An Open Source Malware Classifier and Dataset
Show original YouTube description
Show transcript [en]
all right cool we'll get started then uh so i'm here to talk about ember an open source malware classifier and data set all right my name's uh phil roth i'm a data scientist at endgame and in grad school they told me to always include a picture of me at the south pole in all of my talks so i sometimes do that uh yeah in grad school i worked on ice cube which is a neutrino detector at the south pole and it was there that i learned machine learning and now for the last five years i've kind of been applying it to the security industry here at endgame none of this would have been possible without my co-author hiram
hiram is awesome he's also the technical director of data science at in-game but mostly he's just awesome so so why amber why what am i doing here uh well open data sets push machine learning research forward uh you know machine learning has achieved great results in the last 10 years in like language translation uh optical character recognition uh you know detecting or identifying what's in images the objects that are in there and uh there's a lot of good reasons for that uh one of them is you know hardware has gotten a lot better data sets have gotten a lot bigger but i i'm saying that one of the main reasons they're getting better is the presence of uh
open source uh benchmark data sets in all of those fields so what i'm showing you here is a plot from ben hamner uh and it's showing 20 different uh open source data sets and the number of times each data set is cited in nips papers that's a leading machine learning conference in the field over time and so as you can see these benchmark data sets have always existed in the field but their use has really taken off in the last 10 years one example of a benchmark data set in an area other than security is mnist and this is a you know 70 000 images of just handwritten digits and they're split into a 60 000 training set and it's a 10 000
testing set so researchers can grab those 60 000 images train a model that recognizing that recognizes what digit is being written and then test uh that model on the test set and because all the researchers are using the same images the the same division then they can compare their performance apples to apples a leading researcher in the field calls mnist like the new unit test and what he's kind of saying is that the algorithms have kind of surpassed the mness's ability to measure how well that each one is doing because this data set's kind of smaller and you know we're doing really well at optical character recognition now but even even even though the algorithms
kind of move beyond this data set it's still useful as kind of a sanity check kind of like a benchmark test like oh the algorithm works here so we know it's at least doing something good uh another open source data set that was on that first plot is uh cfar and this is a again just a bunch of image images into a training and a testing set here though those images just have uh one of 10 different things like 10 different classes and so you know the the algorithm is supposed to recognize which class this image belongs to uh and then there's a version that has a hundred different classes so like i said these are very useful uh
to machine learning researchers in other fields uh and but there's a problem and that's that security kind of lacks these data sets and that's that's been something i've been saying since i've gotten here to the security industry maybe five years ago so it's not due to any malice on anyone's part there's a lot of good reasons why it's tough to release these data sets in security and that's because there's personally identifiable information in them i know you don't want to release those kind of things to the public and even if you try and anonymize these data sets there's been a lot of examples in the past where clever people can come up with attacks that kind of de-anonymize
data sets and kind of expose people to information they didn't think they were giving out to the public it's also tough to uh to release these because you don't want to communicate vulnerabilities to attackers so even if a company wanted to spur research forward in like detecting uh network intrusions they might want to open source all the their network traffic all their infrastructure and everything but that would just kind of show attackers exactly what they need like where to attack and what their vulnerabilities are so it would be really tough to release something like that uh and lastly uh intellectual property and this is especially important in the area that i'm going to be talking
about which is malware identification where you want to train on benign programs and malicious programs it's very tough to release those benign programs because i mean that's what companies are producing and that's where they make their money so despite those challenges there are still some data sets that exist in security for machine learning engineers to to practice on to to use uh and uh mike's gonzo here uh has a great resource for those that's called secrepo.com i can't uh i can't recommend this website highly enough it's great it's a kind of just lists out all bunch of different third parties who've released data sets like this in the field of security and not only that but he kind of he um
