym zrobić. Ja mam na to godzinę, godzina to nie będę starał się święcić, poświęcić, ponieważ osoba po mnie ma milion slajdów i będzie zajmować się tym dłużej niż ja. Tak jak jak mówiłem, to jest dziwna praca, analizowanie malwareu, to jest zrobienie tego samego w kółko i w kółko i w kółko i w kółko i w kółko, ale jak jest napisane za to pewno, prawda, to się nie skończy w najbliższym czas, malware jest czymś co jakby rośnie, daje z tego coraz więcej, jest powiedziałbym, że coraz bardziej ciekawy, coraz bardziej skomplikowany, ale to gówno prawda, jest cały czas tak samo nudny i o
tym będzie ta prezentacja, iść z tego samego w kółko i postarać sobie ułatwić życie, przepraszam, to jest strasznie gorąco, pozwolę się trochę rozebrać.
I się wszystko wyłączyło. Ok, dobra. I to, o czym ja będę mówił, to jest szeroko pojęte diffowanie kodu, szukanie podobieństw i różnic w nim, żeby ułatwić sobie życie, żeby nie analizować tego samego w kółko i na okrągło. Te metody, o których ja będę mówił są przydatne głównie do tego, ale też są używane w czymś takim jak atrybucja, każdy pamięta ten obrazek prawdopodobnie, mam nadzieję, przynajmniej nie chcę się nie mówić, bo był bardzo nudny, przynajmniej dla mnie, ale co jest ważne to jest atrybucja, czyli próba powiedzenia, że coś należy do czego, ktoś zrobił coś, ktoś jest na coś odpowiedzialny, no i jedną właśnie z tych głównych metod, których się teraz używa to jest podobieństwo kodu, plus oczywiście podobieństwo architektury i tak dalej
i tak dalej i żeby Was przekonać, że to jednak trochę działa to ja spróbuję zrobić jakieś małe demo, które pewnie nie wyjdzie, ale zobaczmy co z tego wyjdzie.
strasznie kurwa dziwne. Ja to jednak wezmę ze sobą, spróbujmy to. O, łupanie, technologia się zmienia. Pamiętam jak zaczynało się z takiej pięknej sali, czy to było na Politechnice, tak? Gdzie nie było dosłownie nic.
I dało radę. To co tutaj widać,
To co tu widać to jest jakiś kawałek ID z jakimś kawałkiem malwareu, który jest świeżo załadowany, ja go kiedyś analizowałem, ale to oczywiście jest strasznie nudne, więc modujemy taki kolejny raz z rzędu, dużo funkcji, dużo nie wiadomo o co chodzi, więc postaram sobie to życie trochę ułatwić przez dziwne rzeczy, o których będę mówił potem jak działają.
Ja to mam.
skrót jednoliterowy, po co nazywać pewnymi rzeczami.
A, to tak nie działa. Ten skrypt, którego ja teraz używam jest dość stary, a AIDA jest nowa, więc to oczywiście nie działa tak, jak powinno, ale spróbujemy.
Przewierzcie mi, patrz jak się jest ślepy. A, jest. Połowa sukcesu.
Coś się stało. Coś się stało, coś się zrewersowało. to już trochę nam ułatwia życie, prawda, jeżeli rewersujemy sobie coś wcześniej, a wiadomo, tak jak mówiłem, ta praca jest bardzo powtarzalna, więc cały czas rewersujemy tak naprawdę to samo.
Więc jeżeli jesteśmy w stanie sobie przygotować jakieś informacje wcześniej, jesteśmy w stanie odtworzyć tę naszą poprzednią pracę, która wbrew pozorom nie jest to takie łatwe, żeby pokazać, że jakaś funkcja jest tą samą funkcją, albo chociaż podobną. techniki, o których będę mówił postarają się Wam przybliżyć jak zaimplementować, jak podejść do problemu, nie rewersowania tego samego poprzez zapisywanie swojej pracy i odtwarzanie jej kółko. Tak, więc może widać, że jakieś, nie wiem czy tu widać cokolwiek tam po lewej stronie? Okienko zmniejszyć. To czekaj, zróbmy tak, o, tak będzie lepiej, tak? Widać, że jakieś funkcje się nowe pojawiły, one mają jakieś nazwy, więc nie musimy o nich się przejmować, bo to ufamy swojej poprzedniej pracy oczywiście, że zrobiliśmy ją dobrze i to, że to się nazywa ASINIT,
to jest ASINIT, a nie wysłać powietrze najbliższą elektrownię atomową. No wiadomo, no, jedno może robić i drugie i to jest jedno i takie i takie. To są jakieś proste sygnatury, które to robią, to jest niestety ma swoje wady, o których będę mówił później, to narzędzie samo, ale na razie widać, że coś tam działa i coś możemy sobie ułatwić trochę życie. zrobić coś jeszcze śmieszniejszego, nie wiem czy to zadziała, to miała być atrybucja, która nie zadziała.
Dobra, nie ważne, nic nie widzę, co się dzieje na moim komputerze, walcz to, spróbujemy może później. Więc jakby nie pomodliliśmy się dobrze i chuj z tego wyszło, to ja się napiję.
Przestraciłem swoje slajdy, nie wiem, gdzie są, o tu są. Okej, dobra, to to były jakieś sygnatury, tak i wszyscy twierdzą, że sygnatury są martwe, a V jest martwe i to wszystko gówno daje i teraz trzeba iść w, co tam jest nowe, machine learning, tak, machine learning, wielkie daty, behawioralne analizy, powłamanie, cokolwiek, wymyślmy sobie jakieś teksty i coś z tego wyjdzie. Oczywiście ja twierdzę, że sygnatury nie są wcale martwe, są całkiem dobre, problem jest taki, że trzeba wybrać o czym upieramy te sygnatury. Tak i przede wszystkim mamy źródła tych sygnatur i te sygnatury możemy zrobić na podstawie bajtów i to jest to, o czym ludzie mówią, że to nie żyje, bo nie da się, bo malware jest
dynamiczny, jest spakowany, modyfikuje się sam, robi nam herbatę w locie albo komuś innemu, ewentualnie laskę, zależy od tego jak bardzo teksistowskie chcemy robić prezentacje.
i tak dalej, ale możemy wybrać pewne cechy charakterystyczne dla na przykład funkcji, które znajdują się w tym malwareze i na podstawie nich budować jakieś sygnatury, które nam powiedzą, że okej, ta funkcja ma takie, takie właściwości i skoro definiujemy je poprawnie, no to jeżeli ta druga funkcja ma takie same właściwości, no to duże prawdopodobieństwo to jest ta sama sygnatura, to jest ta sama funkcja. No i takie cechy to może być oczywiście desymblacja tego kodu, mogą być jakieś stałe użyte, tak, tak na przykład jak tam jest to może zrobić łopatologicznie.
Spróbujmy na jeszcze samym.
kod to nie zadziała, no dobra, nieważne. Tak, jeżeli mamy jakieś operacje zwyczaj kryptograficzne, na przykład inicjalizowanie funkcji haszujących, to one mają pewne stałe, w których bardzo łatwy sposób poznać czym jest dana funkcja, no jeżeli te stałe się powtarzają, to że zbudujemy sygnatury bazujące o te stałe, to ona będzie całkiem porządna,
na przykład nie wiem, możemy spróbować zrobić za piwo, kto mi jest w stanie wyrecytować stałe do MD5? Redford, dasz radę? To jest proste. Nie wiem, ja tu tylko stoję.
I z powrotem. Ale oni wiedzą, więc nie będę dawał im piwo, bo to bez sensu. Więc to była tylko zachęta, żeby ktoś inny się odezwał, ale skoro innego nie było, to trudno. Jedziemy dalej. Tak referencje do jakichś stringów, do jakichś tablic, rzeczy, które są unikalne dla danej funkcji, wiadomo, że jeżeli dana funkcja referencuje jakieś tablice to on coś z nimi chce zrobić, w związku z czym to jest taka dobra charakterystyka jej. Możemy zauważyć, spróbować, oszacować jak bardzo skomplikowana jest ta funkcja, tak jest coś co nazywa się cyclomatic complexity, ja tam powiem jak to się liczy chwilę później, to jest jakaś z teorii grafów, w tym tremencie teorii grafów, której ja nie mam pojęcia zielonego już od dłuższego czasu, ale spróbujemy coś o
tym temat mówić. Funkcje oczywiście tworzą, jeżeli przedstawimy je jako coś co nazywa się control flow graph, tak, czyli jakby graf przepływu kontroli, no to mają, tworzą jak, skoro nazywa się graf to jest to graf oczywiście, więc możemy oszacować sobie jakoś ten graf i powiedzieć coś o nim
o jego kształcie czy o liczbie nodów czy połączeń.
Dużo, bardzo dużo o charakterystyce funkcji mówi to, jakie inne funkcje on wywołuje oraz jakie inne polecenia systemu, apicola, jakich innych apicoli używa, o tym jest też cały spory research odnośnie samej próby do szacowania co dana funkcja robi bazując tylko na funkcjach systemowych, tak? Pytanie było takie czy są gotowe bazy takich charakterystyk, ja powiedziałem, że są i trochę okłamałem tak naprawdę, są, są jako dodatki do narzędzi czasami, przy czym oczywiście bazują na danym narzędzie, w związku z czym bazy są dotacowane narzędzi, sama AIDA przychodzi z jakąś ilością wzorców, nazywa się to FLIRT i pozwala głównie mówić o bibliotekach podstawowych danego środowiska, np. runtime Delphi, runtime C, Windowsa, whatever, to są bardzo proste tyknatury, więc one działają tak mniej więcej,
było trochę projektów, o których ja będę mówił na końcu tylko na samych narzędziach, żeby, dojdziemy do tego, ale tych baz za dużo nie ma, a zazwyczaj po prostu buduje się je samemu i na tym się bazuje.
i teraz mając pewne charakterystyki, mając te bajty, możemy definiować te sygnatury w jakiejś formie, najbardziej oczywista jest oczywiście, to nie jest mój dobry dzień, najbardziej oczywista jest forma po prostu taka jeżeli chodzi o poszukiwanie bajtów, to jeżeli weźmiemy sobie bajty należące do danej funkcji, będziemy szukać tych bajtów, znajdziemy te bajty, jeb, mamy tą funkcję, tak, no to jest to procedowa pewność, że to jest dokładnie to. Szukanie bajtów jest zajebiście spowolne, więc to nie działa dobrze. Możemy z tego robić jakieś hasze, więc szukać wtedy zakładając, że danych funkcja haszująca jest poprawna, powiedzmy, że md5, sh1, sh256, whatever, whatever jest na tyle szybka, żeby porównywać, na tyle że możemy powiedzieć, że jeżeli coś ma dany hash, no to to jest dokładnie co te bajty,
no i możemy budować jakieś wzorce, tak, jeżeli chodzi o same bajty, czyli nie wiem, regeksy, które mówią, że no te bajty tutaj mogą być takie, może być ich 20, to wpływa na wielkość sygnatury, na dokładność jej i tego inne rzeczy, no i tak naprawdę to samo możemy też zastosować do charakterystyk, tak, możemy budować sobie pewną charakterystykę funkcji i ją zahaszować w jakiś sposób, i pozwoli nam w sposób w miarę szybki wyszukiwać naszą bazę, którą kiedyś zbudujemy.
Jedną z metod jest budowanie engramów, to jest jedna z pierwszych miejsc, w których ja nie mam pojęcia, o czym będę mówił, potem będziemy iść tak dalej i dalej, ja będę teraz mniej wiedział, o co chodzi, ponieważ w tym roku postanowiłem, że się czegoś nauczę, a nie będę pokazywał tego, co robiłem przez jakiś czas i zrobię coś, o czym nie mam pojęcia, ja się tego uczyłem wczoraj, Wy się uczycie tego dzisiaj, może się nauczymy tego razem do jutra. N-gramy znajdziecie wszędzie tam, gdzie macie do czynienia z jakimkolwiek machine learningiem, czyli w tym momencie wszędzie, tak? Prawdopodobnie, jeżeli będziecie chcieli zamówić kawę ze Starbucksa, czy gdzie tam się teraz zamawia kawę, to będzie to robione przez machine learning i będą te kawy dzielić na N-gramy i wysyłać Wam
pojedyncze bajty. Idea jest taka, że po prostu bierzemy bardzo piękne słowo n-gram, które o niczym nie mówi, bo chodzi o to, że po prostu bierzemy kolejny ciąg długości n, poczynając od każdego kolejnego bajtu i przez to możemy nie wyszukiwać miliona bajtów, tylko powiedzmy pół miliona. Super odkrycie, ale na tym najwyraźniej można napuścić setki obliczeń i nie wiem, Tesla będzie tak działać.
Możemy robić to na bajtach, możemy robić to też na mnemonikach, tak, czyli jeżeli zasymbolujemy sobie funkcję, no to możemy mieć ciąg tych mnemoników i na nich operować i to też jakoś tam działa. Na tym też się buduje sygnatury i głównie właśnie machine learningowa, ponieważ ja trochę gardzę tym pomysłem, więc tak tylko mówię, żeby była kompletność, żeby cokolwiek tego używać. Aczkolwiek na N-gramach bazuje wspomniana wcześniej technologia FLIRT, tak, jak Ida, czy ludzie z Hexrace'a, czyli rozwija i DEPRO i Dekompilatory Hexrace, tworzy te sygnatury patrząc na pierwsze 20-30 bajtów, nie pamiętam dokładnie ile funkcji i na podstawie tego buduje sobie sygnatury, tak, jeżeli funkcja zaczyna się 30 takimi bajtami, no to to prawdopodobnie jest whatever co nam wyjdzie, no możecie się domyślić,
że to nie działa do końca dobrze. Troszkę lepszym pomysłem jest maskowanie, zmaskowanie kodu przede wszystkim, tak mając jakiś prosty kod z jakiegoś losowego miejsca w jakimś losowym malwareze widzimy, że on wygląda tak. Widzimy? Widzimy. To co na przykład, tu powinno być takie rzeczy, o, o, technologia. To co tutaj jest na przykład zależne bardzo od kompilatora to jest oczywiście ustawienie rejestrów, ustawienie zmiennych na stosie, w związku z czym to są rzeczy, które mogą, no i te call'e, jeżeli rozważamy tylko binarne, bazujące na bajtach sygnatury, no to to nam nic nie powie, ponieważ same bajt oczywiście nie ma informacji, że to jest call do open process, czy czegokolwiek innego, tylko po prostu ileś bajtów, które mówią, że w tym miejscu będziemy skakać. Więc to co
możemy z tym zrobić, żeby to było troszkę bardziej generyczne, to możemy wymaskować trochę tych bitów, trochę tych wartości, które są przede wszystkim, czyli właśnie offsety
do zmiennych na stosie, do adresy, do których będą robione odwołania, inne jumpy, tak, rzeczy, które są zależne tylko od jakby bajtów, a nie mówią o kształcie tego, co będzie wyglądać, jak wygląda dana funkcja. Kto się idealnie nadaje to jest Yara, to jest chyba jedyna rzecz, te dwa slajdy to jest jedyna moja praca włożona, w sensie taka fizyczna kodowania w tą prezentację, tak możemy sobie wygenerować pewien template, który będzie odpowiadał temu co tam się stało, no i potem sobie to wszystko ładnie zdasemblować, podstawiając tam gdzie są rejestry, różne gdzie są jakieś zmienne rejestrowe postawiając rejestr
i dając wildcard tam, gdzie nie wiemy jakie bajty powinny występować, no i wygenerować sobie taki ładny ciąg, który mówi, że no okej ten kod to jest ten kod. Może wróćmy, ktoś nie wie co to jest Yara, ktoś nie wie, Yara to jest takie narzędzie do przeszuki, matchowania wzorców do bajtów, tak. całkiem sensowna, zaprojektowana przez ludzi z VirusTotala, potem kupiona przez Google razem z VirusTotala, więc już ma sukces w nazwie, prawda, bo Google jara czy cokolwiek i to działa całkiem dobrze, tak, to jest całkiem sensowny język, on pozwala na to, na matchowanie na poziomie nibli, czyli 8 bitów, nie, wiecie o co chodzi.
z jakąś inną architekturę, no to akurat nie, no bo to działa dla konkretnej architektury, tak masz inne bajty zupełnie, bo mam inne instrukcje. Do rzeczy, które działają na cross, czyli przeciwko cross-kompilacji dojdziemy za chwilę do takich bardziej mądrych, czyli teorii grafów, ja wtedy wyjdę, ale to jest bardzo proste, to jest coś, czego ja używam na przykład do budowania swoich sygnatur, które służą mi po to, żeby znaleźć konkretną lokalizację w kodzie przy narzędziach, których używamy, żeby wyciągać informacje o malwareze automatycznie i to jest na tyle dobre, bo wiemy o co chodzi, wiemy czego szukamy dokładnie i po prostu chcemy do tego dotrzeć dokładnie do tego kawałka kodu, więc używanie tego, żeby mówić, że dana funkcja jest dla całych funkcji jest trochę
nieoptymalne, przede wszystkim bo są wielkie sygnatory, bo kodu jest dużo funkcji, no ale do jakichś prostych takich patternów to się nadaje bardzo fajnie, i można to dość dużo wyrazić, ponieważ nie tyle możemy powiedzieć, czy dane bajty się dopasowują, tylko mamy cały język logiczny na tym, jara jest ogólnie fajna, polecam. Być może w internecie można znaleźć człowieka, który zrobił całą prezentację powerpointową tylko w jarze, który się mówił o jarze nie mając nic niejednego tylko jara, odpalił jarę i leciały mu slajdy. Trochę o som.
