Grapl — A Graph Platform for Detection and Response
Show original YouTube description
Show transcript [en]
thank you all for coming in my talk I've Brian I'm a software security and looking at Dropbox on their detection and response team if you're not very familiar with detection and response the very short summed up version of my job is that I am tasked with tracking suspicious behaviors across Dropbox's various environments if something looks particularly bad I'm going to spend some time scoping it out figuring out the root cause and then if it's actually an attacker or more likely our red team I'm going to ensure that they've been completely removed from the environment today what I'm gonna be talking about is a project that I work on outside of work so this is not affiliate with Dropbox
it's called grapple grapple is an open source analytics and five-four that targets detection and response work graph is kind of the key word there a sort of a graph based approach to detection response from a higher level as well as how grapple leverages that to make a lot of the things that I do at my job a lot faster and more ergonomic so before I jump into what grapple is let's just do a very quick overview of graphs graphs are a data structure just like a list or a hash map they hold on to information graphs are composed of nodes and edges nodes are gonna be oh shoot is it not updating okay I'm gonna do it
like this cool that should help so nodes are entities or things nouns right you could imagine a person Maps very nicely to a node edges are going to be those lines in between them they denote relationships between nodes as an example you might have two person nodes and an edge between them because they are friends graphs are a really powerful data structure for a whole number of reasons I think one of the easiest ways to demonstrate that is with a very empty plane graph like this right there's no explicit labels there's not a lot of data here but even still I can say a lot of interesting things about this graph I can say things like the purple node has
a relationship with the green and the blue node and the green node has a relationship with the blue node and the reason I can do this is because of a really great property of graphs where they encode information about relationships into their structure itself that's going to make them a very powerful visualization tool but that same property is going to come up in a lot of different places okay graphs are they're out of sync here graphs are really powerful data structure so of course all these different companies are leveraging them Google's knowledge graph powers their search engine Facebook's graph API is what underlies all of their public API is graphs are also leveraged in things
like tensor flow as part of the the way that the representation of its computation is so tensor flow is a form of dataflow programming which means it executes as a graph for context tensor flow is a machine learning library that was able to power alphago and defeat all the top go board game players and that was a really big deal when that happened graphs also tend to be very emergent so BGP and the Internet right is essentially a graph of routers communicating with each other and packets sort of traverse that graph and that just sort of sprung about given that all these companies are leveraging graphs for these different use cases it makes a lot of sense that the security
community has started paying more attention to them a couple of years ago John Lambert at Microsoft wrote a post about some of the areas where he sees graphs and security in this post Lambert makes a very bold claim he states defenders think and lists attackers thinking graphs so long as this is true attackers win Lambert then goes on to give an example of this list in graph based thinking he talks about how when defenders are given a network to protect one of the first things they'll do is start creating lists such as who are the domain admins who are the high value users what are the risky assets and from this work they'll begin prioritizing
what they're going to do to defend that network this is very different from how attackers go about doing their job attackers will gain a foothold on whatever asset they can actually get their hands on they're going to leverage the capabilities of that asset such as by dumping credentials from memory using tools like me me cats and then they'll begin abusing the trust relationships of your users and your network to move laterally across it according to Lambert this mismatch in approach is so fundamentally bad for defenders that we we cannot get around it without a shift in thinking at the end of Lambert's post he has this quote he says manage from reality because that is the prepared
defenders mindset so I think if you if you read that post and you think about what he's talking about you try to get that that fundamental reality I think there is a more generalized concept here which is that if you take information that fits really cleanly into one data structure such as a graph and then you try to force it into another data structure like a list you lose information you make certain operations less optimal in this case we're losing that that trust relationship information that a graph makes very clear completely removes okay that slide is dead cool bloodhound is a tool that I think has really managed to love it give me one moment I'm gonna see if I can move
