Vulnerability & Exploit Trends: A Deep Look Inside The Data

Show original YouTube description
Show transcript [en]
right and and more importantly why that also matters is one of the problems that we had in information security to date is it's a less mature field and some of the things that Michael has been dealing with in the past I'll talk a little bit about that but there's a lot of lessons to be learned uh in information security that we can uh glean from things like fraud analytics from things like physical security and others I think we're back on track for present display we make good we're going cool we're live I got so uh starting absolutely from scratch I did the thing that any grad student would do and I went through all these academic databases looking for
articles and being like so how do I help businesses prioritize vulnerabilities what are the trends what the statistics look like that was a pretty fruitless search that led me to find a whole bunch of things saying something like uh you know vulnerabilities are the rate of vulnerability disclosure is increasing or this type of Aer does this and the trend that I see in academic papers is one of two things either people are conceptualizing an attacker in a way that they think works so somebody saying like you know AP1 does these things let me look at some Trends and vulnerabilities from what I think the attacker does but that prescription is kind of AR priori and doesn't really
isn't really Based on data or people are talking about the rate of vulnerability disclosure which I take issue with for an entirely different reason that's a definitional is not an analysis of things you actually have to fix so the next place I went is infos blogs and I read a bunch of the stuff that people are talking about figured out that the place to go is threat reports it's vulnerability intelligence reports from the biggest vendors of course the problem with those is that those are specific to their customers their customer demographics vary like you can't nail down a population I wasn't sure what to do with that nor did I have the raw data itself so I went to Twitter
and started following a bunch of probably the people in this room to figure out what people are talking about and that led me to the kind of beginning of this talk and that's there are these definitions that we have for what a vulnerability is they come from miter and they come from osvdb n ranks them with a CVSs score and the next step that I did is I just went through the message boards of how these things were created and took a look at it and the picture was not so good um I wrote a blog post a couple months ago about data fundamentalism and the idea is that that data is created by humans and the way
that we the things that we record or the definitions that we create for this data is uh creation and these things have biases in them but we often think that because we have you know this percentage increase that's a fact of the know World here are the problems with that the first problem is that the vulnerability data that we have today is created by an organization that has limited resources and so in order to push out all the VES that come to them they do a few things they choose the things that are easiest to push out because a five chain vulnerability that uses you know eight cves it's going to take a lot of time
and it's a lot easier to release 10 that take 10 seconds to write it up or 10 minutes to write up they prioritize vulnerabilities based on what they think matters so some of these things actually do matter you know Microsoft ones always make it into the nvd definitions some of these things are things you would like to see but don't see so maybe you're using a software that's not in the priority list and so you don't get a lot the vulnerabilities that are submitted exist but you know miter NBD might not rank them and the next problem that I found and you guys should go see the Jericho and Sushi dude talk at black hat
and also uh lucot who's a guy from Italy who does a lot of this type of analysis is that vulnerability statistics and the ways that we conceptualize Trends generally are done from the definitional level and I think this is the biggest problem that I found in information security is that people take take these definitions to be the same as instances of the actual vulnerabilities and there's a big gap between the two so if you look at the English dictionary you would think that people don't use the word [ __ ] a lot because it only comes up once however it's all over the place in actually usage and that's actually the the main flaw and what we're going to
try to address today it's that we're going to look at the usage of vulnerabilities or the occurrences of them rather than their particular definitions and the type of analysis that we do has been done before uh lucad has done this and that that image is actually from his talk and he looks at nvd he looks at the definitions and he tries to figure out you know what can you say by looking at um highly ranked CVSs definitions and like the Sim attack threat reports so 87% of the things being attacked are high scored but so is like half of MVD and that doesn't really tell you much if you're looking at the High scor things and try