Tak, trochę o haszowaniu, z metod haszowania jest, cech oczywiście jest coś co nazywa się small prime product, zostało wymyślone, nie wiem gdzie, ale tak naprawdę po raz pierwszy chyba użyte przez ludzi z Dynamics, a tu obecnie Google'a znowu, nie wiem czemu się to wszędzie powtarza Google, to nie jest sponsorska prezentacja wbrew pozorom, ale jest to bardzo fajna technika pozwalająca na ominięcie problemu
sharing instruction, tego, że instrukcje po przekompilowaniu danego kodu źródłowego będą znajdowały się, wyglądały trochę inaczej. To co tu robimy, no to bierzemy jakąś charakterystykę w tym wypadku, do którego to zostało użyte, bierzemy mnemoniki, każdemu mnemonikowi przypisujemy jakąś liczbę pierwszą, żeby mieć unikalne cechy i po prostu je mnożymy, tak, mnożenie jest przemienne czy coś tam, coś tam, więc nie ma znaczenia z której strony, więc nie ma znaczenia jak będą ułożone instrukcje, wartość będzie taka sama, tak. Dla dobrych cech, czyli właśnie na przykład mnemoników to daje całkiem dużą dokładność, możemy to zastosować też nie tylko na mnemonikach, możemy na przykład zastosować na AST danej funkcji, więc to jest coś całkiem uniwersalnego, możemy pójść trochę dalej niż sam assembler
i to jest przede wszystkim jakby podstawa powiedzenia, że dany basic block to jest dany basic block, tak, czyli jeżeli weźmiemy sobie CFG danej funkcji, no to będziemy mieli jakiś przepływ, to co nas interesuje muszę Pan coś mówić, bo widzę, że Pan dobrze śpi. Przepraszam. Ale rozumiem braki snu, więc jakby podzielam problem, też bym się chętnie pospał. A Adrem, tak to nam może, z dużą dokładnością pokazać, że dany Basic Block jest unikalny, jest tym, czego szukamy i będzie to wykorzystywane za chwilę. Co my tam mamy dalej? Dalej mamy Cyclomatic Complexity, o czym mówiłem, tak, to jest jakaś miara skomplikowalności kodu. To jest prosta metryka, po prostu bierzemy sobie graf, liczymy jego wszystkie krawędzi, jego wszystkie wierzchołki
i robimy rzeczy. W IDA Pythonie możemy wyrazić to w 5-6 linijkach. Jasne,
Basic block jest wierzchołkiem, krawędzią są przejścia, czyli skoki warunkowe, niewarunkowe, być może faktycznie powinienem wrócić do początków, o czym ja w ogóle mówię. Każdy z tego założyłem, że każdy wiedział, o co chodzi, pewnie źle. Tak, więc koszyntona mówi, jak bardzo skomplikowany jest graph, to wykorzystuje się oczywiście nie tylko przy tym, o czym ja mówię, tylko też przy ogólnym budowaniu metryk przede wszystkim koliżu główego tak naprawdę, dopiero potem ktoś padł na pomysł, a weszłym co to gdzieś indziej. i zobaczymy, o co chodzi, możemy tego też używać po to, żeby zacząć w ogóle jakby analizę malwareu, bo jak zostaniemy malware, no to jest z tego dużo kodu, dużo funkcji, nie bardzo wiemy do czego zacząć, a jak doświadczenie albo moje poprzednie prezentacje, albo czyjeś
inne mówią, że warto zacząć od miejsca, które są skomplikowane, czyli nie wiem jakaś kryptografia,
ogólnie jeżeli coś jest skomplikowane, znaczy coś ciekawego się tam dzieje, więc warto rzucić tam okiem, być może coś fajnego znajdziemy. też tak naprawdę dotyczy nie tyle co przy analizie malwareu, ale też przy szukaniu błędów, bo całe wszystko to, o czym mówię, to jakby używanie tego do analizy malwareu jest rzeczą drugorzędną, dużo więcej w internecie znajdziecie, jeżeli będziecie szukać o patch diffingu samym, czyli diffowaniu patchy, czyli najprościej mówiąc, bierzemy załatany błąd, bierzemy wersję poprzednią, diffujemy, patrzymy, a zmieniły się 3 bajty, no to znaczy, że tu jest być może był błąd, spróbujmy coś zrobić, żeby to triggerować, tak, i takie jest główne wykorzystanie, dopiero niedawno ludzie zaczęli zastanawiać się, że no może by jednak chce coś ułatwić innymi rzeczami. Tak nie jest tak, że romantic
complexity może być użyte też do tego, żeby zacząć w ogóle rewersowanie, bierzemy coś, co jest skomplikowane i patrzymy, co tam się dzieje, być może jest to ciekawa funkcja pod względem malwareu, być może jest to ciekawe, ponieważ jest coś ciekawe pod względem szukania błędów, bo no wiadomo, podobieństwo jest, że w skomplikowanym kodzie z więcej błędów jest dużo większe niż mniejsze. I teraz trochę magii. Ja muszę się napić, bo to będzie trudne.
Tak jak mówiłem, tu będzie trochę więcej teorii grafów, o której to jakby zahacza te moje czasy późnego liceum, wczesnej szkoły, które były bardzo dawno temu, kiedy byłem grzecznym chłopcem i nie tak bardzo nie chodziłem na konferencję, więc teraz będzie trochę magii znowu od ludzi z Dynamicsa i to było nie wiem, wymyślone 10 lat temu i od tej pory nikt nie wymyśli dużo nic lepszego, to jest pewna forma wyrażania charakterystyk, spłaszczania grafu po to, żebym, bo z grafem jest taki problem, że bardzo ciężko się go wyszukuje, tak, że musimy mieć jakąś formę, no nie możemy zapytać się za bardzo bazy, i te rzeczy, które wyglądają jak ten graf, tak? Bardziej możemy zapytać szybko o jakieś inty, w najgorszym wypadku stringi, inty są idealne, więc będziemy się pytać o inty.
Tak jak mówiłem, jest to dekonstrukcja grafu do jakiejś krotki, krotka wygląda tak.
W najprostszej formie to jest, bierzemy krawędzie danego grafu i zastanawiamy się jakie są jego charakterystyki. co możemy powiedzieć o krawędzie, o krawędzie możemy powiedzieć to, ile jej wierzchołki, które łączy, mają wejść i wyjść, co jeszcze, ponieważ mówimy o Basic Blockach, tak, to chcemy też, to nam tak naprawdę jeszcze porządek, jeżeli zrobimy sobie jakiś porządek na tych grafach, to zazwyczaj to jest jakiś porządek topologiczny, co teraz już przechodzi moją możliwość, ale chodzi o to, że chcemy mieć graf posortowany ciągiem wejść-wyjść, czyli na samym końcu będziemy mieli graf, który jakby jest, nie ma żadnych wyjść, a na początku będziemy mieli taki node, który nie ma żadnych wejść, tak, czyli zaczniemy od wejścia funkcji, kończymy tak naprawdę na recie. No i teraz jeżeli
będziemy mieli ilość wejść-wyjść dla każdego z wierzchołków danej krawędzi ich porządek topologiczny, to to nam bardzo dużo już mówi o tym jak ten graf wygląda. To jest oczywiście dużo, ale niewystarczająco, ponieważ możemy mieć bardzo dużo funkcji, które będą miały dokładnie ten sam kształt, a będą miały zupełnie inne właściwości, więc do tego jeszcze dorzucamy charakterystykę basic bloku, czyli wierzchołków, czyli w tym wypadku na przykład właśnie to mnożenie tych pierwszych bazujących na mnemonikach w danym Basic Bloku. Do tego możemy sobie coś tam jeszcze dorzucić, tylko nie wiem co, aha, tu jest jeszcze dorzucona jakaś liczba coli, która jest w danym Basic Bloku, z każdej strony oczywiście. No i tu są jakieś krotki, krotki są fajne, krotki są już dużo prostsze niż grafy, dalej nie są to liczby,
najwyraźniej są magiczne metody matematyczne usadzania krotek w liczbach rzeczywistych i to jest mnożenie pozycji krotki przez liczbę w z pierwiastek z i, gdzie i to jest numer pozycji w krotce, tak.
Ktoś zrozumiał? Ja też nie, ale działa. Nie, no jest to bardzo proste, tak, bierzemy po prostu każdą wartość z tego i mnożymy to razy, jeżeli powiedzmy, pierwiastek razy, pierwiastek z dwóch, pierwiastek z trzech i tak dalej, i tak dalej, czy pierwiastek, przepraszam, pierwiastek z liczby pierwszej miał być, czy coś koło tego, do znalezienia w internecie. Tak i to nam daje jakąś liczbę i ta liczba jest najwyraźniej całkiem fajna i jest na tyle unikalna, że reprezentuje dokładnie to, co chcemy i mając to, to nie tyle ale najwyraźniej ma jeszcze taką fajną właściwość, że pozwala zdekomponować to z powrotem do grafu, ale o tym już nie będę mówił, bo to jest skomplikowane i nie mam pojęcia zupełnie o tym, więc zostało to wybrane i te dwie rzeczy, czy naprawdę to jest
jakby podstawą tego narzędzia Bindi, które jest bardzo znane dla ludzi, którzy zajmują się vulnerability researchem albo analizą malwareu, jest też podstawą wszystkich tych narzędzi, które Dynamis kiedyś stworzył, czyli VxClass i Bincrowed i co oni tam jeszcze, poza Binnavi oczywiście, bo Binnavi jest czymś innym, związany tylko z analizą grafów, ale też jest jakby częścią tego całego codebase'u, który przejął Google. Prawdopodobnie da się zrobić trochę więcej na tych grafach, problem jest taki, że jeżeli ktokolwiek cokolwiek wie o grafach, to izomorfizm grafów jest trudny, czyli wyszukiwanie grafów takich samych,
które da się przekształcić w dany graf, tak, nie wiadomo czym jest izomorfizm, jest to problemem NP-zupełnym, co oznacza, że jest może trudne. Wyszukiwanie podgrafów, grafy też jest trudne, więc nawet nie jesteśmy zbytnio w stanie powiedzieć, że coś jest częścią danego podgrafu, tak ogólnie coś tam jeszcze innego, podobieństwa tych grafów też są trudne, ogólnie grafy są trudne, ja nie wiem, więc to jakby jest wszystko fajne, ale niestety poza tym, że teoretycznie da się łatwo napisać jakiś piper o tym, to nie bardzo da się dostosować do czegokolwiek, jest znaleźć algorytmy, które pozwolą działać i szybko i dokładnie.
Możemy pójść jeszcze troszkę kawałek dalej, możemy powiedzieć, że coś jest podobne, jeżeli zachowuje się podobnie. Tak, jeżeli mamy funkcję, zupełnie blackboxowo, 100 z bajtów, nie interesuje nas co jest, załóżmy, że udało nam się zgadnąć calling convention, dajemy jej 3 argumenty, jakiś bufor, jakiś bufor i długość, dostaniemy to, że ten bufor znajdzie się, jeden bufor znajdzie się w drugim buforze dokładnie o tej długości byte, no to łatwo powiedzieć chyba MEMCBY, chyba. Więc tak jeżeli coś się coś ryczy jak krowa, to jest pewnie krową, wydaje mi się, że to było jakieś dłuższe powiedzenie, tylko nie mogę sobie przypomnieć dokładnie jak ono szło, ale pamiętam, że było fajne. Tak możemy takie rzeczy zastosować, osiągnąć za pomocą bardzo, może nie
prostych, ale w tym już łatwo dostępnych technologii jak emulacja czy rozwiązywanie symboliczne, tak, z MT Solvers to nie dokładnie to co powiedziałem właśnie, ale nieważne, także możemy sobie zaemulować ten kawałek kodu i zobaczyć wejście-wyjście, zakładając, że mamy dobry emulator, przy prostych funkcjach to działa bardzo fajnie, jak mówiłem dla prostych rzeczy, troszkę bardziej skomplikowanych, albo jeżeli byśmy mieli dokładny, no to możemy sobie symbolicznie wykonać ten kod, a potem te wszystkie constrenty, które powstaną, tak, zapisywać sobie constrenty, potem te constrenty postaracie się rozwiązać za pomocą jakiegoś SMT solvera typu Z3
albo jakichś innych i zobaczyć, albo po prostu porównać te constrenty, jeżeli to są te same constrenty, no to prawdopodobnie jest to dokładnie to samo. to też jest mało łatwe i mało skalowalne, bo jakby idea jest, dobra potem do narzędzia, idea jest ogólnie zbudować system, który pozwoli nam się podpiąć do tej bazy danych, zastać wszystkie informacje o funkcji, które mamy i jakby zaciągnąć dane o tym i się nie przejmujemy, tak, wtedy zamiast setek funkcji rewersujemy dwie albo trzy, ponieważ te setki już gdzieś widzieliśmy, ale jeżeli chcemy rzucać kostką atrybucji, no to wiemy, że ten kawałek kodu należy do OpenSSL-a, to jest curl, to jest coś tam i tak dalej, i tak dalej. Na szczęście nie musimy tego robić sami, ażkolwiek bardzo fajnie by było, ponieważ są jakieś narzędzia, które
działają mniej lub bardziej poprawnie,
ja postaram się wam przybliżyć, Pokazywałem na początku, to oczywiście zgubiłem jedno z, nazywa się Rizo i to jest bardzo prosty skrypt od człowieka, który nazywa się, o w mordek się nazywa, występował w Internecie pod nikiem dev.tts.ts.0 i zajmował się głównie połnowaniem routerów, kiedy to jeszcze nie było modne. Cześć Michał.