this over yup this is why I have two tabs open cool so this is the speaker view okay I have three tabs open just backups for my backups okay cool it's very prepare so I think bloodhound is a really great demonstration of this graph based approach bloodhound allows you to visualize your active directory structures so that you can move from a world where you do things like say who are my domain admins and start asking questions like what are the paths to my domain admin and it does this by visualizing all of your Active Directory data as have been putting a query it as a graph so that's a really fundamental shift in how you do that work it's a new
capability altogether when you start thinking in that way so in detection response sort of the fundamental primitive that we use for our work is the log logs are these digital representations of events across a network what we do is we index billions and billions of these logs every single day collecting them and storing them in what's called a sim which is effectively just a giant list of logs and we'll search through that list of logs trying to find suspicious behaviors and if we find them we go back to those other logs to pivot off them and get other behaviors right so everything is based on this log construct now if you pull out a couple
of logs right and you put them next to each other like I have here you can start to see that there's actually these implicit relationships between them right I can see that the parent pit in one log in the pit and another actually matches with a parent pit in a different log right when you start pulling these relationships out and turning them into graphs becomes very obvious what's going on we're exposing not just the event in isolation but we're telling a whole story about what's happening here we're seeing those relationships we're seeing those behaviors so this is really what grapple is all about what grapple aims to do is what a sim does with logs
grapple wants to do with graphs so your detection work your response works coping all of that's going to be graph based grapple runs in an AWS account so after you set it up what you'll do is send it some raw logs grapple supports sis Mon as well as a more generic JSON format that you can target grapple will do very much what we saw on that last slide it's going to pull out a subgraph representation based on those logs mapping things like pigs to nodes it'll perform some identification steps because we want canonical identities we don't want to think in pigs we want to think about you know a node a process being a node as it's self-contained
identifiable construct these identified sub graphs get merged into a giant master graph so there's this graph database that's constantly real-time being updated representing all the entities and behaviors across your network that master graph is being built an updated grapple will orchestrate the execution of your attack signatures or what grapple calls analyzers and those are going to perform a sort of pattern matching and query that master graph for suspicious behaviors when finally when enough analyzers go off and you decide that this is something you need to investigate grappled provides a tool called an engagement and that's going to allow really quickly pivot across your logs and fully scope and attack behaviors so I'm gonna be going over how all of this
works sort of the graph based fundamental behind it and just try to give you a high-level overview of what grapple is able to do so when I talk about that master graph I'm really talking about what you see here at least day there are some core provided graph abstractions we have things like processes files external IP addresses and connections to them right so we can represent all of these things in our graph today in the very near future this should actually all work it just has to go to master I can do things like provide asset nodes as well as internal network communication which would be really great for lateral movement detection zhh beyond that grapple
provides a dynamic node construct the plug-in system uses I'll go but essentially you can just expand this graph with plugins however you want you can see that nodes are pretty standard processes have things like process names files have paths and then there are these sort of special edges these special properties like a process has children or files that it's created right in those edges point to a list of other nodes so this is this is what grapple is under the hood so I mentioned that there's an identification stage this ends up solving a lot of really important problems that a log based system will have the two problems I run into with logs are that for one thing