tracks his own logs and then releases those so not only is it like a resource for other people's data it also creates open data sets as it exists which is great um so here i'm going to go through a couple of the data sets that exist on that on that site and kind of by doing that show you different areas where machine learning can be applied to the security industry uh the first one here is domain generation algorithms so that's that's when an algorithm creates large number of domain names uh that can serve as rendezvous for command and control servers so you have a piece of malware and it just generates uh large numbers of domains in kind of
semi-random and unpredictable way and the malware author you know has that algorithm and is able to know when you know when a domain is going to come up and then they can register one of those large number of domains and then each of the pieces of that malware is going to go talk to that one domain and get instructions about what to do next so you can build detectors for this using machine learning uh and you would rely on these data sets the alexa top one million will give you a good set of benign known safe uh domains uh and then here they're listed there there's there's three more kind of resources for uh dga generated domain names
especially the last one's really good uh because johannes there he's reversed a bunch of these algorithms kind of shown what these algorithms do in code and then generates a couple examples for you to use so i'd highly recommend that last one so yeah another thing you can use machine learning for is kind of network intrusion detection that's kind of this is an unsupervised learning problem where it's tough to have labeled data so you're kind of just looking for anomalous network events and to me this turns into an alert ordering problem this one's very difficult i've seen a lot less like successful applications of machine learning in this area and it's kind of uh it's kind of tempting for people like
me who come in from a physics background to be like oh i'll just look for look for outliers um but it it gets to be a really difficult problem and there's a lot of failures over the years but there are data sets available they're very old um it's the newer newer like network traffic data sets don't really exist so now we get to static classification of malware and that's kind of that's what i've been working on the last three years and that's what i'll be talking about here and this is basically the antivirus problem with machine learning you have a windows executable file is it safe to run or is it malicious and uh there are data sets available but
they're pretty limited uh driven here uh it's not windows executable files it's android uh apks instead uh virus share is a great resource for researchers but it only provides malicious uh malware the microsoft malware challenge that happened about two or three years ago and what microsoft did was they they released malicious files from 10 different families and they posted them all on this data science competition website called kaggle.com um but not only was it like only malicious files but that the pe headers were stripped from those files so they weren't they weren't real files and and you couldn't really you couldn't use like real world uh techniques on them uh they were i think what they were going for was kind of
like next level things like you can use the information from the pe header but what else can you do to classify these malware families into whatever family they're in uh yeah but still that did spur research forward there are a lot of papers about that microsoft malware challenge data set uh so now i'm going to talk a little bit about static classification of malware and kind of give a little introduction into machine learning in general and how you would solve this problem with machine learning so you have a bunch of benign and malicious samples and you want to train a model uh the first thing you need to do is extract features from all of those
samples and you're gonna end up extracting maybe 2 000 3000 features or something but to simplify it you can think oh we're just extracting two of them and then we can just plot them on this graph and look exactly at them yeah so if those features were like file size and number of imports then you could place it on a plot and then kind of separate the two uh the red dots the malicious dots from the blue dots and yeah you want to predict new samples as they come in and the way you can do that is kind of by drawing a boundary and then seeing which side of the boundary the new sample is on is on so you can do that
with rules uh it's very easy to do that with rules but uh you know you get you end up getting some of the samples wrong it doesn't have the best performance so you can turn to machine learning or using a statistical model that's going to better describe kind of the boundary between the malicious and the benign and again this is happening in two two dimensions but you can imagine a much more complicated boundary in a much higher dimensional space so i think we hirement generated this plot using a support vector machine which is um it's expressly its purpose is to build a boundary between the two but there are many other options and so how can you decide which one's best