to remediate them um that analysis is all good and fine I think it's a lot better done when you look at actual vulnerabilities rather than definitions so this is a few examples of the things that I found that are wrong and they come from you know the highest of sources vulnerabilities have not declined 26% since 2006 I think that paper was in 2010 uh the rate of disclosure might have declined and the rate of disclosure of definitions might have declined but people are just as insecure as they were back then and you know know the total number of vulnerabilities is a really misleading statement people don't actually have those numbers the total number of vulnerabilities is something that we can
one day hope to see one% of so we have some percent of that and that's how we're going to structure the rest of this talk all these things that are definitional don't really matter what matters is actual vulnerabilities on actual systems and of course you know the definitions to Define them should be there but they're not what matters were statistics so the framework that I talked about earlier comes out of a few places I did a bunch of work in Game Theory and when I started thinking about Security First I thought of San Francisco bicycle thieves and I thought about counterterrorism these things are the attacker doesn't really have much cost it's really hard to catch them if
there's a false positive or there's a false negative that doesn't really matter to the attacker there's a wide array of targets and it's pretty profitable seems to be an analogous concept so I took a look at the way that people do this right now and these fields are really mature you know like bike theft people are pretty good at not getting their bike stolen uh like the shim prevents 99% of terrorist attacks that are being planned what do they do um and keep in mind this is just one model there are many models of you know a game theoretic attacker Defender strategy this is the one we'll use and many other ones can be used I think this
one's useful so they are threat actors and we all know about that you know there's the script Kitty there's at1 there's different types of them but what matters is that you constantly update your definitions of these things as a result of the other ones then there are possible strategies the bike thieves they can go after the $5,000 bikes or they can steal a bunch of the ones that aren't locked up the cost hundred bucks this is the vulnerability definition that people do analysis on and that's wrong there's a lot of other steps to it you take the definitions and you look at actual ongoing attacks so in this casino those definitions of vulnerabilities would be something like you know the
people on our Blacklist of previously done this we need to prevent against it but then we take a look at what's actually happening and I skip the head too far but that's okay I take a look at what's actually happening and they have cameras monitoring in a real time they're trying to figure out whether something's happening so we have you know seam networks that try to do that but it's not correlated to those definitions then once you have that once you have your thread actors your definitions and the actual attacks that are happening you want to take a look at the system topology and by this I don't mean whether you know the this laptop is
connected to this network what I mean rather is which vulnerabilities are on which assets not the definitions of those vulnerabilities that's something that we have a lot of experience with at RIS and you want to update those actors those possible tactical strategies and those actual attacks based on where you fail so everybody looks at the DB you know like once a year or twice a year and decides that these are the things that matter but in reality you want to be looking at successful breaches that are happening in real time much like you don't want to be looking at the definitions of you know like SQL injection is 8% of known breaches you want to be looking at in the past week
we've seen you know 20 SQL injections and we have a couple of them on our assets so in counter terrorism they do this pretty well I think that analogy is really clear they've been doing it for about 50 years they have things that fit into these categories pretty well and they have these processes that update each other uh most importantly what they have is they have successful attacks and that's how they've learned most of their things they also unlike us have close calls and near misses so that allows them to know kind of the in between probabilities so if an attack is a near miss you know that that vulnerability is going to be targeted and you know people haven't
been breached on it but maybe you you'll be the first one to be breached on it because it's been a near Miss for the past half a year and it's gotten more advanced um the most simple analogy of this framework is in sports people do scouting reports to figure out opposing teams players they look at game tape to realize possible strategies you know can that kid actually dunk or not then they look at gameplay and they figure out like oh crap that little kid on the bench is really good and he can shoot a three like none other and based on that they update their roster they think like you know we should defending as these