pidz those pseudo identifiers is process IDs they get reused they're not actually really good identifiers so the same thing with file paths right if I create a file and delete it and then you know some attacker puts a file there it's important to realize that those are two distinct entities so one thing that instrumentation tools like sis Mon will provide as a process gooood construct so you don't have to worry about pit collisions you get true identity but it doesn't solve the second problem I have which is that when I want to understand some kind of construct like a process I will search for that process gooood right and okay no more Pig collisions but I'm going to have to comb through
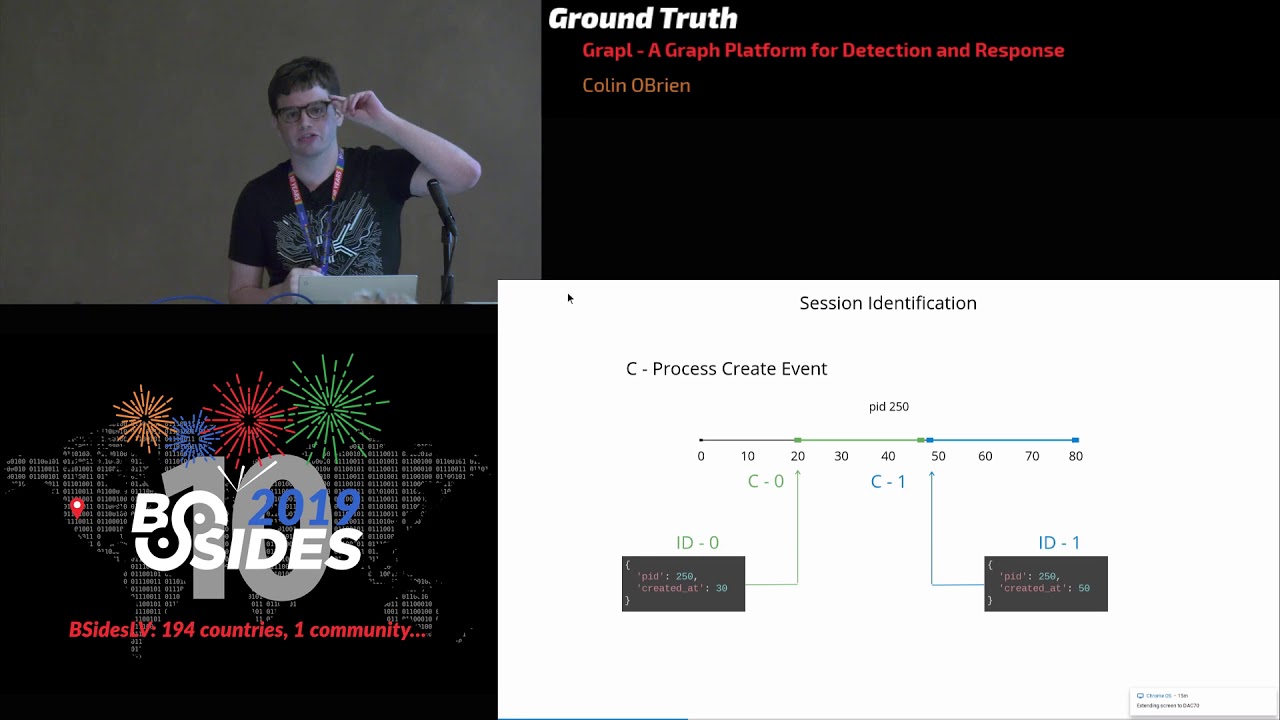
tens or even hundreds of odd lines just to understand what it's doing there's tons of redundancy in between there if you've seen a sis Mon log probably 70% of that data is duplicated across every log so what grapple is going to do is much like sis Mon it'll generate a canonical identifier for any logs that you send up not just windows but anything grapple can parse and then it's going to coalesce all of the unique information into just one place one node write an economical identifier is called a node key I'm gonna talk very quickly about one method of identification just so you can kind of internalize what this looks like this is session based
identification sessions are things like processes or files they have a pseudo identifier like a pit or a path but it's only good for a period of time when the process has started all the way until it's ended right the way grapple solves identification is it we'll look at logs like process creation or termination logs and it'll start building up timelines for every pseudo identifier for every asset here you can see that there's two process creation logs and so we can say that kid 250 on this asset has the ID 0 for the time span of 20 to 50 and then there was another process creation log so we know that there must be a new entity from 50
to wherever that next log is when this other log comes in because the process has actually done something to find its identity we just look it up in the timeline now keep in mind that grapple is going to handle all of these crazy edge cases for you one obvious one is that your instrumentation might start up after a lot of your processes have already started so you'll never get those process creation logs there's a lot of heuristics and other work that goes into handling those cases but this is the path and this is what identification means in grapple all right let's talk about detection so log based detection I think tends to drive us towards
properties or artifacts right we will look for hashes and we might even look for things like command line arguments I think the command line argument example is a really really useful one because command line arguments aren't actually interesting attackers can change them they can use they're binary different command-line arguments or bring their own binaries right what we're using command-line arguments for when we use logs to build rules is as a proxy for the underlying behavior I don't care that you know curl execute with a dash F I care that the attacker is sending a file off of the box that's the foundation and logs don't do a very good job of exposing those those core behaviors on top of that
those sims the the indexes kind of punish you for writing searches that have to look at more than one log at a time so if I want to pivot in part of my rule going from an execution log over to a network log over to something else the sim might actually just break if I try to do that joining performance is is generally something that starts getting exponential very quickly one demonstration of where this relationship-based rule would be really helpful as if we have these two logs here these are just to process creation logs one is forward and one is for PowerShell now these are both valid digitally signed Microsoft binaries they are almost certainly executing in the
vast majority of environments yes PowerShell is a tool that attackers like to use but so does system admins and again if we if we put these logs next to each other we can see that there is this implicit relationship right when we turn this into a graph I can see but it's not word or PowerShell or any properties of those processes that I really want to build a rule around it is the fact that word is executing PowerShell it is actually the hidden information that I care the most about in this case and even more so it's not word and PowerShell being having that relationship it's it's really just the fact that there is a an assumption that
two processes shouldn't have a relationship in this environment right so the more generalized structure based query that we want to get to is tracking things like unique parent-child executions when you start designing your attacks as if they are graphs I think the attack signature has become really obvious we have executions of word talking to an on wait list at IP a right this is gonna be kind of property heavy but the properties are more of an optimization to increase our sense of risk we can also use more generalized searches like the one I talked about earlier the unique parent-child process more complex searches that require multiple hops right or even some causal analysis like we have here a a process