well i'd say benchmark data sets are for you so ember stands for endgame malware benchmark for research we hope it becomes known as mnist for malware and so a caveat i know uh ember i think is a good name i chose it because the letters uh line up every and it's great uh but i also chose it so i could say this joke over and over again so i hope you guys don't get tired of it because i'm not going to all right so what is ember ember is an open source collection of 1.1 million pe file hashes that were scanned sometime in 2017 by virustotal the data set includes metadata like the hash it also includes derived features a
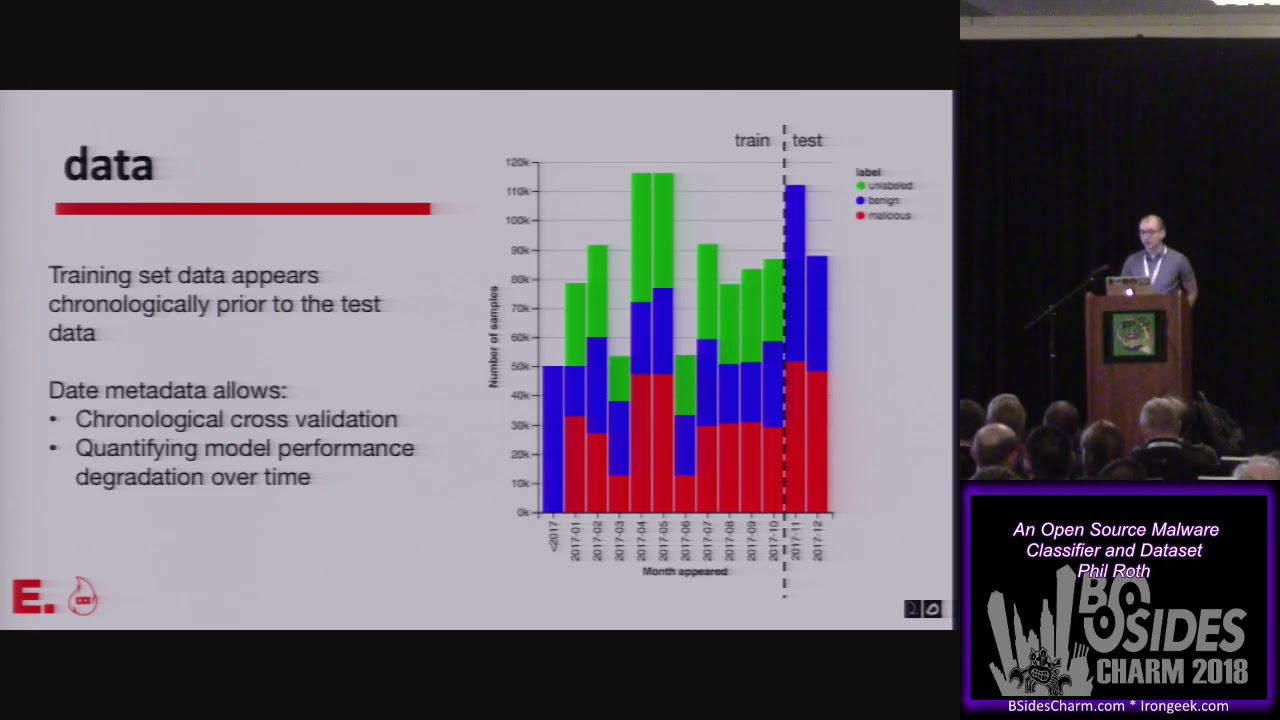
model trained on those features and there is a github repository that makes it easy to work with all of this data importantly it does not include the files themselves uh like i said earlier you know that that would kind of if we did include all these benign files uh they're not ours we would be releasing other companies intellectual property into the wild and we don't own those programs we can't do that but we can release derived features from all of those files so there it's divided into a training and test set we have a 900 000 training set and a 200 000 testing set the training set is divided between uh evenly divided between benign malicious
and unlabeled samples and the training set data appears chronologically prior to the test data and this is kind of important because it kind of reflects the nature of the problem you know malware is always evolving benign software is always evolving it looks different over time but you need to train a model at some point and release it so you can train a model on all the data you have at one time but then your goal with that model is to predict new data that comes along data that uh malware samples you haven't seen before or malware families that you haven't seen before so you need to train a model at some point and then judge its
performance on what comes next so uh i should have got that song into my problem my presentation here um yeah so all the training data that we provide labels for is in october or earlier in 2017 and this is when uh this is when the data is first seen when the malware or the benign files are first seen uh and then you can train a model uh on all that data up till then and then you can test it on samples that are first seen in november and december and then we provide the month that's part of the metadata that we're providing so it's not the exact day but by providing the month we can we
allow you to do chronological cross-validation or quantify model performance degradation over time so you know you train a malware model and it detects malware very well but then malware kind of continues to evolve to things that you haven't seen before and your model gets worse and worse at uh classifying that new uh malware so what you can do kind of with this data set is choose an arbitrary cutoff and say we're going to train on data up till june and then we're going to say how well does it classify data in july and then you can say how well does it classify data in august and so on and you can watch how uh how much worse your model becomes
uh so yeah that's a lot of information about the data there uh this is what it looks like actually on disk uh we're distributing that bzip2 file it's 1.6 gigabytes on disk uh when you extract it and you go into that directory there's seven json blob files and um yeah each line is actually a json blob let's we can look into one of these files here uh so the first three keys in each of those json blobs is kind of the metadata that's the hash i've already talked about the month and then the label zero for benign one for malicious and negative one for unlabeled and then the next keys in each of these blobs are the features themselves
and there are eight categories of features and those eight categories of features fall into two two different categories one the first that can be calculated just from the raw bytes all you need is the file itself and then you can count how many how many times each byte occurs and so on you can also extract strings right from that raw data but in a bunch of these categories of features you're going to actually need to parse the pe file format and so we're using an open source solution to do that called leaf it's the library to instrument executable formats and this quarks lab open source this library and we rely on it and we've got to give
a big shout out to the quarks lab people for for doing this all right one more note before i kind of go through those feature categories uh feature calculation is a two-step process this is the code the details are not important but i just want to highlight that there's two functions to calculate the features from from the file itself and that first step generates these json blobs that we're distributing that's kind of called the raw features that's what we've been calling the raw features once you have that json blob you need to feed it to the second function and the output of that function is a feature vector and that's just a vector of floats a feature vector
