GT - Looking For the Perfect Signature: An Automatic YARA Rules Generation Algorithm in the AI-Era
Show transcript [en]
well good afternoon to heroin thanks a lot for having me here it's a very great pleasure to be here so my name is Alomar Charlie I'm from Italy and I'm a PhD student at Polytechnic University of Turin and I'm also a security researcher had a specific which is less pain based company and I study machine learning semi-supervised modeling and at least physical work on the Kudus project working on new algorithms to catch malware mostly Android malware so today we will talk about the signature generation problem the algorithm that I have developed and the tool that I have developed which is called yaojin and then I will show you a fast demo a quick demo and some results so let's start
talking about the signature generation problem and what is a model signature it's a just unique pattern that identifies a set of malicious samples and the big issue between B with the malware signatures is that has malware evolves new signatures needs to be generated frequently and there are two types of Metal Mulisha type of signatures they are syntactic signatures and semantic signatures the syntactic signatures are based on text inks and binary sequences that are extracted from the binary inside semantic signatures provide an abstraction of the of the program behavior and from the industry point of view the de facto standard type of signatures that are used are the syntactic types is the syntactic type of signature and it's also where most of
the research brought from industry and academia focus on instead of the in this talk we talk about semantic signatures because we believe that could lead this way back to detection system and this today's talk is a focus on Android malware and yarra rule rules but it's not to be seen as a limitation because it's the approach is very generic and can be applied to other operating systems and languages too and just to not go in in the siq we cannot it's not a machine learning classifier we're not talking about these I love machine learning I study heat but we're not talking about machine learning today so why do we need an algorithm to automatically generate
signature well the first reason is that we want to reduce the malware exposure time because we want to detect a sample Emily to sample as soon as possible then we want to automate a very repetitive task and keep in mind that from that today every day accompany antivirus companies received from 20,000 to 50,000 new Android applications which is a very large number so analysis is not an option then we have a goal which is 1% recall a very high precision which means we want to both lower the false negative and false positives and finally we want to save a lot of resources and both point in time and money because generating signatory is quite expensive
and very time-consuming so today we will talk about the era the era is a pattern matching languages used to write model signatures and it has been defined by Victor Alvarez his creator as Yara is to file what snort is to network traffic one of the main advantages we are is that it's fast and it is the de facto standard LED type of languages that is used by the industry the antivirus industry to write symmetry so it's very widespread and so the symmetry that you can write Yara hard most of the syntactic types so you can write signature using textual strings and binary in sequences although Yara also supports the semantic signatures if custom models are used and this is an
example of year-over-year rule in Yahoo there are three main sections and the most important one are the strings and the condition in the strings you can place the binary sequences and textual strings inside the condition is where the binary logic the logic of the rule is placed the angle and also some semantic attributes today we will focus on the condition section now let's switch to the algorithm well the algorithm that I have developed is placed within a pipeline that is very common to many antivirus antivirus companies in this pipeline the first step is the IP k submission every day the antivirus company receives thousands of new applications those applications are then clustered using several and
supervised techniques i will not focus my talk on those techniques but there are many it's a very well known problem rough from academia and the industry there are tons of different sources and solutions so let's say that someone at some point says ok it's a Marvel family and we want to generate a signature for them so the input of the algorithm is such a Marvel family and we don't really care how such family has been found maybe manually maybe automatically and in order to automatically generate a signature you need to start some attributes so it's very important that an application is analyzed using static and dynamic approaches and in the end of the analysis there will be a bunch of
attributes that is feature extracted from the applications and each attribute is a Time Square in that Gregory that you can see on the screen an attribute can be a new handler he'll that that the application contact during the dynamic analysis or can be a permission and in turn filter everything else there are several software that can be used for example Android it's very common to use an and regard drug box and cuckoo which is very famous software frameworks and I would like to remark that it's very important that if this phaser is accurate because as many attributes as you can find as much as your rule will be better so if in order to have better a good quality rule we