that has talked to an external IP address and then it created a file and then it executed that file building that kind of rule in a log based system is prohibitively difficult you wouldn't reach for that kind of rule because you would know it would be painful so my opinion is that this graph based approach that we've sort of designed here is already strictly better than a log based approach I can take advantage of properties when I want to take advantage of properties and that's that's great let that word dot exe talking to evil comm right I'm thinking a lot about specifics there but I can also track fundamental attacker behaviors if an attacker has to worry
about process executions being unique you are changing how an attacker is going after your network of course the truth is that we have to treat really nice crafted word with an anomalous connection very differently than the parent-child process anomaly right one of those is going to happen hopefully never but the parent-child process one could happen fairly often your environment and so for this reason we introduce a concept of risk right now I'm essentially labeling the the master graph saying these small pieces here are very risky and these other pieces here are not that risky right so again this is a nice improvement this fits more with my mental model of how I want to track attacker behaviors and make their
life harder still there's one more level that we kind of want to get to as an example what if it happens to be the case that word talked to a non wait-listed domain and also word has a unique parent-child relationship I don't want to have to write a whole new signature for that I already have two signatures here right I want those to just automatically compose together so for this reason grapple has a concept of an asset lens or a username lens these these lens nodes allow you to view otherwise isolated risks under a specific concept like a username or computer so here we can see that all of these independent risks that I had started tracking
actually overlap and I can take that overlap into account when I'm describing the asset lens risk itself right I can say that this specific computer is not just the sum of the risks under it but also at a multiplier like an extra 10% for every node that overlaps right because that's extra sketchy when these things are overlapping so the actual implementation of this is going to be in Python that's the language that you would use to write these analyzers I chose Python for a number of reasons my experience with query language and and domain-specific languages that are very common in the state of the art systems is that they front-load a lot of their power they're really purpose-built
for specific scenarios and anytime you try to move into some other scenario they really start fighting back you get performance problems you get huge huge queries because you can't abstract things away you compare that with something like Python Python is an extremely general-purpose language I think it's probably fair to say that it's the language of choice for a large part of both the data science and the security communities you can build out powerful abstraction x' and you're never gonna feel particularly limited by python in my opinion so analyzers and grapple are these flat Python files that you'll deploy these will get called on every single update to the master graph so this is a real-time system there's no
search query like periods or anything like that it's just gonna happen on every single update this function will get called and passed in a client to talk to the master graph you will get a few node views our concrete representation of some node that exists in the graph and then a sender which we'll use to emit hits so this analyzer here is going to look for suspicious executions of processes because their parent process is word right we don't expect word to be created subprocesses so this process only involves I'm sorry this query only involves processes so if it's not a process note we're just going to ignore it like if this is a file note or a
network node this it's not relevant to this signature will create our process query we will constrain it by saying that it has to have the name when word Exe and it has to have some children which we won't constrain because there's there's no whitelisting here to do any the process is going to be suspicious to me I want to track it I'll then call query first and pass it the client and I also pass it the node key for the node that was passed into us for the node that was just recently updated that's really important because that allows this query to execute in constant time so you might be thinking this graph is gonna have you know billions and
billions of nodes and this analyzers gonna get executed over and over again you know hundreds of times in a minute easily but it's always going to execute in the exact same amount of time or roughly speaking because it's a constant time operation you're gonna notice that's a trend in operations in grapple they will always be constant time whenever possible the reality is that we collect more and more data every single year it's even just having linear access times it's not going to scale to next year when I've doubled the amount of volume right so if we get a response back we will omit the execution hit I'll give it a name I'll give it a risk score