Pozdraw Drakomatych, przepraszam. On to stworzył, ponieważ brakowało mu odpowiedni heurystyk do wyszukiwania kodu bibliotecznego w dużym firmwareze. No i jak widać, pokazałem to na początku, to działa całkiem bardzo dobrze, ja tego używam bardzo z dużym rezultatem, po każdej przeanalizowanym malwareze generuje, on bierze wszystkie funkcje, które już mają nazwy, robi sobie z nich pewne charakterystyki, robi z tego jakiś hash, sobie do jakiejś prostej bazy, prostego pliku tekstowego bodajże, albo do jakiegoś pikla poitonowego, potem można sobie to wszystko odtworzyć ładnie. Minus jest z tego taki sam też jak flirta, tak, flirt jak mówiłem działa na dużo bardziej dokładnej zasadzie, to nie jest po polsku, że bierze jakiś tam kawałek początków, bierze jakiś początek funkcji, matchuje go sobie z nazwami, Problem tych narzędzi jest taki, że one
mają tylko informacje o nazwie funkcji, nic więcej, a jednak jedną z rzeczy, która jest bardzo ważna poczas rewersowania jest to posiadanie typów, którymi operujemy, tak, czyli jeżeli funkcja bierze jakieś argumenty, no to chcemy wiedzieć jakie to są argumenty, przede wszystkim jakie mają typy, że są jakieś sygnatury, no to chcielibyśmy tych sygnatury nie rewersować znowu, tylko mieć zaimportowane, niestety żadne z tych narzędzi tego nie posiada, dlatego są smutne.
znaleźć trochę podobieństw i to są projekty, które przychodzą i odchodzą. Bincrow od Dynamics upadł, w tym momencie przeglądałem trochę tych rzeczy i wydaje mi się, że był jednym z najlepszych form, działał dokładnie tak jak mówiłem, tak liczył sobie MD indeks z danych, danej funkcji, wysyłał informacje o tej funkcji na serwer, zapisywał to sobie, wszystko fajnie, tylko chyba znowu by z tego spamiętował, ale tak jak już nie to dłużej niż ja pracuję w CRC, więc nigdy mnie to nie interesowało dokładnie.
Najnowsze jest to, co jest na samym dole, czyli First Function Identification Recovery Signature Tool od takiej firmy, która nazywa się Talos, czy tam Cisco, jest to pewna próba od zrobienia dobrego narzędzia, która została pięknie zaprzepaszczona, za chwilę, najpierw o crowdrę, które było moim zdaniem idealnym narzędziem do pracy i działało dokładnie tak, jak było trzeba, czyli brało nie tyle co z sygnatury funkcji zapisywało, ale brało też typy i zapisywało i można było sobie wszystko ładnie importować, definiować, wybierać czy ta funkcja jest odpowiednio, czy wierzymy danej osobie, która zaplodowała tą funkcję, bo to wszystko było oczywiście w jakimś cloudzie, co ludziom się nie podobało, bo nie chcemy się dzielić z nanymi, ale to już jest inna sprawa, działało w miarę dobrze i pozwalało właśnie importować odpowiednio
dużo danych, jak pierwszy raz rewersowałem z EUSa to pomogło mi to strasznie, bo rewersowałem tylko 40% kodu, a nie 100, bo większość okazało się, że było wcześniej.
Polichom, że nie wiem za bardzo nic, ponieważ jest francuski i wszystko jest po francusku, ale mają jakieś fajne pomysły na kolejne hasze, które działają też całkiem dobrze, polecam poczytanie tego papieru po francusku, jak ktoś go umie poczytać. Tak jak mówiłem o first-cie first jest jakąś próbą jest jedyną z tych wszystkich rzeczy dostępną w pełni publicznie, ale nie polecam czytania chyba, że to chce mieć koszmary senne, to jest mniej więcej dużo tysięcy linikodów w jednym pliku i wszystko naraz, klasy na klasie, za klasą, funkcje w tym wszystkim i ogólnie śmiesznie, działa to tak, że bierze wszystkie bajty danej funkcji i wysyłaje na serwer i na serwerze robi wszystko od nowa, czyli dekoduje instrukcję, robi jakieś zdefiniowane przez nas, albo tam są trzy moduły
zdefiniowane przez Talosa, to jest po prostu takie same bajty,
post dekomponu... z asemblacji bierze jakieś maskowane bajty, czyli usuwa te kawałki kodu, o których mówiłem wcześniej i porównuje je
i chyba to było coś tam jeszcze, ale też jakieś bardzo proste i mało wiarygodne.
liczy hash z mnemoników, przepraszam, sh1 po prostu z mnemoników danej funkcji. No i to wszystko jest bardzo piękne i fajne, tylko jakby tracimy wszystkie dane, które już ma IDA u nas, tak, czyli całą tą strukturę grafową, która jest dość ważna i też nie zapisuję typów, ale jest. Tak jest trochę rzeczy, które działają, jakby są zainteresowane bardziej różnicami niż podobieństwami, to jest wcześniej wspomniany bin-diff, który chyba jest dalej rozwijany, wydaje mi się, jest, miał być open source'owany, chyba nie wyszło, kosztuje jakieś 200 dolców? Nie miał być. Aha, no tu można sobie zainąć binarkę, ale nie można zobaczyć, co jest w środku, więc można sobie porewersować.
Tak, i to sobie jakoś tam działa, jest TurboDiff, Darun, Grim, potem był jeszcze PatchDiff, to są takie wszystkie próby Bindifa po raz kolejny, w momencie, w którym on kiedyś był, Dynamics jak został kupiony przez Google, a w pewnym momencie został zatrzymana ta sprzedaż i ludzie zaczynali się stanawiać, że nam brakuje tych narzędzi, to stworzmy jakieś sobie własne i tak i inne rzeczy. Ono już chyba, żaden z nich nie jest rozwijany. Widziałem, że jest parę prezentacji o R2, ja mam o R2 bardzo specyficzne mniemanie, w związku z czym pozwoliłem sobie zamieścić, że jest R2D, w którym nie wiem w ogóle czy działa, kiedyś próbowałem cośkolwiek zrobić, to sekwaltował cały czas, może działa lepiej, to było parę
lat temu, jest najnowszy projekt człowieka z,
nie z Katalonii, tylko gdzieś obok, jeszcze z Hiszpanii tak czy siak,
z kraju Basków właśnie, dokładnie tak, dziękuję, nazywa się Johan, nie wiem, jak mnie kiedyś znajdzie, to mnie zabije za tą prezentację, jak?
w internecie występuje jako metalast, między innymi jest autorem książki o hakowaniu antywirusów. I to jest jakby dość nowe narzędzie, chyba ma dopiero dwa lata, ma wszystkie te scherystyki, o których ja mówiłem plus dużo więcej, przede wszystkim jako pierwsze narzędzie wykorzystuje to, że mamy już trochę więcej niż tylko dizasemblację, mamy też dekompilację, w związku z czym możemy działać też na tym, tak, w związku z czym te wszystkie hejorystyki stara się zastosować też do kodu z dekompilowanego, jeżeli oczywiście mamy dekompilator. Niedawno jakaś część została dodana,
jedną z silników zastępujących i generujących grafy do diafory jest też radar, w jakimś tam stopniu ponoć też całkiem dobrze działa, prezentacja była na R2-Konie w ostatnim, polecam nie tyle, żeby zobaczyć to, że działa z radarem, tylko po prostu jak działa, bo jest całkiem sensowna.
Co dalej można by z tym zrobić? Można by pokusić się o jakieś inne śmieszne hasze, wczoraj mi powiedział znajomy, który zajmuje się takimi rzeczami na uczelni, że jest coś takie jak minhash, simhash i że można by to użyć na zbiorze różnych cech, minhash i simhash to są hasze używane przez znowu przez Google'a, bo przynajmniej tak zostało powiedziane, minhash był używany w altaviscie, a simhash w przeglądarce, o której wiadomo, do wyszukiwania podobieństw w stronach, więc jest pewna szansa, że działa całkiem dobrze. Ja więcej pomysłów chyba nie mam, jeżeli ktoś ma to chętnie posłucham, a tak naprawdę to trzeba robić, to trzeba ruszyć dupę w troki i napisać konkretny kod, który będzie działał tak jak trzeba, bo no jest takie narzędzia, które
jest używalne, jest otwarte, coraz nie ma, ja się próbuję za to zabrać, stąd ta prezentacja między innymi, po to, żeby sobie uporządkować tą wiedzę, chyba że, chociaż jestem w stanie uwierzyć, że stworzyłem więcej chaosu niż w porządku, ale ja lubię chaos, więc tak, jeżeli ktoś chciałby przykład pracować ze mną przy czymś takim, to zapraszam do kontaktu, jeżeli nie to też fajnie, ja może w końcu się zbiorę i to zrobię. Jeżeli cokolwiek z tego było interesujące, albo lubicie masochizm, albo np. nie chcecie pracować w wojsku w najbliższym czasie przez security, to zapraszamy do NASK-u i to byłoby na tyle ode mnie. Jakieś pytania? Nie, przyzwyczaiłem się.
Jak można sobie poradzić z opfuskacją kodu? Czymś takim? nie bardzo można, to są oczywiście statyczne narzędzia, tak. Duży plus jest taki, że przy rewersowaniu malwareu kod nie jest wpuskowany, w sensie jest wpuskowany na początku, jak już rewersujemy dokładnie malware to zazwyczaj już nie jest, bardzo rzadko jest, można sposób sobie poradzić taki, żeby napisać defuskator wcześniej, dopiero potem zastosować narzędzia do tego konkretne, tak. Czyli do packerów to też się tak to samo się odnosi. Do packerów, no packerów nie chcesz identyfikować za bardzo, nie chcesz i kanalizować przede wszystkim,
odpakowujesz go dowolno wolną metodą, tak? Ja w ogóle nie zajmuję się rozpakowywania malware, to jest straszna strata czasu. Jestem bardzo wdzięczny ludziom, którzy puszczają wszystkie te miliony wideo na YouTube, jak odpakować malware, naprawdę to strata czasu, to wszystko można zrobić półautomatycznie, o czym już kiedyś mówiłem, swoją drogą. Więc tak, jeżeli jest rozpakowany, jeżeli dalej jest zaobfuskowany, no to można napisać jakieś narzędzie, które nam to zdobfuskuje i będziemy działać dalej na tym, co już mamy. Coś jeszcze?
Dziękujemy bardzo Makowi. Teraz dam kilka spraw technicznych głównie dla ludzi, którzy nas oglądają, czyli dla streamowidzów. Jeżeli chcielibyście zadać pytanie naszemu prelegentowi to możecie tego dokonać. zarówno jako komentarz przy filmie, jak i za pośrednictwem naszego Irca i Slacka. My staramy się to też śledzić i jeżeli będzie takie pytanie, to po prostu je powtórzymy. Kolejna sprawa tutaj głównie dla Panów prelegentów i Pani prelegentek. Jeżeli jest jakieś pytanie z sali, nie przez mikrofon, to prosiłabym mimo wszystko powtórzyć ze względu na to, że to co nie jest przez mikrofon, to ludzie tego po prostu nie słyszą. Jeszcze informacja dotycząca dnia jutrzejszego. Wszystko po lunchu będzie przesunięto o 30 minut względem agendy.
Wiesz co ciężko mi mówić w górę czy w dół 30 minut później będzie wszystko. Ok, także 5 minut przerwy.
Would you die for me? Yes. That's too easy.
Ok, mogę zaczynać? To test. Ok, to nawet wszystko działa chyba. No to tak, będę miał prezentację o kryptografii albo o tym jak jej nie robić i kim ja w ogóle jestem, co ja tu robię. No więc pracuję w CERC-cie, tak jak kolega Maciek sprzed chwili, tu już go poznaliście. W wolnym czasie gram w CTF-y, w swoim zespole, no p4, w sumie trochę moim, bo go współzałożyłem. kryptografię i algorytmikę, stąd też temat tej prezentacji. No i lubię koty, stąd będzie dużo zdjęć kotów, ale tylko takie w internecie i na zdjęciach. No i coś tam robiłem z kryptografią, jakieś decryptory nawet napisałem, są na stronie CRT-u, więc coś tam może wiem, może nie. No i jak ktoś chce mnie
znaleźć w internecie, to są linki na dole albo można po prostu po prezentacji zagadać. I temat wziąłem z tego, że zobaczyłem sobie na stronę B-sidesów, Pierwsze dwa prezentacje, które były nadesłane, były o kryptografii. No to pomyślałem sobie, okej, no to pisać, co są teraz prezentacją o kryptografii, ja też coś powiem o kryptografii. No i w zasadzie tyle. Drugi temat jest taki, w sumie czego nie robić jest tak overflow, bo jakoś tak przypadkowo wyszło, że połowę rzeczy, które chciałem powiedzieć, które są złe z kryptografią, okazało się, że to jest dlatego, że ludzie źle kopiwali kod po prostu z internetu. No i trzeci temat jest, że wyśmiewam się z niewinnych ludzi, Tak naprawdę nie wyśmiewam się z ludzi, tylko wyśmiewam się z ich kodu, więc to nie
jest takie personalne. Wiadomo, że każdy popełnia błędy, więc mam nadzieję, że nikogo nie urażą tą prezentacją. Zresztą nikt pewnie z internetu nie zobaczy tej prezentacji, tak jest taka overflowa, więc agenda. Najpierw będą szyfry blokowe, mam nadzieję, że nie wszyscy zasną wtedy. No i tak będzie kilka minut teorii, później jakieś tryby, dziwne rzeczy. i co można z nimi zrobić i czego z nimi nie należy robić i zakończymy własną kryptografią i czy ją robić, czy jej nie robić i może jak łamać różne takie algorytmy. No i takie, że mam bardzo dużo slajdów, to będę trochę pędził, dlatego zaczniemy już od szyfrów blokowych. No i co to są szyfry blokowe? Szyfry blokowe to są tak, szyfry, każdy wie co to są szyfry, mam nadzieję, no czyli coś takiego, co nie
chcemy, żeby ktoś inny potrafił zeszyfrować, powiedzmy jakiś nasz przeciwnik, wróg. Szyfry się dzielą na symetryczne i asymetryczne. Szyfry asymetryczne to jest taka trochę czarna magia matematyczna i są trudne i zazwyczaj tam są jakieś operacje matematyczne i o tym się papery pisze. I one faktycznie są trudne, ale też przez to są do nich biblioteki dobre, które nie pozwalają po prostu programiści zrobić błędu, więc przez to rzadko się zdarzają w prawdziwych aplikacjach błędy z kryptografią asymetryczną. Ale no tak, to jest też najnowsza dziedzinia kryptografii, powstała jakoś tam niedawno. i stąd różne magiczne rzeczy się da robić, których kiedyś się nie dało. No i o nich to w ogóle nie będzie. Za to ciekawsza dla nas jest krepozycja symetryczna, czyli kiedy szyfrujemy
tym samym kluczem, którym deszyfrujemy, no i też mamy szyfry strumieniowe, które polegają na tym, że w zasadzie ktoś bierze klucz i generuje z niego dużo jakichś losowych bajtów, a później plaintext, czyli dane, które chcę zaszyfrować, ksoruje z tymi bajtami, no i wychodzimy o jakiś cyphertext. I teraz nie mając nie da się zeszywać cyfer tekstu, no bo ktoś nie jest w stanie zgadnąć, jakie to były bajty wygenerowane losowo. No i w teorii to nie musi być kserowanie, ale w praktyce prawie wszystkie szyfry strumieniowe tak działają, więc to jest dobre uproszczenie. No i z prawej strony jest obrazek, jak ktoś lubi obrazki, nie wiem, czy coś z niego wynika, jestem słaby w obrazkach, za to lubię kod, więc z lewej strony jest kod, taki poglądowy, jak to może
wyglądać. trochę inaczej jest z szyframi blokowymi, bo tam nie szyfrujemy byte po byte, albo bit po bicie, tylko dzielimy sobie dane na jakieś bloki i te bloki po kolei szyfrujemy jakąś magią. Znaczy jest jakaś funkcja, na przykład AS, który szyfruje tylko dane o wielkości dokładnie 16 bajtów, więc dajmy ASowi 16 bajtów, on robi jakąś magię, magię i wychodzi z tego 16 bajtów, który jest zaszyfrowany jakimś kluczem. By coś takiego zaszyfrować, no to trzeba najpierw podzielić dane na bloki o długości tych 16 bajtów, a później je jakoś zaszyfrować. Można to zrobić tak jak na tym obrazku, czyli po prostu szyfrować każdy blok osobno i sklejać, okazuje się, że to nie jest bardzo dobry pomysł, ale o
tym jeszcze będzie. No i przykłady to jest np. 3DS, AS albo Blowfish, z czego najpopularniejszy jest AS oczywiście, obecnie.