people you need to be running faster you should jump higher so train your jumping because you can't defend that get that's duning and the point that I want to drive home here is that sports teams learn a lot from losing you hear like motivational speeches in every movie about them doing this they learn from losing because this allows them to update what other teams can do against them and how they're performing it's a measure of your performance and it's also a measure of those threat actors and potential actions um what's missing from the slide is actually that they also learn a lot from near misses so when the Bulls lose to the Miami Heat by
two or win against the Miami Heat by two points that's not a win that's a near miss and what that means is that you need to update your strategies in order to make that point differential higher so that you're actually safe and this is something we fail to do in Security office so what does infosec actually look like and um this is you know all these things exist in security it's just that they're pretty disperate people scan their assets they want to scan more assets to understand where the vulnerabilities are and then we have a bunch of people who are doing some good work on breach reporting some people who are doing good work on thread Intel some
people who are looking at specific parts of malware and realizing what it does but what we really want to know is how that Mail work out in there in the first place what's the vulnerability attack path that it took or from breaches how did those breaches occur what cve were your breached time because then that allows you to prioritize the things that actually matter instead of fixing all of your vulnerabilities so I guess s to said this anyways the point to drive home from this one is that vulnerability definitions are the possible strategies that are being taken they're by no means the successful attacks and the gap between that is a couple of levels of
analysis that are missing and what's going to fix that Gap is looking at actual distributions of actual vulnerabilities the things that you want to be remediating are not necessarily all of the vulnerability definitions they're rather the things that are being attacked to reduce your chance of being breached and so all this data exists it's just that people aren't aggregating it together and I'm not going to pretend like we can do that either here's what we have we have a lot of assets with a lot of vulnerabilities that we scan from our clients and we have data about successful attacks and what CD is raining PR so the rest of this talk we're about to get to the meat because
the framework is over we'll talk about what the status quo looks like based on those two parts of this framework that we have and why the status quo is pretty shitty and how we think you can fix it um you know for future work all those things that are listed on the is the right hand side left hand side of that slide are things that should be integrated into it here's what we have we have 23 million vulnerabilities sitting across 1 million assets around 9 a half thousand companies and 22 different scanners feeding this data and static scanners Dynamic scanners and map whatever uh and this is the data set that we'll use to do the kind of statistical analysis that
people are using a data set of 55,000 vulnerability definitions I think it shows that the things that we glean from definitions are often very Rong so what can we tell you about the status quo things that you can say from live data that you can't say from definitional data is the performance of your team or those scanners so for scanner performance we can tell you about duplication how often though two scanners find the same thing duplication is problematic because if you can't dup the thing you're wasting resources and expensive and maybe you bought a scanner that you shouldn't have we can talk about vulnerability density so that you know you know maybe you're not scanning all
your assets but you know about you can estimate what it looks like on the rest of your assets and we can talk about how people are performing because we know when they close a vulnerability what they don't so about 87% of vulnerabilities are found just by one scanner keep in mind that this might be because our clients only have one scanner but 12% are found by more than one scanner and this is kind of problematic because if those aren't D duplicated people could be fixing a vulnerability that's already fixed you could also think that you are in a bigger position of risk than you actually are you could be prioritizing assets that are actually pretty safe so
to to use this data in a meaningful way um this is so the counts on the left hand side or how many are duplicated out of the 23 million um to use this data in a meaningful way I'll have tell you what somebody who knows about security would do with it so that's that's a lot to take in but uh ultimately uh the duplication thing does matter and what we're looking at from a duplication standpoint and what we've looked at across our data set um actually that 12 a half% is a little bit misleading because we're aggregating across our scanner coverage uh different classes of scanners right you could have a network scanner you could have a
dynamic application Scanner a static analysis tool all these different things obviously a static analysis uh tool and a network security scanner are never going to find the same vulnerability or almost never find the same vulnerability um so that 12 if if you just broke it down by class and we looked at just Network scanners that 12 1.2% is actually even higher but why does that matter so taking some some lessons back from uh my previous Employments um what we are looking at is about scanner coverage and not asset scanner coverage that's a different problem and not data that we have to readily available to analyze but more of vulnerability coverage as Michael was talking about ear