need a very high quality analysis the idea behind the marvel signature generation process is very simple we have two samples those samples have a number of attributes and some of them are of the same type in the inbox of the samples for example there are some yellow and some green attributes and let's say that some of them are really in common so we can generate a signature just finding which attributes are in common although the real world scenario is much more complex there is no unique pattern within also within all the samples in the same malware family so it's it's very difficult to find a pattern and actually a single pattern doesn't exist so the goal of the signature generation
problem is to find the set the subset of attributes that cover the entire Marvel family and this problem if you think a little this problem is very simple - a very well known problem from the literature which is the set coverage problem and actually this is a variant the creating viral signature is a variant of the set coverage problem and unfortunately this problem is np-complete which means it's very very difficult to to solve it but for in our case either unequivocal commitment is enough to solve this this problem so we can actually find the the middle signature using such a greedy algorithm although one of the main issue in automatically generating a signature is not actually generating heat but it's
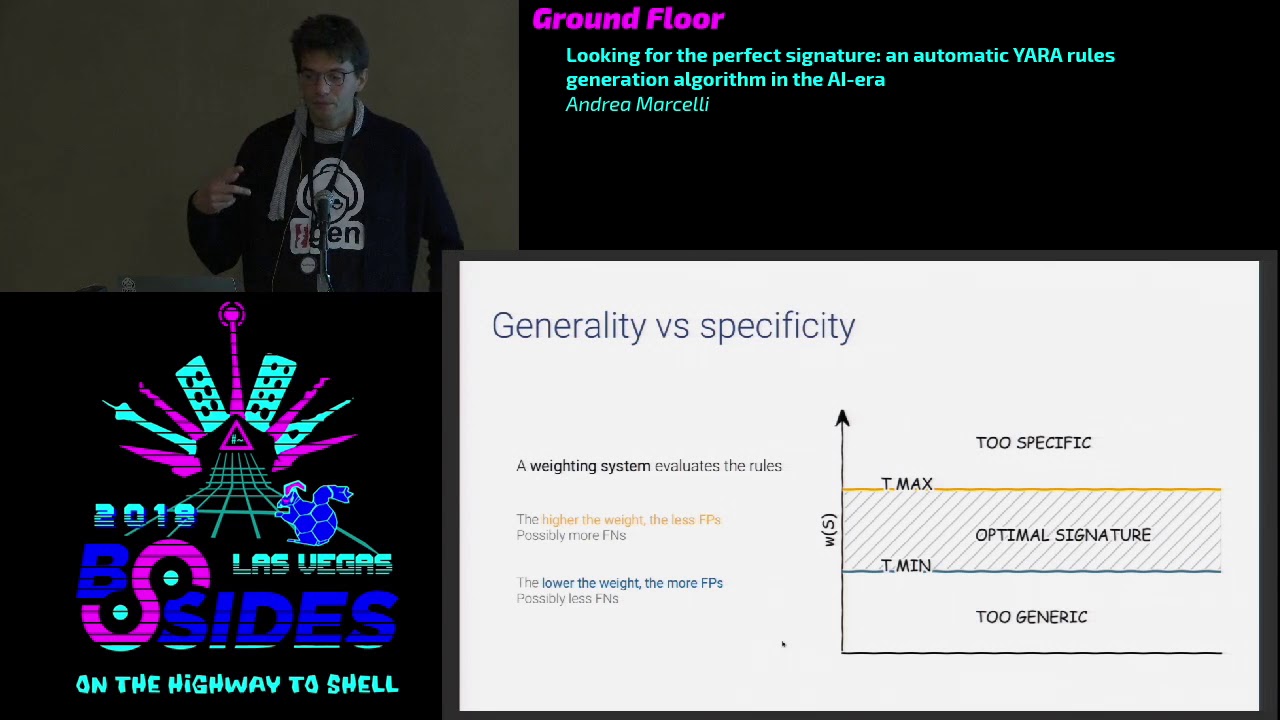
understanding if it's a high-quality signature so the problem is to understand evaluate the result of the automatic generation and so in order to better understand it I will introduce some formula the first one is the normal form so if we reduce its signature to a DNF which means disjunctive normal form it's much but it's much simpler to evaluate a rule in such normal form there are a few clauses which are on in our and each clause is made by the conjunction of literals and literally simply one of the hatch abuse that we have extracted before and so if we express acts in a scimitar into DN a-- f we can actually weighed the values each single clause so
if you can attribute way to each symbol flowers we can say that a signature as a weight which is the lowest among the weights of its clauses so we are able to understand to give a score to a signature starting from the scholar of the single clauses it is made of and this process sorry this waiting process isn't the base of the evaluation system because a rule that as a very as a high score will be too specific and too specific means will produce a lot of false negative because we not being able to generalize the detection to other malware samples and other hand centers with which has a very low weight will be too generic and will mean this means
that there will be a lot of false positive detections instead what we want is to generate a signature between two trap shots timmy 90 marks and we say that the signature that has a weight with between these two thresholds is an optimal signature so you can easily understand that in order to have a very effective waiting process so in order to be able to effectively effectively evaluate a rule we need to assign correctly those weights and that's the hard part and also the the way in which the attributes are weighed is very tight to the way in which teaming antimacassar set actually i want to the process to be automatically because this is a very
crucial part i don't want to this part relies on the knowledge of the expert analyst so one of the possible solution that we adopted the type is to start from existing yards there are a lot entire repositories of yards then if you start from then you can pass them you can process them and twist them to into the NRF then it becomes a simple linear problem I can't that can be solved through linear programming techniques like the simplex algorithm and in that we will have an assignment of weights for each attribute so that the 95% Oh existing rules that are satisfied and 95% of those rules that will have a weight that is between the
truth I shall team in and T max because why 95 because some rules that are so specific for a manual family that cannot be really used in the way team process so we will discard them okay actually when when we implemented such a procedure we were really able to generate signature but a new problems arise that is when we generate some signature there were two specific the way it was so high that actually they were not able to attack the other applications rather than the the the family that was used to create them so we need another face that reduce the number of attributes of a signature and we call this phase optimization phase actually the goal is it's quite simple
we need just to throw how some attributes and we have two different solution the basic optimizer and the heave optimizer well actually the basic optimizer is simple greedy approach to try out some some achieve it in a random way instead the team optimizer he's done is a much more complex optimizer that uses evolutionary algorithms and this is very useful because there are no written rules but some we our rule says some signature are much better than other and if you look at them you can really spot them actually so we try to encode so the knowledge of such a better rule set into some eristic s-- and then these risks are used within an evolutionary
algorithm to pick up the best optimization possible and since it's a broad optimization so it's not a very extreme optimization evolutionary algorithms can be applied and can found a solution in few minutes so the entire process that I have described have been implemented into a tool that is called Gaia john elgin is an acronym has stands for yet another we are a rule generator and the AIA in spanish means grandmother and that's why there is and i see a nice grandmother in the lab and the ideal the tool is that the input will be a set of reports or reports that are generated by the analysis process of the application of statically and dynamically and the