Mamy taki problem, że jeśli mamy na przykład 4 bajty, jakie chcemy zaszyfrować, no to ciężko to zrobić AS, bo AS chce 16, nie chce 4, nie chce 5, nie chce 20, tylko chce 16, więc trzeba dopełnić jakoś te bajty, no i jednym z takich rozwiązań jest PKC 7, czyli jeśli brakuje nam jednego bajta, to doklejamy jeden bajt wartości 1, a jak brakuje nam 2 bajtów, to doklejamy 2 bajty wartości 2, a jak 3 bajtów, to 3 bajty wartości 3 i tak dalej, do 16, do 15, bo jak brakuje 16 bajtów, to znaczy, że niczego nam nie brakuje, i doklejamy 16 bajtów wartości 16, bo tak, żeby było jednoznacznie. No i niektóre biblioteki to robiłem dobrze,
np. php mcrypt bodajże to robi źle, czyli dokleja zera, czyli nie da się tego jednoznacznie zdjąć, no ale po prostu php, tak, nie bardzo jestem fanem tego języka, współczuję ludziom, którzy programują w php, jeszcze o nim będzie zresztą. No i teraz większy problem jest taki, że jak już mamy te 16-bajtowe bloki, no i mamy jakąś wiadomość, która się już dzieli na 16, bo zrobi się padding, Co zrobić dalej? Jedno rozwiązanie jest oczywiste, takie jak było poprzednio, czyli po prostu szyfrujemy wszystko osobno, to się nazywa tryb ECB naukowo, bo w kryptografii wszystko musi mieć jakiś kryptonim i nazywać się skomplikowanie, ale po prostu chodzi o to, że szyfrujemy wszystko osobno, czyli pierwszy blok paint textu, pierwsze
16 bajtów szyfrujemy i to jest pierwsze 16 bajtów w wyniku, później drugie 16 bajtów szyfrujemy i to jest drugie 16 bajtów w wyniku i tak dalej aż do końca.
Brzmi jak dobry pomysł na początku, ale okazuje się, że ma bardzo dużo problemów w praktyce i nie powinno się tego w ogóle stosować, tylko że niestety jest to domyślnym trybem w większości bibliotek ciągle, bo nie wymaga żadnych dodatkowych danych, więc jakoś tak wyszło, że to jest default. No i np. w Pythonie, którego szanuję, Python dobry język, w PyCrypto ciągle to jest domyślny tryb i dużo ludzi tego używa, może nie dużo, ale zdarza się ciągle. I właśnie sobie, że mamy taką historię, że mamy jakąś stronę, w której mamy ciasteczka, bo lubię ten przykład, dużo dzisiaj będzie rzeczy w takim formacie. Mamy stronę i ta strona ma jakieś ciasteczka i zamiast trzymać się informacje w bazie danych, no to myślę sobie, oszczędzę na bazie danych, będę trzymał informacje u użytkownika, ale
te informacje będą zaszyfrowane, więc użytkownik sobie ich nie zmieni. No i na przykład aplikacja trzyma, po zalogowaniu użytkownikowi daje jakieś ciastko, które wygląda tak jak tutaj, że w ciastku jest nazwa użytkownika, jest pytanie czy odpowiedź, czy użytkomiki jest adminem, czy nie jest adminem. No i może to wygląda dobrze na pierwszy rzut oka, w sensie ciasko jest zaszifrowane, tak, nikt go nie zmodyfikuje, takie jest założenie, tylko że to tak nie działa. Dlaczego to tak nie działa? No bo przykładowo, jak zaszifrujemy sobie użytkomika o nazwie msm, to mój nikt w ogóle, nie wiem czy się pochwalił, ale tak, więc jeśli zaszifrujemy sobie ciasko dla użytkomika msm, no to wychodzi jakieś takie coś i z tego szyfrujemy te
dane po lewej, niebieskie, pewnie nie widać z tyłu albo ze środka, a wychodzą nam te dane pomalęczowe, czyli jakieś zaszyfrowane bajty, które no atakujący nie jest w stanie ich zeszyfrować, tylko, że jeśli aplikacja jest na przykład open source, to atakujący nie musi ich deszyfrować, no bo w zasadzie to wie, wie co jest w tych danych, więc jakby jedyne czego nie może zrobić to wygenerować sobie własnego ciastka, który mówi na przykład, że name msm has admin true, że powiedzmy mamy sobie użytkownika Hacker, no i on sobie wygeneruje, najpierw sobie użytkownika założył o nazwie Hacker, no i tak oś działa, wychodzi takie ciesce jak na górze, które może widać, a później założę sobie takie hakerskiego użytkownika, który się nazywa Hacker, True, Dużo Spacji, X,
tego już na pewno nie widać z tyłu, no i wychodzi takie coś jak na dole, wiem, nie widać, ale the point is, że atakujący chce sobie podzielić cypher text na bloki i wie, co się znajduje w każdym bloku zaszyfrowanego i nic go nie powstrzymuje, żeby sobie wziąć i poprzeklejać kawałki tych bloków. To są posklejane kawałki z obu ciasteczek, no i tak ten pierwszy kawałek jest z pierwszego ciasteczka, drugi z drugiego ciasteczka, trzeci znowu z drugiego, czwarty z pierwszego i jeśli tak poskleja, to okazuje się, że mamy ciasteczko, to jest poprawny JSON po lewej, więc atakując sobie przeklejamy te pomańczone kawałki, nie wiedząc, co tam się znajduje, znaczy nie mogą nic zeszyfrować, a do serwera wysyła, no serwer sobie deszyfruje i wychodzi to niebieskie,
czyli poprawny JSON, dekoduje się ładnie, o nie, zostaliśmy zhakowani, znaczy użytkownik haker dostał ciasteczko, które mówi, że jest adminem i może teraz, nie wiem, usunąć rzeczy z naszej strony. No i to jest oczywiście kompletnie wymyślony przypadek, na pewno nikt tak nie robi, przynajmniej tak myślałem, ale jak sprawdziłem, czy internet się ze mną zgadza, tak to jest inna rzecz, którą można zrobić źle w trybie ACB, i byt może sobie brutusować, no ale to jest mało praktyczne. Sprawdziłem czy internet się ze mną zgadza, no i okazuje się, że się nie zgadza, bo pierwszym wynikiem mojego zapytania o szyfrowanie w PHP było jak najlepiej zasiasteczka zasiasteczka. I odpowiedź, która jest na, którą Google mówi, że no real reason not to go with AS, czyli
nie ma powodu, żeby nie szyfrować AS, najlepiej użyć trybu CBC, co w sumie też nie pomaga, ale o tym później. No i na Kiedy kliknąłem w ten link, wychodzi tam takie arcydziału kryptografii, które, no tak, arcydziału kryptografii, które znajduje się pod tym linkiem i co ono właściwie robi? Po pierwsze szyfruje ciastka, co już samo z siebie jest głupie, nie polecam najgłodszemu wrogowi, żeby sobie szyfrowa ciastek na stronie, no ale to już okej, ustaliliśmy, samo pytanie było jak zasyfrować ciastka, więc okej, powiedzmy. Jestem więcej problemów, na przykład jest użyty IV w tym, a jeśli ktoś uważał, to zauważył, że nie powiedziałam dotychczas słowa IV, bo w trybie ECB nie ma czegoś tak IV, IV to jest
coś, o czym będziemy mówić później, co występuje tylko w trybie CBC, no ale ktoś tutaj napisał kod, który szyfruje trybem ECB i dodaje parametr IV, to jest parametr opcjonalny w PHP, a PHP jest zbyt fajny, żeby się przejmować, że ktoś mu daje niepotrzebne parametry, to sobie spokojnie szyfruje i w wyniku oczywiście każde szyfrowanie daje taki sam wynik, czyli IV jest kompletnie ignorowany, ale jak widać nie ma tu żadnego warninga, nie ma niczego. No PHP jest szczęśliwy. Tak, nie lubię tego języka, no ale to nie jest jedyny problem z tym kodem. Można iść dalej, na przykład to wcale nie jest AS256. To trochę brzmi jak AS256, bo AS to jest Rindl, a 256 to jest 256, ale To naprawdę to jest
tryb szyfrowania, który jest używany prawie że wyłącznie w mkrypcie, w PHP, który jest bardzo hipsterski, który jest mało zbadany, a którego dużo ludzi używa, bo nie wiem, myślą, że to jest AS256, no i to jest odmiana Rindela, która ma 32-bajtowe bloki, no ale właśnie prawie nikt jej nie badał i prawie nikt jej nie używa, więc tak kolejna pomyłka, ale to nie koniec, bo po pierwsze, dlaczego która się nazywa salt, która mnie martwi, bo to znaczy, że ktoś nie wie w zasadzie co pisze, jak nazywa parametry, a po drugie stream, co oznacza, że jeśli dane się kończą na spację na przykład szyfrowane, no to jak zaszyfrujemy te dane i zeszyfrujemy, no to spacja będzie ucięta. To nie jest jakiś wielki problem może zazwyczaj przy ciastkach,
no ale to znaczy, że ktoś nie testował kodu prawdopodobnie jakoś dokładnie i może jest więcej problemów. Tak, no więc poznałem całą się nad tym kodem, ale na pewno nikt go nie używa, prawda? Niestety nie, bo wyszukałem sobie go tak z ciekawości na GitHubie i okazuje się, że jest 6 tysięcy wyników prawie, że i wszyscy ci ludzie szyfrową RIDL-em 256 i wszyscy ci ludzie mają jakieś solty w parametrach, i wszyscy ci ludzie prawie przekazują mi IV do funkcji, która nie potrzebuje IV. No, fajnie, cieszę się, że ludzie czytają stackoverflow, tylko że mogliby zastanawiać się, czy na pewno robią dobrą rzecz. No, tak, zmartwiało mnie to trochę.
Ten pierwszy z brzegu przykład, który kliknął, to była jakaś strona, która robi dokładnie to, co pokazywaliśmy wcześniej, czyli szyfruje sobie użytkownika i informacje o nim przy logowaniu do ciastka i wysyła go później użytkownikowi i robi to dokładnie tą funkcją, która jest na Stack Overflowie. Albo kolejny przykład, czyli funkcja, która znajduje się w jakiejś stronie od e-commerce, czyli są koszyki, ludzie tam klikają produkty, kupują produkty, e-commerce jest open source, już chyba nie używam, prawdopodobnie z uwagi na jakość kodu, bo nie mogą znaleźć działającej instancji. No i fajne jest to, że mamy parametr title, który możemy sobie ustalić na dowolną wartość jaką chcemy, czyli możemy sobie nadejść jakiś tytuł transakcji.
No i to, że możemy sobie nadejść tytuł transakcji, to znaczy, że możemy tam dowolne dane jakie użytkownik by chciał zaszyfrować, zaszyfrować. to się przyda. Jak widać tutaj jest, znaczy pewnie nie widać, bo to jest na dole slajda, dane, które są wysyłane do dojrzykownika są serializowane, czyli wrzucane do jakiegoś ciaseczka, tutaj jest na górze slajda, więc już coś widać, no i te dane wyglądają na przykład tak, czyli mamy jakąś cenę, mamy ilość, mamy tytuł, no i możemy sobie zrobić właśnie jakąś testowy zakup, znaczy albo sobie lokalnie postawić oczywiście i zrobić testowy zakup, no i ciaseczko będzie wyglądało tak jak tutaj. jakieś kody o nazwie kod 1, 2, 3, mamy sobie testowy tytuł, testową ilość, testową cena, cena tutaj wynosi 100, no jest to złotych, to
trochę dużo, albo dolarów w sumie czegokolwiek, więc chcielibyśmy trochę mniej zapłacić, no jak to można zrobić? Znaczy atakujący chciałbym nie zapłacić, więc można sobie założyć na przykład, trochę pokombinować i wymyślić, że można założyć sobie coś, co się nazywa tak, znaczy dać taki tytuł, W tej chwili PHP to sterylizuje bez problemu, będzie wyglądało ładnie, wszystko się dobrze sterylizuje, tylko że w sterylizowanych danych będziemy mieli takie coś, tutaj na czerwono podkreśliłem ciekawe elementy, czyli będziemy mieli jakieś bloki z lewej strony, no i fajnie, no w PHP na razie wszystko rozumie, ale jeśli przekleimy ten pierwszy czerwony blok do drugiego, czyli pierwsze zaszifrowane dane przekleimy do drugiego miejsca, to okazuje się, że na zresztą widać co się stanie, czyli po prostu PHP potraktuje te
dane, które przekleiliśmy, zresztą słusznie, jako fragment zrealizowanych danych, no i potraktuje to jako cenę. No i w ten sposób atakujący mógłby sobie zmienić cenę w kosztku ze 100 zł na 1 zł, pod warunkiem, że nadałby taki tytuł i zrobił później trochę magii, co jest proste. Jeśli ktoś wie jak wygląda kod, to może sobie to lokalnie przetestować, problemów i printując sobie wszystkie rzeczy, no i wie dokładnie co się dzieje. Mi to zajęło chwilę naprawdę, bo to jest proste, kiedy jakby widać wszystko lokalnie. Gdyby kod nie był open source oczywiście to byłoby dużo trudniej, co nie znaczy, że było bezpiecznie. No i mój ulubiony przykład to jest AbanteCard, co jest taką PHP-ową dużym frameworkiem do e-commerce, no i oczywiście są bezpieczni, ale to wyszukiwanie kodu
też mnie na nich trafiło. trafiłem na nich przy wyszukiwaniu tego kodu od ECB, no bo oczywiście szyfrują też Rindale'em 256, bo nie wiem, pewnie kopiwali z internetu, przynajmniej mieli tyle godności, że usunęli IV, który nie jest używany, więc fajnie, ale problemów mają tutaj dużo, na przykład jeśli ktoś zapomni sobie ustawić klucz szyfrowania, to cała funkcja szyfrująca, od której zależy bezpieczeństwo aplikacji po prostu wyjdzie i zignoruje całe szyfrowanie, albo jeśli serwer nie ma zainstalowanego mcrypta, no to Tutaj jest zastosowane jakieś magiczne argument szyfrowania, które jest równoważne mniej więcej Cezarowi, w sensie szyfrowi Cezara. No i to jest coś, co taki średnio rozgarnięty gimnazjalista by załamał na kartce w 5 minut. A od tego zależy bezpieczeństwo sklepu, więc no nie chciałbym czegoś takiego u siebie. Albo na przykład
podało mi się, że klucz jest haszowany za pomocą SHA256, co no generalnie też nie jest dobrym pomysłem, bo albo chcemy użyć bezpiecznego password key derivation function, bo powinnam po prostu mieć klucz, który jest bezpieczny od razu, czyli ma 32 bajty i jest niebrutowalny. No ale oczywiście najlepsze jest to, że został użyty algorytm ECB, który algorytm Rindel w trybie ECB, co pozwala na ataki, jak już widzieliśmy. No i na koniec taka ciekawostka, że robisz jeszcze jakieś dziwne rzeczy w rodzaju replacowaniu, podmienianiu znaków, co w sumie nie ma do końca sensu, bo to nie jest zadanie funkcji szyfrującej, chciałem tylko ponarzekać, więc całą tą funkcję, te wszystkie rzeczy, do których się przyczepiłem, można w zasadzie wyrzucić, bo kompletnie nie zmieniam bezpieczeństwa i cała ta funkcja się
redukuje do czegoś takiego. No i to jest w zasadzie dwa razy lepsza wersja, która zajmuje 10 razy mniej linijek i można napisać z pamięci nawet.