he talked a lot about the problems of vulnerability definitions right everybody's basing their decisions based on what makes it into a cve database what makes it into the national vulnerability database but that isn't encompassing of all vulnerabilities and you want to be able to measure false positives false negatives that sort of thing and you can do that by having these multiple scanners but what we did basically determine by looking at this data what I see when I'm looking at this chart is essentially you get to the the point where the the lack of uh diminishes greatly after two scanners so if you've got two network security scanners maybe one's external maybe one's internal maybe they're both in the
same location whatever you're going to get good coverage in terms of finding uh at least vulnerability definitions or or being able to detect those uh but once you get into three four of the same type of class it becomes much more expense than it's really worth while but another piece to consider here is vulnerability density so Michael pulled these numbers for us and I took a look at these and the first thing that I I looked at over on the right hand side I said none of this is a surprise this is actually you know uh very common and something that I've seen all the time but essentially the top three where the greatest amount of vulnerability density
exists meaning number of vulnerabilities on a given asset is much higher than the bottom two and the top three really Encompass the network and INF uh infrastructure scanners right versus the file based stuff which is all static analysis tools your fortifies fa codes um and then URL which is your Dynamic application scanners it goes way down the list but there are some things here uh that are really interesting from a remediation standpoint first of all if you can do duplication or D duplication between a file and a URL meaning if I can take a static analysis tool and I can take Dynamic application Scanner and I can correlate some of those results together uh you tend to get a lot more
false positives with the static analysis tools you tend to get a lot more false negatives in general with the dynamic application Scanner between combining the two of those together sometimes you can weed out false positives and false negatives the other thing is more about remediation so maybe my vulnerability density is much much greater when it comes to the infrastructure side of the house but remediation tends to also be much easier yeah so that was kind of what we can gleam about the status quo of the networks that we have scanned and the data that we have what's more interesting for us to figure out is how are people doing at remediation and taking a look at just CVSs score
breakdowns you can see the bottom line is average time to close by severity the trend is pretty sharply down doesn't look so sharp because the scale is off but as the CVSs score increases that's where people are quicker to immediate it which to me indicates that people are using CVSs as a guide for mediation also what's interesting about that is that the gap between how fast people are remediating things and the oldest vulnerabilities that exist in their environments is pretty huge that's days on the left hand side question in the back yeah I was just curious if the data you have it all correlates with thewless half ofil uh yes in some ways it very much
does but even more so I would say and and Michael will show this later these tend to line up almost directly with CVSs scoring right so that's your slide let's take it now you're bet so when you when you take a look at the data and the the two uh charts that Michael was showing earlier one is essentially the oldest vulnerabilities within your system the other is more on the average rate of closure in terms of number of days and then the bottom is the distribution essentially of taking the national vulnerability database and taking all of their cbss scores and seeing where they fall and the curve on the bottom and the curve on the very top are almost
identical meaning people are very much making their decisions uh around remediation based on CVSs now that is going to be problematic which Michael will talk about in a minute as to why but it turns out to not be a surprised so I follow people in this room on Twitter and you know I I realized that most of us canash on cbss all we like and it's not a good guide for mediation but what's more interesting to me is how can we actually prove that CVSs isn't working and so that's why we talked about this entire framework in the first place this is kind of the meat of the thing and the stuff that really matters
we have a million and a half vulnerabilities related to live breaches recorded over the past two months this comes from the open threat exchange and first let's talk about what's missing here because I'm going to lay down some Revelations but what's missing here are two things the first is the impact of those breaches we don't know whether you know somebody breached a vulnerability and nothing happened as a result so that probably occurs in most of these but it's still important to know that you've been breached on it because chains occur because being breached in the first place is what you're trying to remediate the second thing that's missing is the intermediary step um we don't know you