once you have a feature vector you can feed that into a bunch of different machine learning algorithms a lot of algorithms except feature vectors and the one the model that we're distributing is a gradient boosted decision tree that certainly accepts feature vectors so the point is uh it's a two-step process we're kind of releasing features in the middle of that process uh and we're doing that so that if you think you have a better solution for vectorizing features uh you know that we're using a feature hasher that's a function that's in the open source library scikit-learn if you think you have a better solution to doing that then you can take these json blobs vectorize the features yourself
train a new model and show that its performance is better than the benchmark model that we're releasing so we have byte histograms that's just how many times each plate occurs in a file uh we also do a byte entropy histogram calculation this is a kind of a sliding window entropy calculation that uh benchmarks it's uh those entropy calculations back to what bytes occur in that window uh but there's many more details in that paper that i show there uh there's also section information so we're looking at the pe header we're looking at what sections occur we're looking how big they are uh how complicated they are and we're also distributing what the entry section is
imports and exports uh we're showing with what libraries functions are imported from and and what the function names we're also listing all the exports uh string information i mentioned uh so we're not distributing all the strings that occur in the file because we were a little worried about personally identifiable information or intellectual property so we didn't want to release all those strings so release we're releasing statistics about those strings and you can see the number of them their average length we're doing a histogram of the characters that occur in all the strings uh those last four keys there that's kind of we have regular expressions uh that match strings that that might look like a path or might look
like a url and so then we're just counting up the number of times those types of things occur in the file and then distributing that count there's also general information here that's just kind of pulled from the the pe header itself and more specific information that's in the pe header like what machines these files were compiled on the compiler version this is all really small but the data is open source you can get it for all the 1.1 million samples so i talked a little bit about vectorization it i just want to dwell on the fact that it's a necessary step before you train a model and the code that we're releasing defines how you vectorize
these json blobs into feature vectors i downloaded the data onto this computer right here and the feature vectorization took 20 hours but it can take like as short as 15 minutes on on some servers that we have at endgame so it varies so that's a lot of information about all the features we're distributing uh i'm going to talk a little bit here about the model we're distributing as well we trained a model a gradient boosted decision tree model and we used the library lite gbm to train that model this is kind of a summary of the code that we use to train that model it's very simple we made no decisions going into it it's mostly default parameters
there's one parameter we specified there that we're doing a binary classification but other than that it's very very simple uh it's about 23 or 25 trees don't hold 25 decision trees don't hold me to that though uh but yeah and then that's distributed along with all the features uh and again yeah i trained the model on this laptop it took about three hours uh and it takes a little bit quicker on other servers oh yeah so once you have a model uh we've trained it on uh the three hundred thousand benign and three hundred thousand malicious samples that are in the training set we ignored the unlabeled samples uh and then once you have a model you can then
make a prediction on all the data that's in the test set and that's a histogram of all the scores there the red is for uh this the scores from the model on the malicious files and the blue is for those on the benign and you can see there's a little overlap which kind of represents the error but yeah the scores range from zero to one one for more malicious zero for more benign once you do make all those predictions on the test set then you can kind of make you can say how well you're doing and give some performance data the way i like to do that is a receiver operator characteristic curve and there's more information about
you know what that curve is kind of in the paper we're distributing but this is the once you generate that curve you can calculate the area under it the more area under that curve the better your model is at distinguishing benign from malicious uh so those are the numbers there um if you you can then pick a threshold like between zero and one uh you're gonna say okay 0.871 any score above that that's malicious that can't run on a computer anything below that uh we we see we say safe once you pick a threshold then you can say what the false positive rate with the false negative rate and so on is and so those numbers are right there