No i oczywiście jest to wszystko używane w bezpieczny sposób, czyli szyfrujemy dane użytkownika i wysyłamy. W tym W dodatku na przykład dajemy do ciasteczka pierwsze imię użytkownika, czyli imię po polsku, dajemy id użytkownika, co jest ciekawe, bo jeśli zmienimy sobie id klienta na powiedzmy jeden, to prawdopodobnie zostaniemy jakimś adminem lub jakimś ciekawym. No i na koniec jest nazwa skryptu, czyli parametr z clip name, czyli miejsce, z którego było wywołane. To akurat jest do niczego nie używane z tego, co widziałem. No i fajnie, tylko że kilka slajdów wcześniej pokazaliśmy, że to można zupełnie banalnie łamać, Na parametry first name wpływamy przy ilustracji. Nie ma żadnych ograniczeń prawie, że na to, co można nam dać. Nie można dać apostrofu, bo
SQL injection czy coś, co jest głupie, bo niektórzy ludzie mają apostrof w imieniu, ale różne rzeczy, które potrzebujemy do ataku, już nie są blokowane. No i to jest tak w abante.src, który jest w popularnym repozytorium, a przynajmniej było, bo to jest kod z roku 2016. No i to się trochę zmieniło, ale do tego też wrócimy, bo na razie wnioski z części ECB, bo już wychodzimy z tego, tak, wniosek jest taki, żeby nie używać trybu ECB, ale to jest taki nudny wniosek, bo każdy o tym mówi od zawsze i nie wiem, no myślę, że większość osób wtedy to słyszała przynajmniej 10 razy w życiu, no i więc to jest takie niekonstruktywne. Inny wniosek to jest taki, żeby nie używać PHP, ale to jest opcjonalne, no bo rozumiem, że jak
ktoś pracuje w PHP, no to głupio tak nagle zmieniać język z dnia na dzień. ale w sumie to nie o tym chciałem mówić, bardziej chciałem pokazać o tym, że nawet używając dobrych prymitywów można zrobić duże błędy w kryptografii albo aplikacja może być niebezpieczna. No i oczywiście drugim rzeczą ważną jest to, że szyfrowanie to nie jest uwierzytelnianie, to jest taka ładna mantra, czyli nie wysyłamy użytkownikowi ciastek zaszyfrowanych, a przynajmniej nie po to, żeby bronić je przed modyfikacją, no bo jak widać użytkownik sobie może modyfikować ciastkami ją wszystko bez problemu. Nie myślę o trybie CB, są też lepsze tryby, na przykład tryb CBC, co jest kolejną kryptyczną nazwą, a polega to w zasadzie po prostu na tym, że kolejne bloki są kserowane z poprzednimi, więc nic skomplikowanego
wbrew pozorom, ale zabezpiecza przed tymi wszystkimi atakami, które były dotychczas pokazane, czyli nie można sobie tak przekleić po prostu kolejnego bloku do poprzedniego albo nie można sobie tak po prostu pozmieniać czegoś albo zmienić kolejności, nie można się zorientować, co jest zaszyfrowane, brutto fransując cokolwiek. No ale są inne fajne ataki. Tak, tu jest kod, jak ktoś woli kod, ja na przykład wolę, czyli po prostu kolejne bloki cypher-tekstu, to są kserowane bloki plain-tekstu, zaszyfrowane z poprzednim blokiem. No i mamy tutaj IV, którego nie było w ECB. No i AbanteCards zabdejtowało swój kod, już nie używa Rindela 256, używałem krypta, za to używałem OpenSSL-a, dalej sprawdzę, czy OpenSSL istnieje, jak nie istnieje, to szyfruję z Cezarem, żeby było, nie wiem, fajnie. Ja na przykład bym wolał, żeby program mi nie działał
jednak, jak jest kompletnie niebezpieczny, niż żeby szyfrował Cezarem, no ale co kto lubi. A jeśli jest OpenSL, to wtedy jest fajnie, bo szyfruję OpenSSL-em, więc jest bezpiecznie, tak brzmi bezpiecznie, w trybie AS 256 CBC, czyli po prostu w trybie Rindl 128, wielkość klucza 256 bajtów. I czy teraz jest bezpiecznie? Tak jak mówiłem, nie jest bezpiecznie, no bo nie zmieniło się założenie, dalej ciastka są szyfrowane, ale jedyne, co możemy, tak, wszystko możemy wyrzucić znowu i zostają te dwie liniki, bo tylko one mają jakiś sens w tym kodzie. I co możemy zrobić z czymś takim? Jakby się przypatrzeć temu grafowi, rysunkowi, czemuś, że wystaje taki IV, który jest najbardziej tutaj jedynym elementem, z którego nie powstaje żaden plaintext bezpośrednio, tylko coś ani nie jest zeszfrowany, no i mamy nad nim
bezpośrednią kontrolę, bo to przekazujemy serwerowi, więc możemy sobie, jakby atakujący, znaczy osoba, która ma ciastko, czyli osoba, która ma cyphertext, może sobie dowolnie zmienić ten IV i co by się wtedy mogło stać. Na przykład jak mamy taką wiadomość, jak tutaj, mamy dane, zaszyfrowane, no i co się deszyfruje do tego na dole, czyli mamy, jak nie widać MSM równa się, tfu, MSM i admin równa się 0, tak celowo oszukałem trochę, żeby się mieściło w jednym bloku, no i jeśli to zeszyfrujemy coś na górze, to wychodzi coś takiego na dole, klucz to chyba 16 znaków A, tak dobrze pamiętam. No i fajnie, ale wynika, że tak jak mówiłem, jeśli zmienimy jakiś znak w IV, to zmienia się odpowiadający znak w zeszyfrowanych danych, dokładnie ten sam, czyli tutaj na przykład zmienią
pierwszy znak w IV i zmienił się pierwszy znak w zeszyfrowanych danych. No to jak atakujący pomyśli tak 15 sekund może, to wpadnie, że może zmienić tam 12 czy coś znak i wtedy zmienia 12 znak w zeszyfrowanych danych i jak wie jak zmienić ten znak, no to zmieni admin równa się 0 na admin równa się 1. i znowu dokładnie taki sam atak, czyli atakujący zmienia ciastko, które jest zaszyfrowane i uzyskuje prawo admina albo jakieś inne, albo uzyskuje w sumie co chce ze strony. No i wracamy do abante card, które szyfruje w trybie CBC obecnie ciastka. No i mamy na przykład coś takiego, czyli to co wcześniej było na slajdzie, czyli że szyfrowane jest nazwa użytkownika, ID klienta,
No i wyobraźmy sobie, że mamy jakiegoś użytkownika o nazwie msm123 z id123, to jest w sumie dowolna nazwa, no i co się wtedy stanie? To są zrealizowane dane, to na górze, no i tak jak mówiłem możemy zmieniać tylko IV i to jest trochę problem, bo możemy zmienić tylko pierwsze 16 bajtów tego IV, znaczy IV ma 16 bajtów, więc możemy wpłynąć tylko na pierwsze 16 bajtów zeszyfrowanych danych, no i to jest trochę mało mimo wszystko, Możemy zmienić nazwę klucza, first, no i to w sumie nic nie pomoże, najwyżej będzie jakiś błąd w programie. Możemy zmienić długość tego klucza, co spowoduje, że coś się wywali pewnie, albo wielkość tablicy i też się wszystko wywali. No ale tak
sobie myślę, że można w sumie dowolnie użytkownika nazwać, więc może coś by się z tym dało wykombinować. No i tak trochę mijając proces myślenia, bo to nie było aż takie szybkie do wymyślenia, ale jakby nazwać swego użytkownika w taki sposób na przykład. i wtedy mogły stać. No samo z siebie się w sumie nic nie stanie, będziemy mieli użytkownika, który się tak nazywa. Nie jest to jakaś wygodna nazwa użytkownika, no ale co kto lubi, ale teraz możemy zmienić pierwszy bajt w taki sposób, żeby się stały ciekawe rzeczy. Tutaj są pokolorowane odpowiednio fragmenty, nie wiem czy to widać tam z daleka, nawet jest jakiś slajd, więc możemy sobie zmienić długość first name'a na coś dłuższego i teraz nagle first name'em się klucz się zmienia na coś takiego, a wartością się staje
n i PHP kompletnie zmienia interpretację tych wszystkich danych, które zaszifrowaliśmy, wróć,
więc zmieniając tylko jeden bajt, zmieniamy wszystkie klucze i wszystkie wartości, ale w jakiś sposób to się jednak poprawnie dalej desrealizuje, no i zyskujemy to, co chcieliśmy, czyli użytkownika OID 1. No i w tym momencie znowu zostajemy hakerem, adminem, czymkolwiek chcemy, na serwerze, wielu sklepów, bo to stoi w paru miejscach, tak naprawdę Atac ma jeszcze jeden krok, o którym nie powiedziałem i w sumie nie chcę mówić, bo jeszcze ktoś to naprawdę zrobi, a będzie na mnie, więc zamiast tego, gdzie jeszcze jest to używane w tym abante kart? No na przykład mamy w momencie wysyłania, jak to się nazywa, linku do, kiedy ktoś zapomnie hasła, to są szyfrowane jakieś dane, tylko ktoś zapomniał, że no w sumie to może zmienić te zaszyfrowane dane, bo
możemy zmienić IV. Albo w momencie, kiedy ktoś wysyła order żądanie zakupu, też wszystkie dane są szyfrowane z mocą tego CBC po stronie klienta, więc znowu klient może sobie dowolnie na to wpłynąć. No więc nie jest to dobre bezpieczeństwo, a główny problem jest taki jak poprzednio, czyli że ktoś wykorzystał szyfrowanie, bo założył, że użytkownik dostał jakieś śmieci losowe, zaszyfrowane, no więc na pewno nic z tym nie zrobi, bo są zaszyfrowane, więc nie da się na nie wpłynąć. to niestety jest złe założenie, jak widać chyba, mam nadzieję, więc nie polecam tego robić, jeśli chcecie, żeby wasze strony działały. Jest tylko jeden taki drobny wyjątek, że w sumie to czasami jest, to znaczy czasami szyfrowanie jest uwierzytelnianiem, ale to tylko wtedy, kiedy nie użyjemy trybu ECB
albo CBC albo CTR albo innego typowego, tylko użyjemy jakiegoś hipsterskiego trybu szyfrowania, na przykład GCM albo one są obecnie bardzo naukowe, znaczy z nich, najlepszym trybem z nich jest OCB, tylko że ma ten duży problem, że jest opatentowany, więc w zasadzie jest dużo problemów, żeby go użyć, a konkretnie niby twórca zrzekł się prawie, że wszystkich praw, bo na początku chciał w ogóle pieniędzy za używanie w niekomercyjnych produktach, no teraz już prawie, że wszystkim daje za darmo, ale mimo wszystko dużo ludzi się buntuje przeciwko temu, więc ludzie jakieś inne tryby, które są gorsze i próbujemy ich używać, z tego GCM jest chyba najpopularniejszy teraz, no i to jest obiektywnie w sumie lepsze rozwiązanie niż szyfrowanie i podpisywanie,
bo uzyskujemy z szybkością samego szyfrowania i jednocześnie bezpieczeństwo, że nikt nie może modyfikować danych. No ale tak jak mówię, jest z tym problem z patentami, albo są patenty, albo są gorsze algorytmy, więc no coś za coś. A tymczasem, jak stuję z czasem, a nawet dobrze stuję z czasem, tego tematu, czyli podpisywania, bo jeśli chcemy podpisać jakieś dane, to wypada użyć podpisu, czyli jakiejś funkcji, która służy do tego, że możemy sobie podpisać jakieś dane i nikt ich nie może zmodyfikować, a jak zmodyfikuje, to my sobie to możemy sprawdzić i udowodnić, że on zmodyfikował i wtedy na przykład odrzucamy zapytanie. No i dużo ludzi do tego używa hashy, dlaczego to jest zły pomysł, to za chwilę do tego dojdziemy, na razie co to
są hashe w ogóle? Kryptograficzne hashe, czyli po polsku funkcje skrótu, którzy ludzie nie lubią jak się mówi hasze, to są funkcje, które przyjmują jakieś dane, coś tam robią i zwracają jakieś dane o stałej długości, czyli na przykład przyjmują plik o wielkości Neo Gigabyte'a, robią na nim jakieś magie, a później wychodzi z tego na przykład 128 bitów, jak w MD5. I jakie takie funkcje znamy? Na przykład MD5, SHA1, SHA2 i SHA3, to są takie najgłośniejsze nazwy, z czego MD5 jest już dawno martwe i nie powinno być w sumie nigdzie używane, jest trochę krócej martwe, a od jeszcze bardziej krócej jest bardzo martwe, bo Google wypuściło kolizję publicznie, no i zostały w sumie dwie funkcje, które warto używać, SHA2 i SHA3, z czego jest trochę bałagan, bo SHA2
występuje pod sześcioma nazwami, to jest w zasadzie rodzina, czyli na przykład SHA256 to jest odmiana SHA2, ale SHA3 jest nowsza niż SHA256, więc dobre nazewnictwo. Jeszcze mamy na przykład SHA512 przez 256, po prostu SHA512, ale obcięte do 256 bajtów bitów. No i to też ma swoją nazwę, żeby był większy chaos. No i to samo do SHA3, czyli mamy kolejną rodzinę, czterech funkcji haszujących, dodatkowo do tego zdefiniowano później jeszcze trzy kolejne funkcje haszujące, a samo SHA3 się jeszcze nazywa inaczej, czyli kecak, jeszcze jest kanguru tłew, które jest powiązane, ale inne, więc jest tego dużo, ale w zasadzie jeśli ktoś nie nie ma jakichś bardzo dziwnych wymagań, to można spokojnie stosować SHA256 i SHA512, a jeśli ktoś chce być odporny na, nie wiem, NSA albo komputery kwantowe, to SHA3256 i
512. No i więcej na razie nie potrzeba. A do czego są w ogóle funkcje haszujące, czyli funkcje skrótu? Mają takie dwie ciekawe własności, a konkretnie kryptograficzne funkcje skrótu, no bo w sumie zwykłe funkcje skrótu ich nie muszą mieć. i dwie ciekawe własności, że dwóch rzeczy się z nimi nie da zrobić, a przynajmniej dwa ważne ataki są na funkcję skrótu. Po pierwsze, nie można, jeśli mamy samego hasha, to nie możemy z niego wygenerować jakiś danych, które dają tego hasha, czyli na przykład wyciekła jakaś baza i mamy hashe hasu z tej bazy, no i nie da się jakoś wygenerować z tego hasha jakiegoś hasła, które pasuje do tej bazy. Oczywiście można to zrobić za mocną brute force'a, tego się niestety nie da zatrzymać, no ale
to, że to jest jedyna metoda, no to właśnie wynika z tej reguły, czyli odporność na odwracanie hasha. A druga ważna rzecz, na którą hash powinien być odporny, to jest collision resistance, czyli odporność na generowanie kolizji, czyli bardzo trudno powinno być, znaczy niemożliwe powinno być w praktyce wygenerowanie dwóch hashy, dwóch wiadomości, które dają ten sam hash. No i to jest właśnie to, co zostało złamane nawet na piące w SHA-1 i w praktycznie wszystkich niezabawkowych funkcjach skrótu kryptograficznych, że resistance nie został załomany, ale collision resistance prędzej czy później został załomany. No i nie ma tu nic o uwierzytelnianiu, czyli haszowanie nie służy do uwierzytelniania też bez pozorom, a konkretnie do podpisywania wiadomości, więc to nie jest podpisywanie wiadomości. Tak nie należy podpisać
wiadomości, a mimo to dużo ludzi tak lubi podpisać wiadomości, do czego w sumie za chwilę dojdziemy. W internecie na Stack Overflow znowu jest milion kodów z tym, ale to już nawet nie chciałbym szukać. gdzie indziej, tak dla porządku, żeby nie było, to jest podpisywanie wiadomości, więc jeśli ktoś chce podpisać jakąś wiadomość, to należy to zrobić tak, czyli użyć konstrukcji, która się nazywa HMAT, czyli hash based message authentication code, nawet jest authentication w nazwie, więc widać, że to jest dobra metoda i w zasadzie jest to dokładnie to samo w kodzie, poza tym, że używamy HMAT, namiast SAD-256, czyli dla programisty to jest żadna różnica, a z punktu widzenia bezpieczeństwa jest to duża różnica.