know this is a million and a half breaches but if that's a million and a have breaches out of 2 million attacks this changes the probabilities of you being breached out of vulnerability if it's out of 50 million attacks that changes it as well but you know we don't have the data so let's not look at it here's the best analogy to what the rest of the stock will be like think of it as a preflop for a Texas holding hand we know that you got two cards we know the probability of you winning with those two cards and that's about it we don't know what's going to happen on the turn we don't know how other players will
react but we know that in order to win you need some good cards and we know what those cards look like and and just uh to add to that these are this is breach data in terms of successful exploits we what we uh another caveat that we don't know is we don't know impact right uh so we don't know that this was a chain of one of five vulnerabilities of which the first one was successfully exploited and the last four were not we don't know if this was something that ultimately ended up in a very large scale reach or it was you know dropping mware on a lunch server we have no concept of that whatsoever right
um let's actually get it all off our chests the other thing that you need to keep in mind is that these breaches come from a data set that is disparate from the vulnerability data set so it's not like these are breaches that happen to our customers these are just breaches happening and the population sizes of those the population sets are just different so you know you can make many arguments about like but no this population is different from this one and your correlation doesn't matter uh to that I say whatever this is all the data we have and you know when you reaching the tens of millions you might as well take a look at it because it
probably means so let's talk about CVSs and Remediation and why it actually sucks if you look at the oldest breach vulnerability by severity and you take a look at CVSs the trend looks pretty sweet right like you know the nines and tens are less because people are remediating those but if you look at the oldest breached vulnerability by CVSs the graph is just crazy it makes no sense right like the fours and fives are getting breached and those things are like 3 years old and you probably aren't paying any attention to them anymore but you should be because those fours and fives are how people are getting into your system systems there's like a huge
dip around six even though there's a whole lot of sixes in NBD and like yeah there are some nine and 10 okay yeah the things that really matter they can flag an nvd so what this tells you is like the way that we conceptualize the whole set of vulnerabilities that we have and rank them by cdss only matters in so much as breaches are occurring in it and the you know the linear progression from 1 to 10 of CVSs just does not exist when you look at prics what does exist is that the counts of the nine and the 10 are really high and that's probably because I don't know I don't know much about you know how you actually exploit
something but I'm guessing that the exploits that people are firing off on their bot Nets are the ones that are 9 and 10 CVSs things and that's actually why they're getting scored nine and T because somebody saw it in the wild or it's not a proof of concept it's an actual exploit that said there are still like you know 25,000 fours that were breached on that we should care about so the rest of this talk I'm going to talk about probabilities and they don't mean anything when you have two different populations but in terms of rank ordering things you can use it as kind of a guide so CVSs how good is it if you
look at a random vulnerability just throw a dart at all the vulnerabilities in your network and by that I mean throw a dart at 23 million vulnerabilities that we're looking at the probability that one of those has had a breach occur in the past two months is 1.98% so I apologize for the Precision the Precision matters in terms of just comparing it to other things it actually needs so say 2% that's if you were just trying to patch everything to remediate everything and you felt really good about getting 10 blls solved in the past week the chance that you're actually preventing a breach for each one of those is 2% but you know we use CVSs we you know
know which ones are important here's what it looks like if you only look at the population sets of CVSs break if you're looking at CVSs 10 you're doing okay uh 3.48% chance so about twice as good as throwing a dart at a board if you're looking at CVSs 9 and this is misleading because I did a group buy and round it off it's actually you know at CVSs 9 and a half you're doing better than random at CVSs 9 no longer and if you look lower using CVSs as a guide is worse than just randomly picking vulner abilities to remediate so it's really sweet to bash on CVSs and now we actually have some proof that it