so big disclaimer this ember model is not malware score this is a research model malware score is better optimized has better features performs better and in my totally biased opinion is the best method for protecting your endpoints against malware it's great uh you i mean uh the ember model we're distributing it with code that allows you to make predictions you could conceivably like write up some python that uh makes predictions and protects your own machines with this ember model but i would not suggest it uh you know it's trained on data through october of last year and it because of the constantly evolving nature it's not ember is not going to be better it's not going to be very good at
detecting the latest malware uh code yeah so let's talk a little bit more about the code the repo is right there with it you can vectorize the features you can train the model you can make predictions on new pe files that come in so you can calculate the features and then use the model that we're distributing to make a prediction uh do yeah and then there is a notebook in there that kind of generates all the graphs in this in this presentation and also in the paper that we're distributing so it's very reproducible um it has files in there that kind of define the python environment that i ran everything in so you can pretty much do everything
that i did here so now that i've released this uh hiram and i hope certain things happen we hope researchers pick it up and run with it and we have a bunch of suggestions for what researchers could do the benchmark model like i said we didn't make many decisions we didn't optimize many parameters there's a lot of ways that you can improve the benchmark model you can use feature selection techniques to throw out some of the features that we provide uh you could find better features and extract them from the files themselves so in that case if you want to do that you would need access to the files themselves we don't provide that but we do provide the hashes so that
maybe research institutions or other companies that have access to virustotal might be able to download the files themselves and do their own research uh like i said you can also optimize the light gbm model parameters with grid search or you could do some semi-supervised learning that's incorporating information from unlabeled samples into the training itself that's actually a technique that the team the winning team from that microsoft malware challenge used uh they took the test set where the labels aren't provided and they trained uh they had like their first version of the model and then they classified everything in the test set where there's no labels and they got some rough labels and then if something is benign if they thought
something was benign they just said it was benign and handed it back into the training set and trained a new model and then that one kind of performed better on the test data in the end you can get into trouble doing that with overfitting and everything but you know by providing some unlabeled samples we hope some people do some semi-supervised techniques like that so that's all to beat the model uh that we're distributing uh you know there's more directions you can go and you can like uh i mentioned this before quantify the model performance degradation through time uh you can uh you can build and compare the performance of featureless neural network based models instead of like
gradient boosted decision trees like we uh relied on but again you would need access to the files themselves which we don't provide but uh we're hoping uh other bigger entities can can do that sort of research and then lastly this is kind of like an offensive research you could look into how can you modify the malicious samples that are in the training set to bypass the ember model or any other models that are out there and how best can you do that um you know that that's kind of like an offensive research but i think it's important for uh defenders to know about what might be coming so that they can be better prepared for those new
techniques all right demo time this is where talks are won and lost so i'm going to don uh the hat from a winning team to kind of channel some of their uh some of their winning ways so trust the process all right here we go so what i'm going to do is i'm going to download some of the latest benign files or the latest malicious files from virustotal and then use the ember model to make a prediction on them and see if it gets it right i already told you that you shouldn't do this you shouldn't use the ember model as a protection but hopefully it does okay so okay i did this search this morning i
just want to refresh it so that it's the very latest stuff all right so this is for pe files with um that 50 or more av scanners said is malicious so i'm going to download the um download the malware directly to my computer because i'm a trained professional and i can do that uh these are benign files so let's get one of those all right oh oh curses curses it's looking great guys it's great it's going great all right that looks ugly it was better before um all right let's see all right that's the search i did uh and then i sorted by what's um by the the very latest thing like it was first submitted in the last minute or
something uh so that's for benign files no scanner thinks it's malicious and then uh similarly here 50 or more scanners thinks it's malicious uh so those i'd already downloaded those uh let's go over here uh there that's there right there um okay so now here's the data uh that's the um that's the the data set that you can go out and download right now uh if you extract it all it looks like this on disk that's those uh json files and that this is the ember model there that last one uh and the cool thing about light gbm is uh it exports the model and saves them to disk and it's actually just text and so you can look at it uh you can