A czym to się w sumie różni z punktu widzenia bezpieczeństwa? Więc wyobraźmy sobie taką sytuację, że mamy rabat na jabłka na przykład, bo czemu nie na jabłka, no i jest 10% rabatu. I jest on podpisany jakimś sekretem, żeby nikt sobie nie mógł inny wygenerować rabatu na jabłka. wytkownik dostaje ten rabat na jabłka, te dane plus podpis, który widać na dole, 8b coś, tylko że jest to podpisane za pomocą MD5, czyli funkcji skrótu, czyli to jest wielkie nie, tak nie należy robić, to jest akurat MD5, ale to samo zadziała dla SHA-256 albo SHA-1, wszystkiego poza SHA-3 i jak to można złamać? Można to złamać mniej więcej 5 minut, licząc instalację narzędzi, czyli instalujmy sobie który się nazywa hash pump, dajemy mu cztery parametry, czyli
dane, które mamy, hash, który był, dane, które chcemy dokleić i on nam wypluwa nowe dane, jakie mają być i nowy hash, który będzie. Czyli powiedzmy, możemy sobie dokleić do niego amount równa się 100, czyli rabat równy 100% i on nam wypluje jakieś tam śmieci i rabat równa się 100. I w tym przypadku założyłem, że dane są parsowane za mocą urle code, co jest dość spodobieczne, które są wyróbane w praktyce, wyrób pozorom i charakterystyczne jest to, że zazwyczaj nadpisywane są poprzednie parametry następnymi, czyli mamy parametry name równa się rabat na jabłka, później amount równa się 10 i dużo śmieci, a później amount równa się 100 i po zdekładowaniu wyjdzie z tego coś sensownego, czyli amount równa się 100 i name równa się rabat na jabłka. No więc
fajnie, sakowaliśmy sobie, możemy kupować jabłka, duży jabłek na zimę, no i cały ten atak zajmuje mniej więcej minuty, jak ktoś już ma to narzędzie zainstalowane, a jak nie, albo musi googlować to zajmuje 5 minut. Dlatego myślę, że używanie hashy do uwierzytlenia danych to jest zły pomysł, przy Macu by to było niemożliwe. No więc ja wiem, wy już wiecie albo wiedzieliście, że tak nie należy robić, ale jest dużo ludzi, którzy nie wie, że tak należy robić i na przykład MasterCard miał taki problem, w sumie nie do końca z tym związany, bo oni jeszcze bardziej pojechali, Ostatnio brali sobie dane, na przykład, które chcieli podpisać, bo to wyglądało tak, że po stronie sklepu były dane, czyli sklep wysyłał żądaniem, po stronie klienta w sklepie były
zapisywane dane podpisane i te dane były wysyłane do MasterCarda, więc jakby klient mógł sobie modyfikować te dane, tylko, że nie zagadzałby się wtedy podpis, no bo podpisujemy dane, co prawda haszem, ale zawsze, więc niby nic się nie da zmienić. I YouTube tak sprytnie, że brał najpierw cenę, doklejał do niej numer karty, doklejał do niej nazwę użytkownika i wszystkie parametry przesłane do serwera były tak sklejane razem ze sobą. I wtedy był weryfikowany podpis. No to w sumie samo z siebie jeszcze by nie było podatne prawdopodobnie, tylko że zrobili jedną ciekawą rzecz, a konkretnie brali wszystkie parametry od sklepu, nawet te, które nie były jakby zamawiane. Czyli można sobie było dodać własny parametr, na przykład podkreśnik B i napisać tam cokolwiek jak chce i to będzie
uwzględnione przy liczeniu podpisu. No i ciekawa rzecz w tym momencie jest to, że tak te dwie wiadomości z lewej i z prawej po sklejeniu ze sobą wszystkich parametrów dadzą ten sam wynik, co znaczy, że jakby nie kombinować, jak się je podpisze to będą takie same, czyli z lewej strony mamy coś, co kupuje 1000 elementów za jakąś kartę z jakiegoś sklepu, a z prawej strony mamy coś, co kupuje element za jakąś kartę z jakiegoś sklepu. I sztuczka polega na tym, że w sklep przekonujemy, że kupujemy 1000 elementów, a później płacimy za jeden i jesteśmy bogaci, mamy 1000 czegoś, np. jabłek czegoś. No i akurat w tym przypadku podpis by nie pomógł, ale zastanawiam się czemu takie wielkie coś jak MasterCard używa hashy, to MD5 do
podpisywania danych. żeby nie było, że to jest jedyne miejsce, gdzie można zrobić błąd, albo że tylko Mastercard jest zły, bo robi błędy, to bardzo podobna sytuacja miała miejsce w Polsce w roku, dwa lata wcześniej, tylko że trochę inaczej skończyła, czyli też była branka płatności, też było bardzo podobny błąd, czyli błąd przy podpisywaniu, no i tylko, że podstawowanie serwera bardziej, ale mniejsza z tym, tylko że trochę inaczej skończyła, bo badacz, który to zgłosił, dostał odpowiedź od helpdesk, że no rzeczywiście zostało to porówione w dwie godziny, no i helpdesk napisał, że prezes zadzwoni, będą złote pociągi nagrody, wszyscy klienci się dowiedzą i tak dalej, no a w sumie to minęły te dwa lata, no i ani prezes nie zadzwonił, ani złotych pociągów nie było, ani w sumie klienci
dalej nie wiedzą, że był problem i w sumie stąd nie podał nazwy, bo nie wiem czy mogę, więc przejdźmy może dalej, żeby nie było, że tylko nad jednym sklepem się znęcam. Mamy na przykład .pay, spokojnie tutaj już nie mam żadnego błędu, Co ciekawe jest, że podpisujemy wszystko SHA1 no i robimy dokładnie takich mastercard, czyli sklejamy wszystkie parametry. I może w tym nie ma błędu, może w tym jest błąd, ja jakoś nie jestem przekonany, że ktoś kiedyś nie zrobi czegoś, co spowoduje, że będzie można grać pieniądze. No po prostu sklejamy wszystkie parametry i liczymy na to, że nie da się tego oszukać. No i mam jeszcze przelewy 24, które w sumie są najlepsze z tych wszystkich poprzednich trzech pod względem protokołu, tylko Sekret ma 16
znaków szesnastkowych, co jak się dobrze policzy daje 8 bajtów, co daje 64 bity, no i to nie jest jakoś bardzo dużo wbórch pozorom. To jest coś, co można, może na laptopie takim zwykłym dograniu się tego nie zbrutuje, ale jeśli się ma jakiś dobry klaster, to można to spokojnie złamać i robić dowolne przelewy z tego sklepu w nieskończoność. Więc najpierw trochę trzeba wydać na prąd, a później można poszaleć. z kupami z przelewu 24. Więc to jest o tyle problematyczne, że tego się za bardziej nie da naprawić, tzn. każdy klient musiałby wygenerować nowy sekret i ustawić sobie w panelu, a ludzie zazwyczaj mam tendencję do, no nie chcą robić nowych rzeczy przy swoim sklepie, jak działa, no
to po co ruszać. No i tym kończymy drugą część, bo chciałbym jeszcze powiedzieć coś o trzeciej.
niektórych to najbardziej interesuje, no bo o ile te poprzednie rzeczy są dość, no jakby można o tym przeczytać w internecie, to to jest dość część, która jest przygotowana specjalnie na konferencje, no bo w sumie nie planowałem na początku o tym mówić, ale tak jakoś wyszło, że o tym powiem, o czemu zaraz. No więc jeśli używanie prymitywów kryptograficznych jest trudne, no to Wtedy, tworzenie własnych prymitywów kryptograficznych i jeszcze ich stworzenie najpierw musi być bardzo trudne, tak, odpowiedziałem na swoje pytanie i dlatego, że
tworzenie prymitywów jest trudne. Tutaj jest przykład funkcji skrótu, które były używane podczas, nie wiem, historii świata, no i widać, że jest taki trend, że powsta jakaś funkcja skrótu, jest dobra, zielona przez parę lat, czasami 10, czasami mniej, czasami więcej, ktoś w końcu znajduje w niej jakiś problem i ją łamie. I to nie znaczy, że ten, kto wymyślił funkcję nie umiał kryptografii, tylko że po prostu jest trudno, że żeby zaatakować kryptografię, starczy znaleźć jeden błąd, a żeby stworzyć coś niezłamywalnego, trzeba przewidzieć wszystkie możliwe ataki, a cały czas powstały nowe ataki. No dlatego jest trudniej bronić niż atakować. No i właśnie dlatego zainteresowałem ja drugi temat, który tutaj pokazałem, bo okazało się, że na tej konferencji i to u mnie będzie prezentacja o kryptografii konkretnie o własnych funkcjach haszujących,
co w sumie bardzo mi spasowało, bo było takie trochę pod mój tok, więc postanowiłem trochę przeanalizować tą funkcję i zobaczyć, co się z nią da zrobić, bo lubię wyzwania i dlatego zamiast robić slajdy, to pisało mi dziwny kod w Pythonie, no ale okazuje się, że ja nie znałem tej funkcji, ale dużo ludzi znało tą funkcję, były o niej jakieś papery, jedną część, no ale co się w niej w zasadzie dzieje? O tym więcej będzie jutro pewnie, ale
wypadałby podsumować w paru słowach. Tu jest jakiś obrazek, który spróbowałem zrobić, nie wiem na ile dobrze mi to wyszło, bo nie jestem dobry we blaski, ale generalnie chodzi o to, że zaczynamy z jakimiś czterema stałymi ustalonymi, mamy C0, C1, C2 i C3 i to są cztery elementy stanu. No i na początku pierwszy element tego stanu ksorujemy z bajtami, jest pierwszym blokiem danych, które haszujemy i szyfrujemy rundą ASa. Później to samo z drugim elementem stanu, trzecim i czwartym. No i później powtarzamy, że znowu pierwszy element stanu xorujemy z drugim blokiem danych, które haszujemy i szyfrujemy ASem, znaczy rundą ASa i to samo z drugim elementem stanu, trzecim i tak dalej. I na końcu jest finalizacja, która jest silna. No i
jako że ja wolę kod, nie wiem czy tutaj coś widać, kodu jest to trochę bardziej czytelne, nie ma jakichś dziwnych kwadracików, mamy sobie funkcję update, która robi 4 razy update rundy i funkcję finalize, której nie ma co rozpisywać, to jest w zasadzie szyfrowanie ASM, które no jest mocne, ale jeśli chcielibyśmy wygenerować sobie kolizję, to w sumie finalize nas nie interesuje, bo jedyne co musimy zrobić, to wygenerować 4 stany, które przed finalizacją będą sobie równe, bo jeśli przed finalizacją to się sobie równa, no to po finalizacji też będzie, więc no jakby jak może coś takiego zrobić, albo jak to zamodelować. Najpierw zobaczmy co się stanie, jeśli będziemy szyfrować wiadomości z czterema blokami, to jest coś takiego jak widać tutaj na slajdzie,
o ile widać, czyli szyfrowanie czterech bloków wiadomości polega mniej więcej na tym, że robimy update na, wywołujemy tą funkcję update na pierwszym bloku, drugim bloku, trzecim bloku, czwartym bloku i na koniec robimy finalizację, przy czym finalizacja jest nam niepotrzebna, więc jeśli będziemy mieli dwie wiadomości, dla których risa będzie równa, no to będziemy mieli kolizję. I to można, tak, tutaj uwaga, bo będzie dużo matematyki albo jakichś dziwnych wyprowadzeń, jak można do czegoś takiego podejść. Więc na początku tak bardzo wysokopoziomowo definicja kolizji brzmi więcej tak, czyli mamy stream hash A równa się stream hash B, czyli dwie wiadomości, które po zhaszowaniu dają równe rzeczy. No i to na początku można sobie rozwinąć, czyli użyć update, dał to na dół slajda, niestety, więc nie wiem czy widać, no ale ogólnie
chodzi o to, że po tych czterech update'ach dla a1, a2, a3 i a0, wynik funkcji będzie równy dla wyników funkcji po czterech update'ach dla b1, b2, b3 i b0, no i teraz uwaga, bo tu się zaczyna robić dużo AS-ów, to jest dokładnie to samo co poprzednio, tylko rozpisane dokładnie i teraz
Trzeba w zasadzie rozumieć, co tu się dokładnie dzieje, żeby zrozumieć, co chcę powiedzieć, bo
liczy się to, że jakby to jest równoważne poprzedniemu side'owi, czyli temu, czyli dalej, jeśli znajdziemy rozwiązanie tego równania, no to mamy równanie na kolizję. To jest zwykłe równanie matematyczne, mimo że są to jakieś ASy, AS to jest równie dobra funkcja matematyczna jak każda inna, więc możemy sobie używać zwykłych technik. Na przykład możemy sobie wprowadzić zmienne, żeby to było trochę krótsze, żeby możemy sobie wprowadzić jeszcze więcej zmiennych, żeby było jeszcze krótsze, no i w tym momencie już to trochę lepiej wygląda. No i na przykład teraz widzimy, że w każdym z tych czterech równań mamy jakieś szyfrowanie ASM, więc możemy sobie, AS to jest dobra funkcja matematyczna, więc możemy sobie obu stronnie zdeszyfrować ASM równanie. W liceum tak nie robiliśmy, no ale możemy robić tutaj, nikt nam nie
zabroni, jesteśmy wolni, Zdechfrujemy sobie w obu stronie AS wszystkie broki, no i wychodzi nam coś takiego jak na dole, czyli znika nam AS pierwszy. No ale dalej są dwa ASy, więc co można zrobić? W sumie jeden. Więc co można zrobić? Można przenieść... ten XOR-owanie z A3 na jedną stronę, żeby... No, było trochę lepsze równanie. Mamy coś XOR coś, równa się coś XOR coś, a chcemy mieć XOR tylko po jednej stronie. No więc przenosimy, wychodzi wynik jak na dole, no i dalej. Mamy znowu teraz dużo ASów, ale dalej już w sumie nie pójdziemy bez trochę głębszego zagłębiania się w ASa, bo niestety już też nie da zarobić jakiejś sztuczki, żeby to zeszfrować, no ale AS to nie jest jeszcze takie dno, na które możemy
zejść, bo możemy jeszcze ASa rozbić na cztery części, bo runda ASa składa się z czterech operacji, konkretnie z dodawania klucza rundy, miksowanie kolumn, przesuwania wierszy, a na koniec jeszcze z czyli operacji, która po prostu podmieniała bajtę w wyniku. No i w tym momencie to już znowu wygląda skomplikowanie, ale co jest ważne, że dalej, jeśli rozwiążemy to równanie na dole, no to będziemy mieli rozwiązanie dla całej kolizji, całego hasha. No więc możemy zrobić, na początku zdjąć addround key, bo to jest po prostu exerowanie, to nie jest żadna magia, addround key to jest parametrem x, to jest po prostu exor z x, tylko się nazyła mądrzej, bo kryptografie wylubią nazwy, i możemy sobie zmienić to na exerowanie, a później widzimy, że exerujemy obie strony z tą samą wartością,
więc możemy to w ogóle usunąć. No i znika nam przynajmniej jedna rzecz. A teraz możemy z kolei znowu przenieść parametry na jedną stronę, znaczy już mamy, ale możemy je skorzystać z takiej własności AS, o której nie uczą w liceum, konkretnie, że jeśli mix columns exerujemy z czymś, to można tego exora włożyć do środka, jak zrobimy na nim operację odwrotną. To jest skomplikowanie i to w sumie nie jest jakoś ważne, ważne, że może to sobie na kartce wyprowadzić dość łatwo, no i włożyć do środka, tak, do środka AS-a. No i teraz mamy po stronie, znowu operację, gdzie po obu stronach jest mix columns, więc możemy sobie obu stronie odmiksować te kolumny. No i teraz mamy analogiczną sytuację, tylko że z operacją shift-rose, czyli możemy obu stronie wziąć i
włożyć do środka odwrotność tego XOR-a shift roads, no i sprowadzamy się do czegoś, co jest już bardzo proste, znaczy już znowu nie ma ASa, zostały tylko subbytes, które jest niestety bardzo, bardzo niefajną funkcją do kryptoanalizy, to jest w zasadzie tylko podmiana wartości na elementy tablicy, ale mimo wszystko SCORmy się w ogóle nie komponuje, więc trzeba użyć czegoś innego. Na początek możemy sobie przenieść wszystkie elementy na jedną stronę, no i teraz widzimy, że po jednej stronie mamy jakieś operacje, te invmx, invsr, to w zasadzie To nie jest takie ważne, co to jest, bo to są jakieś operacje matematyczne na stałej, więc to jeśli po prostu damy, nie wiem, x pod to i zauważymy, że z prawej strony mamy coś innego, w sensie jeśli mamy
x równa się a i x równa się b i x równa się c i x równa się d, no to znaczy, że a równa się b, a równa się c równa się d, czyli ten cały układ równań można w tym momencie do jednego równania sprowadzić, które wygląda tak, no nie jest znowu piękne, ale się przynajmniej mieści w jednej linijce, przypomnienie, że te wszystkie operacje, które robiliśmy, były odwracalne, więc możemy sobie po prostu wziąć i jeśli znajdziemy rozwiązanie dla tego równania, w sumie równości czy coś, to mamy znowu równanie na kolizję, więc jak można do czegoś takiego podejść? Tutaj jest skomplikowany obrazek, co robi SB, chociaż to nie jest w sumie takie ważne, bo to jest po prostu operacja, która
bierze jakieś elementy z tablicy, losowe powiedzmy, tak naprawdę nie do końca losowe, To jest skomplikowany wykres, który pokazuje ciekawą rzecz.