doesn't work uh you know it should really just be a tenor and nothing at this point but what's more interesting is the alternative to that and what strategies actually work and with that let's do this so to take a step back um there was a smart guy I know called named Alex huton may or may not be sitting in the back of the room right now uh we coined a term called the security Mendoza Line uh several years back at this point but essentially uh and I will quote Alex rather than since he is in the room wouldn't it be nice if we had something that helped us divide who consider who we considered an amateur and who we
considered a professional when it comes to security so for those of you not familiar with Mario mza baseball player Pirates 1970s who really uh played actually played for a number of different teams in the majors for a number of different years and the amazing thing about him is that he sucked at batting uh and played in the major leags for years uh and that is because of his uh remarkable Fielding although some the betas range but um and he was able to do that while batting a lifetime average of around 200 or two hits out of every 10 atts uh which sucks for someone who's at that level um and they later ended up coting that the meno
line meaning if you are hitting below the meno line if you hitting below 200 there's a good chance you're going to get sent down to the miners where the quote andquot amateurs play even though they're actually professionals that can as well um so the security Mendoza Line was where is this and and Alex feel free to correct me since you're actually in the room here uh but where is that line in security where can we state that we are professionals versus amateurs what what is the Baseline that we need to be doing as Security Professionals later Josh Corman comes along and expands on that a bit in something called HD Mo's law uh which I'm not sure who's familiar with HD
Moore's Law obviously probably everyone in the room is familiar with Moore's Law I'm also going to assume everybody in the room is probably knows who HD Moore is uh co-founder of metas fls uh but Essen ially it's became this line of uh the the rate I'll quote him as well casual attacker prowess grows at the rate of metlo so metlo is a really great tool and a lot of really good people use Metasploit and a lot of very untalented people can also use Metasploit because it's so damn easy to use and there's these Metasploit modules in here which are just exploit modules which essentially mean that you can point and shoot and attack and exploit a
particular vulnerability it's it's become easy it's become table Stakes really for us as Security Professionals of that line that we need to protect against are do we have vulnerabilities that are in the metlo framework uh the chances are of an organization of any size at all the answer is yes and it's actually while this is a very basic premise that you need to be able to protect against your lowest attacker it's much much harder to do in the real world so think about that policy for remediation instead of CVSs as a policy it tells you that there are certain types of attacks that you should be remediating and it fits really nicely into the framework that we started this
with it tells you what types of attackers you have which you should be protecting against and the Baseline is script kitties it also tells you what types of attacks they actually undertake so what CVS are in exp it tells you what's happening out there you know which ones are being breached be a metlo and that allows you to do prioritization so this one is kind of the money slide and it tells you how much better a policy of remediating metas sploits and exploits does than a CVSs 10 policy which is the only thing that does better than random in cbss in the first place so if you're looking at exploit DB and you take a look at all
the exploits in there and you add random pick a vulnerability that's an exploit DB and you remediate that one the chances are that with I mean the chance is 12% about that you're fixing something that somebody has been breached on in the past two months if you take a look at metas that chance goes up to 25% is that right yeah 25 and if you look at the intersection of the two which ends up being uh 697 cve identifiers and you pick one of those at random that's on your network you have a about a 30% chance of fixing something that somebody's been breached on that is 10 times better than the best that CVSs
can do and that is about 15 times better than picking one at random so the next time that somebody tells you you need to fix a vulnerability you need to decide which one if you're picking one at random it's 2% if you're picking a CVSs 10 it's like 3% but if you just look around metas and see that you have one 30% chance you'll be breached on it in the next couple months that's it and with that we'll take questions
going once um I have T-shirts if anybody wants to ask a really good question my course the guy in the back of the room why not just patch everything who here in this room patches everything um well for one great great question so than you David I actually looked at that data um and we decided not to show it today mostly because our patch data like the number of patches that are out there isn't so good but the thing about patching is that people release patches for things that people aren't exploiting so if you have the Cho you know patching is really easy but if you have the choice of patching 10 vulnerabilities that no one's exploiting