output is a set of your rules that will cover the malware family so if the model family is composed by samples which are all similar between each other there will be just one rule but if they are very different there will be multiple rules so actually the quality of the family is not very important what is important is the analysis it's the important part is just the analysis process so extract as many attributes as possible so what does the agent includes the agent includes two algorithms the breeding the basic read implementation and and an announced at grid implementation which is called plot which is the dynamically the algorithm and to optimizers the basic and eve optimizers and some
heuristics it includes a also your rule parser so that if you have your own site of your goals you can parse them you can assign the weights according to them and we also have an option to exclude false positive during the rule generation because there are some cases in which may be the generator rules will generate some false positive and even even if those are very rare are very annoying so you can actually say do not generator will that match those applications and everything has been written in Python 3 in order to understand better how engine works internally and why aside that the approach is general let's look at this picture so the input of your Jana is a
bunch of application and each application is represented as a set of tuples in Python so the actual input is a set of set of tuples and you can actually understand that it's very generated so it's not very specific on though it can be anything just a set of set of something and so there are two main flow the drive flow that simply generates one rule for each sample and input which is the most basic thing that can be done and the other flow instead covers the route generation so starting from this set of set of tuples a an optimal attribute subset that covers the entire family is generated and then there will be an optimization phase and
finally the last phase is the conversion into the specific language so what I want to hold mark is that if you change the first and the last phase to something has everything still continues to work you just need some way to evaluate the rule and do it and change the ristic because of course those are very specific to the platform because the eristic that works for android maybe will not work for windows and actually since I work on the Kudus project and kudos isn't you know an open device which means you can actually use it without paying anything if everything is open it's ready for CUDA so you can use the dual reports of kudos and use the
yard rules in kudos so the great news is that everything is freely available on github actually still private but I will make it public in a few minutes after the talk and now let's see short demo about how everything works so I will show through two case cases the first one is a very simple case where I just say use the claw algorithm to generate a rule set foreign all the all the samples that are within a directory and as you can see gr degeneration is actually immediate it's very fast it's a it's extremely fast and in this process the first thing that you can see is that the algorithm process the inputs that is
extracting attributes from from the report there is a simple part simple JSON parsing model and there is also some filtering so some attributes are filtered out because are very generic and then there are there is the quatrain and at the end the proton generate one rules with the 13 literals with 13 attributes now with this weight which cover all the samples and since we want also the optimized version the optimized version his printed the below so automatically you have both the raw version of the rule and the optimized version of the rule and the second use case instead exploiting it kudos so for example I used this search query in kudos I look for all the bank bought
applications from this June that have been received from this duel and all these applications are then you can just copy the URL from kudos and then the era generation process downloads these reports and generate a new rule and again we have the raw rule and the optimized version of the world in this case the number of literals start from 18 in the raw version and goes to 6 in the optimized version so as you can see it's extremely fast I didn't speed up anything the only thing that I did was to catch the the reaper's download so it's it's very useful and ready to be used now let's have a very brief is the result so I wanted to compare human
generated rules without multivariate rules and what I found out using 1.5 million I got a set of 1.5 million application is that there was a huge improvement in the detection ranging from the hight percent to the 131 percent with an average of 65 percent without even generating a false possibility result and we're very happy about it so few takeaways just to conclude we have an algorithm to automatically generate your rules and it works quite well much better than human generated ones but of course it's a baseline so there is still room for improvement then we have some several ways to include the expertise the expert knowledge into the algorithm using heuristics or using existing rules and it's very fast
because the time required to generate a rule for grabs is always less than 5 minutes of course it grows to up to 2030 even one hour if you given input to thousands and thousands of samples but it's it's normal and if you would have done it manually would have taken years so we are working actually on a new version of viadon which is called hydrogen piggy which actually targets windows binary I I just I can so I can just say that it works well so you will soon have some news and that's all thanks a lot for your attention and if you have any question please ask me [Applause]
Related talks
 51:51
51:51 32:48
32:48 33:48
33:48 54:33
54:33 31:06
31:06 20:51
20:51