and I'll see what that the the concrete node was that I'm considering to be sketchy right so pass in P and you know this is this is pretty bad so give it a risk score this tour of 90 right one example of how Python is able to provide us with these powerful abstraction x' is that we can leverage this parent child counter that grapple provides this is just a specialized interface it's going to encapsulate all this nice logic forests and just expose a single method called get count for we don't have to worry about how this works under the hood there's actually a lot to it for example there's actually a Redis connection for this parent child counter
so in the vast majority of cases because of the constraint API we actually don't even have to talk to the graph database to get these counts this is just an example of how you can build really powerful reusable constructs in a way that most sims are not going to allow you to and so we can also build out these more complex queries here we have a signature for processes that have a binary file where that binary file was created by what I'm calling an unpacker something like 7-zip or WinRAR now here we've got a really low risk score right I'm calling this 15 if you try to spend your time whitelisting something like this you're
just going to waste hours or days you're never going to whitelist something like this because new software will be deployed and it's going to use this sort of approach but it's still an interesting behavior that I want to track in my environment so I can move away from thinking about whitelisting and black-and-white situations of good and evil and just say that you know let's track this and if it correlates with something else we get that nice multiplier because of lenses and I don't have to waste my time right that's really important I spend a lot of time on white listing searches that would just be better served if I could downgrade them I think maybe the best
part about leveraging tools like Python is that you get to benefit from best practices standard practices right if you compare the number of people who are writing you know elastic searches query language or spunks query language to the number of people writing Python it's orders of magnitude difference if you start googling how to write a unit test for Splunk you're not going to get very nice results you will find that it is entirely unsupported compare that to Python your standard library just import unit tests that's it right we can already start building out testing infrastructure I can deploy this code to github which grapple supports via get hooked I can add linters code reviews I
can roll back and revert changes if they're broken continuous integration right my opinion is that as an incident response team starts to scale alert management is one of these problems that's going to start creeping up on you more and more and you're gonna say I thought we had an alert for that and it turns out that it was actually just broken the whole time you didn't have tests for it so this is a huge value add for actually managing the searches that you're creating cool I'm gonna talk about investigations so log based investigations usually start off with one or more logs and maybe a ticket that tells me why I should care about the information in
this log right so here maybe you know that that hash is just known to be bad for some reason the way I usually start off an investigation like this I'm going to take a look at the suspect process see what it's done but I'm not gonna spend too long on it I'm immediately gonna start tracing it backwards and find the root cause and see where this thing came from so what I'll do is I'll open up a search window in my sim say the last eight hours right somewhere around a business day and I'll pick a field to start looking over so let's let's look at the pit right I want to see what this process is done and I'll
get like tens or hundreds of logs back maybe I get too many and I have to spend some time cutting it down but okay a general idea of what this thing is doing not an obvious false positive time to start tracing it backwards let's look at the parent pit maybe I find that the parent pit is something like launch D or cron right it's legitimate this is a dead end the attacker has set this up to execute in a week or two weeks right so I'll start looking for that file that's the only thing I can start pivoting off of I'll search for the files hash right and I don't get anything back not great
but okay there are a lot of reasons why that might happen I'll try the image name but I'm still not getting anything clearly this file was dropped a long time ago I'm not getting any logs back so what I have to do at this point is extend my search window back and now you can see I've got some logs related to that image name which is great but I'm paying a very serious cost these are ear searches at best which means that if I extend my search window by doubling it let's say every search from this point forward is now twice as slow on top of that and really much worse is that I now