or spending the money on a code rewrite that'll fix a metas sploit b probably better off fixing the metlo right and commercially releas patches patch released by someone else in your organization it goes far beyond that though you start patching things especially if you're a developer you start breaking things you can't start push patches out to a bunch of boxes all the applications that run on top of it process you don't patch Everything at Once because otherwise you don't know which it it yeah and it's not only that but I mean to Michael's point that that there's only a certain subset of that data that is patchable in the first place um so regardless of how much you
patch and maybe you patch everything if if you looked at the the money slide of Michaels in terms of what's in exploit B plus the intersection of the metas framework uh a large chunk of that and we don't have the the data unfortunately here to display but a large chunk of that is not patchable or is something else right so it's it's more than just patching although that said there's there's so few organizations that I've met that actually are patching at a previous organization that I worked at we took the attitude that weally push every patch from Microsoft and sun and IBM our servers y pump them out because we do a test install BL screen was good
to go rather break the network in a way we understood wait for something break I I I don't disagree with that but but and and and I so when you say patch everything though I also see yeah we patch everything and they come back and they we patch all of our red hat boxes and we patch all of our Microsoft stuff but what about the 35 different apps that you've deployed on all the desktops and everything else and that's where it falls over and that's also expensive right so this type of analysis lets you make your next decision of the next you fix it doesn't let you make a policy decision about like where you spend your money
nonstop so even given that say you can't patch everything because you've got only 10 bucks in your pocket the thing that you should patch should have a MPL flash yep also we didn't include that trending data but Flash and Java is is definitely part of that that's all um although it's not easy to uh to use in bulk um Brian and I have been working with to uh kind of cross reference exploit BB and medlo modules the CDE and if you're looking for a way to prioritize um you know you can you can go in there either by exploit or vulnerability and you'll see all the cross reference of how all those fit together and unfortunately like I said
it's not set up for doing the bulk you can't take some scanner output run through there and help prioritize but if you want to do the research and trying to make a decision on to do like you're suggesting here that web page that's rapid to kind of help you it does contain that data on which ones are intersecting and all that yeahor so you you for Rapid you have that people correct I mean the web page we have you can do a fulltech search by uh an exploit name Jaa it'll dump out all the Java exploits U all the vulnerabilities the exploits that might take care of those uh and you can get that information there um you know it's
updated once a day uh every Med Bo build every nextos Bill holds the cve and the OS not OS exploit DV every day and it's updated every morning so so so and an important Point here um is yes this this is great and the fact that it's way better than this but this is still only less than 30% right um so that means we are still underwater and you know running on a treadmill that's going much faster than us uh we didn't talk too much about the uh the rate of discovery versus the rate of close but it's not a pretty picture but also the attack data that we've analyzed over the last two months um there's there's shifts and
Trends in that as well right so being in met exploit plus exploit DB is good uh it's better if I can tell you know some of the trends that are coming out of the actual real world attack traffic as well so that I can start to say things like well yes that was important but that was really getting hit on a lot last year and this month it seems to be this or this week it seems to be this so here's an example like you got a flash vulnerability that's an exploit and met exploit and you know that a lot of people are deploying flash so chances are there's 10 bot that getting it that's the kind of stuff that makes you
be 100% successful in predicting breaches um before we continue though one thing you need to realize is that these are success probabilities right so if you take that policy on we also need to think about failure probabilities so if you're patching a metas what's the chance that or you know you're fixing a metp vulnerability what's the chance that you're just doing nothing and fixing something that isn't actually uh being breached on so those kind of sensitivities analysis is something that needs to be done as well to realize if you take on that policy how how good is it to be you know 30% more successful but again to that I say if you're 15 times better than cdss and whatever just
do it have you uh broken this data out at all by application type or Os or device I mean if I'm not running PHP does that all a sudden decrease this down to almost nothing so we have the data it's it care about PHP the first though so yeah so to that point though he's he's kind of being half sarcastic but when we talked about the vulnerability definitions at the very beginning that's part of the problem right so when you look at everything that's in National vulnerability database you're you suffer from selection bias there's only so many people at miter that can enter this data in so they're going to say okay I'm going to focus on the Microsoft and the