A konkretnie, że pierwszy element wyniku zależy tylko od pierwszego elementu B0, pierwszy bajt wyniku zależy od pierwszego bajta B0, pierwszego bajta duże B0, pierwszego bajta A0, pierwszego dużego bajta E0, bajta dużego A0, no i tak samo drugi bajt wyniku, trzeci bajt wyniku, czwarty bajt wyniku. Dlaczego to jest ciekawe? Bo to znaczy, że być może by się dało coś brute force'ować, byte po byte'cie, co jest tak jakoś dwa do dużej potęgi szybsze niż brute force'owanie wszystkiego od razu. No i czy da się coś takiego zrobić? Jeśli będziemy brute force'ować, załóżmy najpierw, że mamy tylko dwa równania, no i w sumie to da się tutaj coś takiego zrobić. Jeśli byśmy mieli tylko dwa elementy stanu, no to atak by był
prawie że trywialny, czyli brute force'ujemy sobie, ustalam jako stałe i duże A1 i duże B11 i duże A11, to są te zmienne, które podstawiliśmy na początku, to nie ma znaczenia, co nam się znajduje w zasadzie. No i możemy sobie wybrutowolować A2 i B2, a w zasadzie wystarczy samo A2, bo mamy 256 możliwości, a szansa, że jakoś tak losowo się nam po szczęści jest 1 do 256, więc statystycznie, a w zasadzie w 100% przypadków nam się uda. I to samo się odnosi do trzech elementów stanu, czyli kiedy mamy trzy elementy znaczy ignorujemy to czwarte równanie, nie musi być spełnione filowo, no to możemy być to samo i bruttofosować i A2 i B2. I taki atak kosztuje nas 2 do 16
operacji, czyli grosze, to jest 60 tysięcy operacji, 65 tysięcy 536 dokładnie, no i to jest do zrobienia na kalkulatorze w poniżej sekundy, tylko że niestety jest problem, jeśli byśmy chcieli atakować pełen stricharz, że Tu jest kod, jakby ktoś chciał sobie złamać trzy rundy stream hasha. No i w zasadzie jest to parę linie, które brute forceują to równanie, które wcześniej wyprowadziliśmy.
Choroba boli.
Żyję? Chyba nie. Przepraszam, jestem chory trochę, więc teraz tylko blaski będą.
Ale spokojnie już kończymy, jakoś dożyję. Więc teraz jest problem, ale okazuje się, że jeśli cofniemy o rundę w AS-ie, to możemy brutfalsować nie po bajcie, tylko po bloku. Czyli spoko, mam jeszcze wodę, dziękuję. Czyli możemy brutfalsować... i wtedy mamy szansę 1 do 34 miliardów, że nam się uda, co nie jest jakoś bardzo dużo, ale komputer ciągle ogarnia, więc jeśli połączymy to z poprzednim atakiem, to daje nam to złożoność 2 do 48, co już zajmuje dużo, ale jak to się odpali na odpowiedni długi okres czasu, na przykład parę godzin, no to da radę. No i jedna zmiana, której to wymaga w kodzie, tak no musiałem przepisać na cel, no bo niestety nie działo, takie coś, czyli tutaj jest zmienna mod, parametr mod
w pętli, w którym budyforsujemy wszystkie możliwości DWorda, no i podstawiamy odpowiednie miejsce. Jeśli coś takiego zrobimy, to okazuje się, że to nawet działa i da się wygenerować takie dwa pliki, które dają kolizję, więc oznacza to, że być może stream hash w obecnej wersji nie powinien być używany, przynajmniej w praktycznych zastosowaniach, Mamy jednak różne pliki, np. SHA-512 daje inny wynik. I co chciałem przez to przekazać? Chciałem przez to przekazać, że własna kryptografia jest trudna. Chciałem przez to przekazać, że jeśli nawet zawodowi kryptografowie robią algorytmy, które się da złamać, np. MD5 albo SHA-1 albo StreamHash, to szansa, że jakiś szary człowiek, jak np. ja albo pewnie większość z was wymyśli coś innego, jest prawie że zerowa. Więc dlaczego się tak
dzieje? To już mówiłem, że atakowanie jest zawsze prostsze niż obrona, to znaczy przewidzieć wszystkie możliwości ataku poza jednym, no i ktoś prędzej czy później to znajdzie. Dlatego tacy ludzie jak na przykład ja, który w zasadzie bardziej broni systemy niż atakuje, mają ciężkie życie, no bo prędzej czy później ktoś się łamie, a później jest pytanie, dlaczego tego nie przewidziałeś. No niestety się nie da. No i to jest w zasadzie tyle, został mi epilog, jeszcze może trzy minuty głosu, więc... Ktoś jest zainteresowany tematem i chciałby coś, gdzie jest mniej kotów, a jakoś więcej contentu albo coś ciekawiej przedstawione, to ten pierwszy artykuł mnie kiedyś zafascynował jest właśnie o szyfrowaniu i o tym, dlaczego nie powinno się używać ASa bezpośrednio, a drugi artykuł to jest samo
reklama, bo w sumie napisałem do programisty o czymś podobnym i tam też jest mądrzej niż tutaj, to znaczy jest więcej faktycznie kryptografii, a mniej kopiowania kodu jest tak overflow, no i być może jeszcze będzie trzeci artykuł, Jak ktoś jest bogaty, to może kupić tę programistę, tego programistę, coś, w tym miesiącu wyszedł, a jak nie, to mam pozwolenie, żeby za pół roku to wypuszczać do internetu, więc można poczekać. I jeszcze jak ktoś lubi robić jakieś dziwne rzeczy w jakimś fajnym miejscu, to okazuje się, że jest takie miejsce na świecie i nawet rekrutujemy i nawet nie trzeba wiedzieć jakoś bardzo dużo, chociaż coś tam warto wiedzieć, na przykład co to jest komputer albo coś. No i nie wiem, można wysłać CV, nie zaszkodzi, nie wiem, na pulpicie komuś z nas
zostawić, to na pewno się odezwiemy wtedy. No tak, i dziękuję wszystkim, w sumie tyle.
I czy ktoś ma pytanie jakieś? Czy dałoby się może zatrudnić, nie wiem, typu, no dobra, nie będę używał jakichś takich frazesów typu AI, żeby sam wygenerował jakiś algorytm, Sztuczna inteligencja generowała się algorytm szyfrowania. Żeby sama próbowała w siebie później zauwać, czy mogę, mogę, nie mogę. Znaczy zrobić by się na pewno dało, pytanie jakie by to dały wyniki. Generalnie sztuczna inteligencja, nie jestem ekspertem jakby, ale działa tak, że uczy się na wielu, wielu przykładach. No właśnie, chodzi o analizę tych wielu przypadków, bo człowiek może przeanalizować n, a oni 100n.
ale przez to mamy tu mocnych komputerów, więc oni mogą sobie, mogę sobie przetarzywać ileś tam miliardów. Wydaje mi się, że to nie mogłoby działać na, w sensie jest tak, że czasami się wynajduje nowy algorytm, nową metodę ataków, na przykład Square Atak został wynaleziony na potrzeby umania Square'a właśnie i okazało się, że jest dobry na S-a i chodzi o to, że co jakiś czas powstają nowe metody ataków na szyfry, których się wcześniej nie dało przewidzieć, więc sztuczna inteligencja jakby nie mogłaby przewidzieć tych metod ataków, żeby się przed nimi obronić. To po pierwsze, a po drugie, że trzuczna indygencja działa tak heurystycznie mocno, więc kod, który by stworzyła, wyglądałby prawdopodobnie jak wielka masa spagetti. I to może by było dobrze, może nie, tylko że jest problem, że np.
urządzenia typu routery czy coś też chcą szyfrować i deszyfrować, no i to mogłoby bardzo wolno działać na nich. Np. AS został stworzony celowo tak, że jest bardzo szybki do zaimplementowania hardware'owo, a jednocześnie da się go przyspieszyć używając RAM-u, ale w sumie nie trzeba używać RAM-u jak ktoś nie ma RAM-u, więc wydaje mi się, że zaimplementowanie czegoś takiego w sztucznej diagencji by było bardzo trudne, może nie niemożliwe, ale mamy jednak ograniczone możliwości obliczeniowe ciągle. To może ja? Michał Trojnara, autor StreamHasha. Po pierwsze chciałbym podziękować bardzo za krytyczne spojrzenie na mój pomysł. Jutro będę trochę o nim więcej opowiadał dla tych, którzy dotrwają do wieczornych. Ja się usprawiedliwie, ja wcześniej pisałem z Michałem, Michał nie miał przeciwko, żeby zaprezentować i jest bardzo dobrym
człowiekiem, tak... prywatnie.
Także bardzo fajnie, że ktoś, znaczy te algorytmy, które, z którymi konkurujemy, które przez profesorów uniwersytetów różnych zostały stworzone, to one były przez ich grono studentów, tak. My, którzy tutaj pracujemy jakoś tam plus minus samodzielnie, tak jak ja, nie mamy tego komfortu, żeby uzyskać rzetelną ocenę przed upublicznieniem tej swojej pracy. Dlatego dla mnie to jest bardzo cenne, że ktoś mógł na to krytycznie spojrzeć i no jest to możliwość poprawy i
wersji piątej algorytmu, która będzie lepsza, ale o tym więcej wczoraj. Jutro. No tak. więcej jutro na ostatniej sesji. Natomiast jedna drobna uwaga co do treści, jeśli chodzi o message digest zrobienie przy pomocy funkcji skrótu, no to tam wystarczy, nie potrzeba ichmaka stosować, wystarczy umieścić, żeby zapobiec atakowi length extension wystarczy sekret umieścić na końcu. Tak, po wiadomości. Tak, wystarczy na length extension, ale to też nie jest idealne rozwiązanie, co o czym, no Natomiast oczywiście HMAC został skosłowany tak, żeby oprócz tego, żeby zapobiec Length & Stention również umożliwić, zapewnić bezpieczeństwo wartości message digest, nawet jeżeli funkcja skrótu, która pod spodem siedzi nie jest idealna. Tak, jasne. Tylko, że miałem 160 slajdów i w sumie jestem zdziwiony, że zdążyłem w ogóle
w godzinę, więc staram się, no, tak. Nie wchodzi w takie rzeczy, ale oczywiście racja. Jutro mam nadzieję, że będzie o tym. Jeszcze takie pytanie było za pośrednictwem sieci. Ludzie się pytali, czy gdzieś udostępnisz tą prezentację, żeby sobie mogli poczytać i poklikać po niej. Tak, ona jest w ogóle w HTML-u, więc można dużo klikać i na moim blogu tailcall.net czy coś, tam na początku było, będzie wrzucone. Okej, dzięki. Ktoś jeszcze? Chyba tyle. To dziękuję.
Przerwy na przepinkę.
Proszę zająć miejsca, będziemy zaczynać.
No to Kamil dajesz.
Chciałem opowiedzieć o projekcie, który w zasadzie już od ponad roku ciągnę, mianowicie fazowanie różnych projektów open source. Generalnie powinniście mnie znać, gdyż jestem tu już trzeci raz, trzeci raz, w 2015 mówiłem o routerach Soho i o podatnościach, niektóre udało mi się znaleźć. w 2016 właśnie zaczynałem ten projekt i opowiadałem powiedzmy jak podejść do tego procesu, natomiast teraz takie powiedzmy no quasi podsumowanie, gdyż jeszcze go nie skończyłem, cały czas to robię, bo cały czas są błędy, więc no trudno, dopóki nie wyeliminujemy ich wszystkich, no to tak, będziemy to robić. Rekrutuję w CERT Polska, tak jak pozostałych dwóch moich kolegów, którzy prezentowali wcześniej, zajmujemy się różnymi rzeczami, tak jak też koledzy mówili rekrutujemy, więc jeżeli ktoś chce robić różne dziwne rzeczy, no to zapraszam.
Miley są podane, poza tym prowadzę w czasie prywatnym bloga, trochę tweetuję, ale nie ma szału, więc tak jakby Twitter nie jest moim źródłem kontaktu ze światem. O czym chcę powiedzieć, generalnie dlaczego to wszystko tak, no bo tak, to
Ciężko jest rozumieć, dostawałem takie pytania, pamiętam między innymi też od Michała, że po co to robimy, dlaczego, jako mamy z tego korzyść, jako powiedzmy mój zespół, moja firma tego typu rzeczy, powiem zaraz dlaczego. Trochę statystyk, trochę czego się nauczyłem, bo to nie jest takie oczywiste, niektóre rzeczy wychodzą właśnie w praniu, przede wszystkim ważny tutaj taki miękki, to jest nowość moich slajdów, bo zawsze starałem się robić techniczne slajdy, Cięka część jak pracować z deweloperami, gdyż to nie jest takie oczywiste i zgłaszanie błędów często tak jakby no, trzeba to robić dobrze, to nie jest, tego trzeba się nauczyć. No i oczywiście część techniczna, czyli co udało się znaleźć z ciekawszych przypadków, bo żeby opowiedzieć o wszystkim, to by musiał siedzieć tutaj 3 dni i wy byście
nie wytrzymali, ja pewnie też. Więc tak, dlaczego? Przede wszystkim tak, jak większość rzeczy, bo można, nikt tego prawie nie robił, zaczynałem, to jest końcówka września 2016 roku, więc tak jakby podejście deweloperów w tym momencie się zmienia, natomiast no wtedy było to, mimo że to było tylko rok temu, to jednak to wyglądało nieco inaczej niż teraz. W pracy czy prywatnie moje rozwiązania wykorzystują komponenty open source, więc automatycznie bezpieczeństwo tak jakby tych klocków, z których się składają te rozwiązania, tak jakby te rozwiązania też są bezpieczniejsze, więc to jest sytuacja win-win. No deweloperzy najczęściej są funkcjonalni, tak jak pokazywał MSM, nawet w przypadku e-commerce tak rzadko to jest, że tak powiem tworzone z myśl o bezpieczeństwie, często są to copy pasty ze staka i nie tylko, więc
też warto byłoby, by coś takiego zrobić, chociażby żeby to bezpieczeństwo poprawić. No i tak jakby mało osób psuje kod, zdecydowanie za mało osób psuje kod, trzeba to robić, tak jak jak pokazywał MSM, bo faktycznie wychodzą różne kwiatki, często bardzo dziwne. Dlaczego ta technika? Jest bardzo efektywna, sobie świetnie radzi ze znajdowaniem nowych ścieżek w kodzie, są bardzo solidne rozwiązania open source, jest AFL Michała Zalewskiego, Leapfazer, co łączą z tak jakby częściami LLVM-a, adres sanitizerem, memory sanitizerem i nie tylko, więc tak jakby to są, znaczy bardzo ułatwia pracę, tak, to nie jest, w zasadzie to można powiedzieć, że ten projekt od kiedy go zacząłem, to poza użeraniem się z deweloperami to jest dla mnie sama przyjemność, tak,
mimo że musiałem napisać sporo kodu, zautomatyzować różne rzeczy, to jednak mimo wszystko, tak, to wszystko tak, to tak, stoi na ramionach gigantów, więc jest to fajne, jest to szybkie, tak, jestem w stanie uzyskać, zaraz pokażę ile wykonań przez fajny okres czasu i prosto się skaluje, wystarczy dokładać serwery, no i to działa, tak. Natomiast problem jest jeden, jest niski próg wejścia, ale żeby to robić tak na skalę naprawdę fajną, to ciężko jest to, ciężko jest w ogóle, tak jakby no wypracować pewne rzeczy, trzeba cały czas się uczyć.