inspect it this is some feature if i go up high enough you can see the actual trees and the decisions it's making and what features it's making those decisions on it's kind of cool uh so this is the code i've already checked it out um i've already installed it so i'm not going to try and do that but there's scripts in here one to train the whole model from the beginning to end and one to classify binaries this is all showing up yeah all right all right so let's point it at the model
model and then let's point it at the all right so it loads the model uh i got a score of 0.95 and 0.27 let's just check that one i guess the web pages look bad so oh here so the malicious one was 185 and we got 95 and the benign one was 593 and we got that uh pretty low score so we did it victory just like the 76ers all right
all right so ember read the paper it's available on archive this is a highlight evidently despite increased model size so in the paper uh to understand the sentence uh we have the model we show its performance we also trained a convolutional neural net uh we kind of took the technique from other from another researcher who said you know this is the best way uh to do this sort of thing without features and we compared the performance and the neural net was the performance was a little less it was not as good and so we evidently despite increased model size and computational burden featureless deep learning models have yet to eclipse the performance of models that leverage domain model via parsed
features and what we're saying by that is that the gradient boosted decision trees they do better it's an older technique but right now they do better in the problem of malware classification you know deep learning is great and has had great results in a lot of different fields uh harm and i just don't think that kind of those kind of leaps and bounds have made it to malware classification and we hope that uh you know by releasing this data set that we can kind of bring those great results that deep learning has done in other domains into this domain and so bring it on download the data get the code thanks a lot
yeah i didn't fill the hour sorry so i can take lots of questions so yes the question the question was how did we decide that threshold of 0.871 so we decided what our target false positive rate was going to be at point one percent and then uh we kind of just scanned through the thresholds until we found uh exactly where we where we hit that false positive rate of 0.1 it is uh but you just you don't want to flood um you don't want to flood with alerts i mean false positives really decrease confidence in the user of a model and if you're going to start flagging on people's um you know the software that they need to do their
jobs they're really not going to like trust your model and so we we aim for very very low false positive rates that's kind of where we start oh yeah yeah oh no no yeah yeah i was just kind of trying to motivate why we do that sort of thing
i didn't look at that the question is uh what are the best features like it can you analyze the decision tree and figure out what features it relied on and um yes you can do that no i haven't done that um uh i've done some studies like with malware score about like what features are best um like section information like the entry section like that sort of thing really helped out um but no we do need to dive into that and i do hope that kind of research is spurred by this because um you can do model inspectability and you kind of can't like right now we just give a number and it's not like
it there's no information about why the number is that like why does this model think this is malware and we're hoping by releasing an open source model there'll be more research into that like getting better at explaining the decisions the model makes anything um
uh i mean we we've tested it with like latest stuff like this the stuff we download from from uh virustotal um but nothing powershell specific no i didn't look into that uh and no i didn't really look into like the different families and the performance on of this model on different families um but but yeah that would be a good a good area for further study
uh no plans to do that uh it was a lot of work getting this together and i i need to get back to malware score but um but i i hope i hope researchers look at it and if in publishing more papers about it like a problem becomes you know inescapable or something then maybe we can do like a 2018 version later that makes better decisions but right now uh right now we don't have any plans to update it
what was
actually yes because because the feature generation code is released if you have access to data or pe files that you are interested in then you can generate those features and release those features um you know that it so so that's possible definitely yeah
okay all right thanks a lot i'll be around if you have any more questions [Applause] thanks
Related talks
 42:16
42:16 47:29
47:29 54:48
54:48 18:17
18:17 42:15
42:15 30:48
30:48