things like that and oh this is PHP I'm throwing it out doesn't mean it doesn't exist as a vulnerability they don't have the resources to publish it into the national vulnerability database doesn't mean it's not real on that something really interesting to watch is as of the past two weeks I've been monitoring the miter feeds and a lot of them are just exploding with PHP vulnerabilities which means that either they have more resources or the prioritization is changing but if you think about it the types of vulnerabilities changing in the definitions if you look at some of those reports that I call [ __ ] they'll start to change and maybe the vulnerabilities are actually increasing
but this probably won't change did you look at the same data um so that you're looking at the time of release uh public release vulnerability so the crafts a while back were oldest vulnerability by CVSs severity right you remember the the really big gap between the two curves that was the oldest vulnerability by release and then the next slide where I was like CVSs is [ __ ] the crazy graph that goes all over the place that's the age of breached vulnerabilities by Disclosure C and it's all over the place because you know there's po nuts that are hitting CV 1999 stuff all the time I was just I was speaking specifically of this the metas
data yeah metpy and the breakdown the CV exploit DB so no I haven't done that but off the top of my head I can tell you that that number of exploit in metlo DB is something around 200,000 so I'm guessing it very closely mirrors the graph of just oldest because I mean all of them must have gotten hit of 200 breaches have 200,000 breaches have me think through this data from the product vendor standpoint of prioritizing patching like actually releasing patches to vulnerabilities um how this data would would maybe skew our prioritization versus just using cbss and the temporal that's a very good question um I think and I will say more to this because he knows security to me from a
data standpoint um I think it means that if your goal as a vendor to protect against the things that are being actually breached uh tier one priority is things that have exploits and not just things that are an exploit DB because things in exploit DB are often like proof of concept things that are like I heard about this on Twitter so like people are going to hack this what's more interesting is there modules exploiting it same thing as the Mendoza Line for remediating vulnerabilities there should be a Mendoza Line for publishing patches so everything that has a meta SPID should also get fixed right and then in terms of prior other things I think that's a question of
everybody in the security industry getting more or less real- time breach data and more or less real time trending data or a velocity data for what people are using because that's a better meter to me of how important something is than calling it a 10 now I couldn't possibly ask what about other exploit tools um so we so there's other things that we've started to look at but it's not yet in this data set that we should be looking at blackhead exploit kids definitely uh we're going to start doing that it's hard to do cuz those people will hack you but we'll get chice t with all this data have you guys ever considered putting a percentage next to
each vulnerability of the likelihood of attack something that makes it super clear definitely considered it days you don't get a t-shirt for that I definitely considered it two days ago when I pulled word here but for those who live in AED we are told we have to four and above yeah which which by the way through the if you look the distribution is pretty much almost every
cve get that a little better yeah we H we haven't yet we're we're just now starting to publish some of this data and dig into it but uh we more than happy to talk Mr Russo and others absolutely PCI is essentially telling you just like fix everything from our perspective just like your Auditors Cil never going to change right what happens when what happens they say no no it's cool just fix this and somebody gets
exploited sorry not to make this PCI discussion but you should be able to talk to your bank to qsa about about your risk management and your vulnerability patch management us an example so you should be able to do something like this and still satisfy oh sure but at the end of the day right at the end of day at the end of day analyst that you're going to have to pay for so that they can prove that you not comp who's been breached and actually right um you're going to get screwed out of the way you can do this maybe this will take some workload it'll be less own for you but it's not like this
is well neither is any other PCI you said you're going to become we're getting the hook um so I got to cut us off but if there are more questions or you want to discuss anything we'll just be right out in the hallway uh Pat the guy over there standing there also has t-shirt if you want those as well but thank you very [Applause] much
Related talks
 22:29
22:29 24:01
24:01 40:29
40:29 25:51
25:51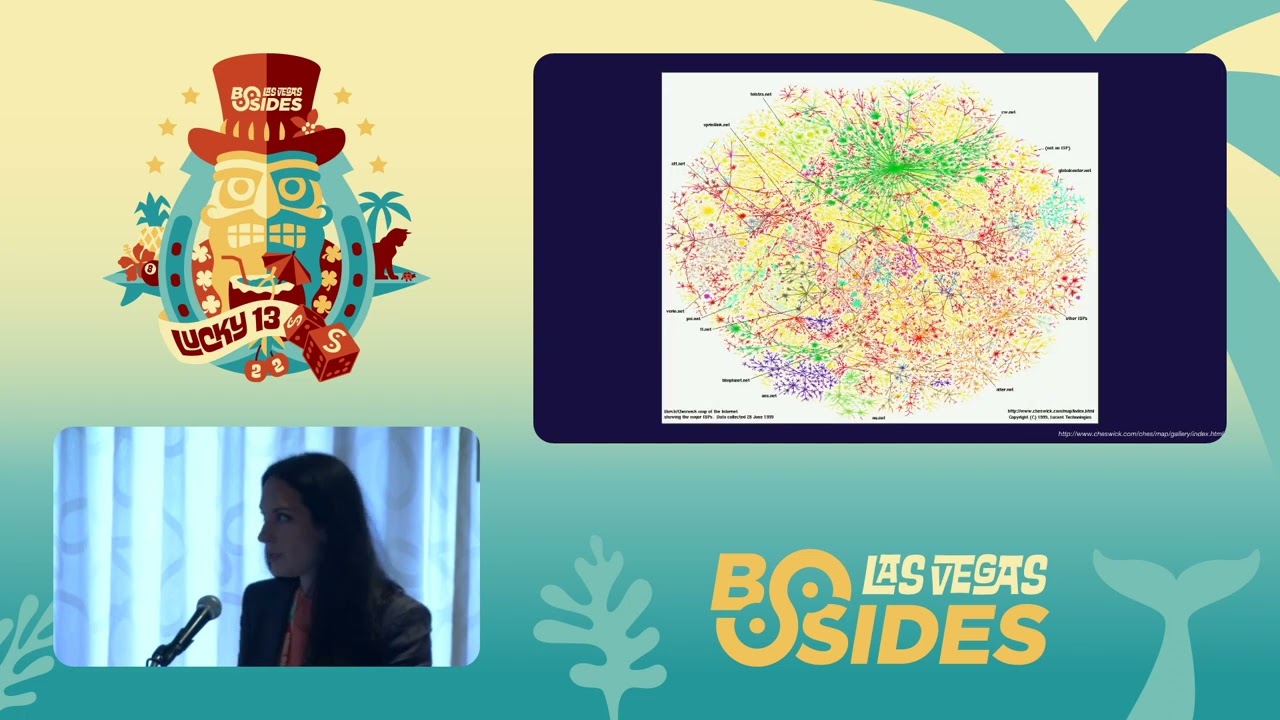 50:09
50:09 23:26
23:26