44 projekty to są między innymi, tak jakby generalnie starałem się wybierać projekty, które po pierwsze duży jest impact w przypadku znalezienia jakiejś luki, druga sprawa jest taka, te projekty, których ja używam w swoich rozwiązaniach, w pracy i nie tylko. Udało się znaleźć 361 bugów, 323 zostały poprawione, natomiast niepokojące jest to, że w połowie projektów, bo akurat tak się złożyło, znaleziono więcej niż jeden błąd, więc to świadczy o tym, że naprawdę nie jest dobrze. 101 CV-ek zebrałem, stan na wczoraj, gdyż wczoraj wpadły mi dwie, o zjadłem literkę, najszybciej znaleziona luka, dwie sekundy, use after free viarze, najdłużej szukana luka, bardzo ciekawa, później o niej powiem, to około 879 godzin, mówię około, bo dokładnie nie jestem w stanie, tak, oszacować
ile tego, natomiast 16 serwerów w projekcie, 7 fizycznych, 9 VPS-ów, to nie były jakieś super, hyper VPS na ażurze, korzystałem tutaj kryptoreklama, zaruby, więc za 4 złoty netto miesięcznie można mieć całkiem fajną moc obliczeniową, 20 giga SSD i 1 gigabajte RAM-u. tam widziałem, że niektórzy wyglądają, bo nisko na slajdzie są niektóre teksty czy schematy będą, to proponuję włączyć streama, na streamie będzie wszystko widać i po prostu slajdy, to jest bardzo dobre rozwiązanie, rok temu to testowałem, teraz też widzę, że niektórzy oglądają streama zamiast patrzeć na slajdy i całkiem to się sprawdza. Tak, top 6 dziurawych projektów, generalnie najbardziej dziurawy jest TCP dump, przynajmniej był, tak, ponad miliard wykonań, Faktycznie to jest szybka binarka, tutaj inputem były pick-upy, pick-upy z różnym ruchem sieciowym, gdyż
nie każdy wie, ale TCP dump poza zbieraniem ruchu może też ten ruch analizować, ma wbudowaną, że tak powiem, wbudowane masę parserów różnych dziwnych protokołów sieciowych na różnych poziomach ISO-C, więc to jest fajne, to jest fajne. Drugim, drugim, drugim, słucham? Okej, to nie było pytania. Drugim projektem jest GoStrip, nie wiem czy ktoś kojarzy GoStripta, wie do czego służy. Generalnie to jest bardzo koblascy projekt, gdyż on może być używany jako parser do PDF-ów, dokumentów po script, może jest z tego co wiem używany jako jakiś element właśnie renderujący w drukarkach, osadzona wersja, więc też całkiem fajny impact. Słucham? Okej, okej, no do poproszenia się o kłopoty generalnie. Kolejny projekt to jest LIBA-V, jakby ktoś nie wiedział to jest fork FF-MPG, który w 2010, albo 2012 roku tam
się rozdzieliło, że FF-MPG poszedł jedną ścieżką, LIBA w drugą ścieżką, radar, o kurczę, nie poprawiłem, z radara mam 18 CV, więc powinienem podskoczyć, bo te dwie co dostałem wczoraj Jara, Jare to powinniście znać, jeżeli macie jakieś pudełka w firmie czy nie tylko, to na pewno Jare znacie, ale Jara o tyle dobrego wiarza jest to, że jest szybka i jest bardzo responsywna, w zasadzie te błędy, podobnie jak w radarze, te błędy są łatane momentalnie i dzięki temu można zacząć kolejną iterację fazowania i kolejny projekt to są wyrażenia regularne PCR-E2, Perlowe, też bardzo fajny projekt, no tutaj widać wyraźnie, które targety są szybkie, które nie. W przypadku szybkich targetów to są właśnie jakieś parsery tekstowe, no to tak nawet do
4 miliardów prawie dochodzi liczba wykonań przez ten rok uzyskane, natomiast w przypadku wolniejszych projektów, takich jak GOSPY, jedynie 80 milionów, ale mimo tego udało się tak znaleźć 18 różnych błędów, które, że tak powiem, zostały zaakceptowane do CV-ki.
właśnie mogło dziwić to, że tutaj jest tego tak dużo, bo to są, no tutaj Libaw się, 22 tysiące to jednak jest dużo crushy, natomiast schemat, znaczy ogólnie brałem to, statystyki są statystykami głównie z EFLA, więc po prostu tak przeczytajmy to, co ma autor na myśli tak implementując feature unikalnego crusha. Generalnie to jest tak, że jeżeli jakaś część, że tak powiem, już nie będziemy tutaj chodzić w basic block i w takie rzeczy, to nie jest ważne w tym momencie. Jeżeli jakieś wykonania delikatnie się nawet różni, to już wtedy to jest unikalny crash, więc po prostu to powoduje, że te liczby są tak kosmiczne, natomiast rzeczywiście faktycznych crash po odfiltrowaniu, które są istotne, no jest zdecydowanie dużo mniej. Oczywiście tak jakby, jeżeli mówię unikalny crash, to
wychodzi z tego, że z tych 916 crashy tak 40 CV-ek. to jest suma wszystkich znalezionych crushów podczas wszystkich iteracji fuzzingu. Tutaj jesteśmy, znaleziony typy podatności. Cieszy jedna rzecz, że deweloperzy tak jakby nauczyli się, widać trend, że deweloperzy nauczyli się bronić przed po prostu przypełnieniami bufora, gdyż takich błędów jest relatywnie mało, widzimy, przypełnienia bufora na stosie to jest niecały procent wszystkich znalezionych błędów, tak samo, tak samo tutaj invalid write, jako invalid write mam na myśli to, że po prostu gdzieś piszemy, nie gdzie tam trzeba, ale niekoniecznie poza bufor, tak, więc to mogą być po prostu jakieś uszkodzone wskaźniki czy takie rzeczy, natomiast tych błędów też jest mało, najwięcej oczywiście, tak, dereferencja pustych wskaźników i odczyty poza, ponad połowa błędów to są odczyty na pamięć poza
buforem, bądź odczytanie jakiejś pamięci, którą nie powinniśmy odczytywać. Te błędy akurat w przypadku, tak, tej największej części, dwóch największych części tortu mogą skutkować tym, że uda nam się przełamać SLR-a i po prostu wylikować jakiś pointer i tak najzwyczajniej w świecie cały SLR i randomizowana pamięć procesu tak no niestety nie zadziała tak jak powinna. Z takich ciekawszych rzeczy to w zasadzie duży, tylko wskaźnik dużych błędów, duży wskaźnik błędów use after free, natomiast tak jakby te błędy niekoniecznie były eksploitowalne w tym sensie, że można byłoby coś z tym zrobić fajnego. To były błędy na przykład przy zwalnianiu pamięci, tutaj opowiem o takim błędzie, że gdzieś zwalnialiśmy za dużo pamięci, takie przepełnienie bufora tylko zwalnianego i po prostu w pewnym momencie
zwalniając pamięć, ta pędla, która się kręciła, dotykała już zwolnionej pamięci.
generalnie tak, zamiast robić jakieś opisy, które mają 10 slajdów, lepiej jest zawsze obrazy zrobić. No proces fazowania generalnie sprowadza się do kilku prostych kroków, ale nieco upierdliwych, zwłaszcza te na dole, zarządzanie korpusem i zarządzanie crashami jest niesamowicie upierdliwe i właśnie to trzeba wszystko dobrze odfiltrować, tak samo dobrze łączyć te korpusy po kolejnych iteracjach fazingu, żeby faktycznie coś fajnego osiągnąć. Natomiast tak na początku skrapujemy sobie internet, szukamy jakichś różnych PDF-ów do Kiksów, co tam nam się podoba, które będzie po prostu targetem do niszczenia naszego programu. Tak, wyszukujemy najlepsze, najlepsze, najlepsze rzeczy, czyli to jest tak, badajemy tak jakby to wszystko,
strzałkami przerwanymi z tego powodu, że to jest tak jakby w gruncie rzeczy jeden krok. Wszystko się zawiera w minimalizacji korpusu, natomiast z racji tego, żeby tak jakby uświadomić zagadnienia, jakie później będą poruszane, musiałem to tak rozdzielić dziwnie. Tak badamy code coverage, czyli szukamy jak najmniejszych elementów korpusu, które docierają do największej ilości ścieżek w kodzie. No to jest logiczne, tak? To jest po prostu proste wybieranie najlepszych, że tak powiem, algorytm genetyczny, tak, najlepiej przystosowane osobniki, tak, później zaczynamy fazować, czyli przepuszczamy już nasz korpus przez jakieś różne dziwne modyfikatory i ładujemy to w nasz program i generalnie później, jak już coś znajdziemy, to zarządzamy, tak, crashami, czyli musimy odfiltrować duplikaty, wiadomo, unikalne, gdyż jak widać, ten algorytm badania
unikalności crashy jest niedoskonały, podczas tak wykonywania kodu mamy ograniczone informacje odnośnie tego, co nam się stało i tak, ja napisałem sobie specjalne rozwiązanie, które automatyzuje to wszystko i robi za mnie to samo, czyli po prostu zbiera korpusy, łączy je, wybiera najlepsze, gdyż pewnie bym nie wychodził z prac od 8 do 22, jakbym to robił ręcznie. Generalnie budowa korpusu jest prosta, jest udostępnionych dużo różnych zasobów w internecie, nawet Mozilla udostępnia to, czym karmi swoje fazery. Tak najlepiej jest, jeżeli robimy to w jakiejś większej skali, czy nawet w skali własnego powiedzmy projektu, to warto po prostu budować to samemu. nie zdawać się na przypadkowe pliki z internetu, gdyż ten korpus za każdym razem, za każdą iteracją on ewoluuje, są
wyszukiwane coraz lepsze przypadki testowe, które są mniejsze, przede wszystkim chodzi o rozmiar, pod kątem mutacji tych przypadków testowych, no i oczywiście większy code coverage. Więc warto robić to na poziomie formatu pliku, jeżeli mamy jakieś parsery plików, gdyż są reużywalne, pick upa możemy załadać do TCP dumpa, wire sharka, snorta, surikaty, do wszystkiego co chcemy, tak? Podobnie jak z JPEGami czy z jakimiś innymi formatami, no YAR nie załadujemy, tak, no z YAR jest słabo.
Zarządzanie korpusem, czyli to, czego wszystko zrzucamy na komputer, na serwery, one sobie dobrze z tym radzą. Deduplikacja, to jest taka masa po prostu takich samych test case'ów, no niestety, pomiędzy iteracjami, to jest po prostu koszt, koszt tego całego procesu, z tym trzeba się pogodzić, tak, minimalizujemy pod kątem code coverage, no to wiadomo, to co mówiłem wcześniej, usuwanie istotnych danych z pił w korpusie, to jest bardzo kosztowna obliczeniowa operacja, gdyż musimy za każdym razem wykonać program, sprawdzić czy zmiana naniesiona w danym momencie tak jakby zmieniła ścieżki wykonywania kodu, porównać to z poprzednią i wtedy tak obcinać te dane i tak po kolei po kolei, aż uda nam się poobcinać wszystko. Generalnie nie polecam, zrobiłem to kiedyś na korpusie 10 tysięcy plików, tylko już nie
pamiętam co to była za binarka, ale to bardzo długo trwało, więc nie, nie polecam tego, lepiej po prostu tak jakby core korpusu, tak znaleźć mniejsze pliki i wtedy jest dużo łatwiej. Utrzymywanie lub tworzenie słowników, to zaraz o tym powiem. No i oczywiście tak, automatyzacja, jeżeli coś możemy zwalić na serwery, zwalamy to na serwery. Tak generalnie, tak co możemy, automatyzujemy. Ja przynajmniej wychodzę z takiej zasady i do tej pory które tak, ona się całkiem sprawdza. Tak jak już wcześniej mówiłem, tak, ustalenie czy dany crash jest
Related talks
 43:55
43:55 29:57
29:57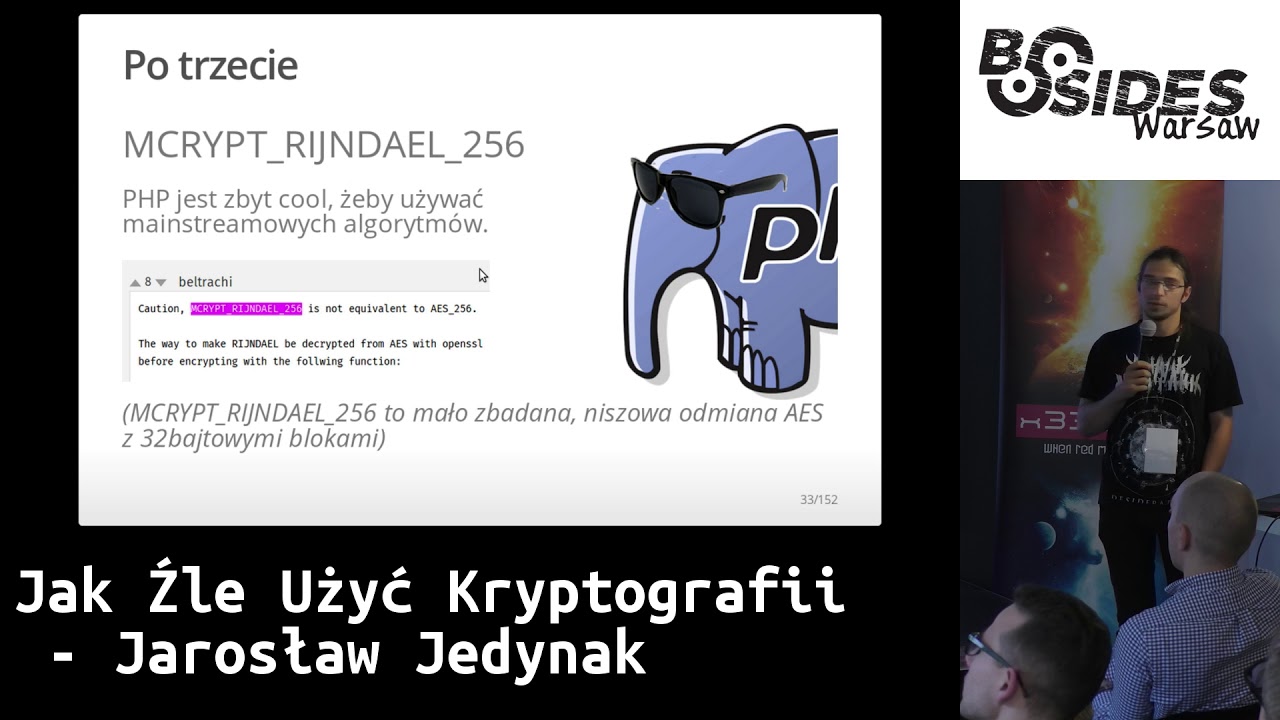 1:00:08
1:00:08 56:13
56:13 43:51
43:51 28:43
28:43