have bid collisions paid collisions in my experience for a client laptop if they are running Chrome in particular are going to happen basically every couple of hours my investigation is going days it's essentially a guarantee pit collisions suck they are really annoying to deal with you have to start saying pit after this time but not before this time stuff like that it's really painful and it's because lawns don't have that strong sense of identity so there's currently a couple of other problems here one of the problems that's maybe a little harder to see is that I don't actually have a good idea for how I'm pivoting I want to know more things about that fine
really I just want to know what created it but all I've got is this hash I'm just gonna hope that that hash shows up somewhere in other logs I don't know that I'm pivoting to the information that I want I don't know if it's on the other side switch tabs let's see what we got oh wow that's not good get a replay of the talk almost there all right sorry bear with me with exactly two minutes while the speaker Wi-Fi is not working for me and so I'm going to tether to my phone which will just take less than 30 seconds I apologize tethering mobile hotspot just connect to the Wi-Fi and reload cool not what I was hoping for
okay that should do it I again apologize for that and it's gonna be slow Wi-Fi at that so spoilers cool okay so that didn't take you long grapple takes a completely different approach to investigations from this at the heart of grapples investigation process is the jupiter notebook in this room maybe some people are familiar with that essentially it's this Python environment that you can interact with in your browser you can do all these crazy things you can split your Python codes you can inline markdown upload images replay different cells it's a really powerful tool and importantly it is the tool that the data science community has been leveraging for years my opinion is that the
detection response field has a lot of intersections with the data science field we do a lot of the same work we're all just trying to hunt data to find something that looks like signal right so we should be paying attention to what that looks like here uh yeah wrong dad killing me start presenting yes cool okay so grapple has a sort of two browser pain user experience on one pain you will have a live updating view of your engagement the engagement graph that you see here just contains two nodes one represents the engagement and metadata around it the other is this svchost.exe as I mentioned earlier we don't have to comb through hundreds of logs I can see every unique piece of
information about that SVC host right there at the bottom it's on one place for me at the bottom of the screen you can see from a jupiter notebook where i actually instantiated this engagement called demo and then i pulled in a node based on its process it's it's a node key right I can't really both panes at once very easily so I'm going to show you each mint and then the graph essentially we're going this thing off I'm going to do exactly the same workflow as before I want to understand what a process has done one of the most important things to me is what children processes has it executed so I'll say get the children for this process and
I'll just you know print out their process names and I can see command dot exe three times so this thing is shelling out to some sub processes through command obviously sketchy again this is a constant time operation doesn't matter how much data is involved man dot exe was executed months or a year later constant time lookup these edges all of these get underscore methods are also live updating graph view to pull in those new notes which you'll see in a moment so let's keep going let's trace this process backwards I'll go up it's process tree we can see its parent is command dot exe which you would see in the graph and there's a grandparent process which is called
dropper dot exe and we can keep going and eventually we'll see that the user downloaded this dropper dot exe from Chrome this is what the graph ends up looking like and it's a pretty nice story right we can say that the user executed chrome from Explorer chrome executed this dropper process we've got dropper shelling out to SVC host and the Ness VC host shelling out to these other command dot exe and this is what it looks like right so as you're typing in the commands on the right side you're going to see all of those nodes automatically just get pulled in on the left side so we've solved a lot of those problems that we talked about with a
logging system right I'm not fighting my data anymore I don't have to worry how much data is there cuz it's all constant time operations there's no search windows right before I really wanted to keep my search windows small so that my queries would run fast but I also wanted my search when it'd be as large as possible so that I could search over the most relevant data here that's that's a non-issue we don't even think about search windows I have identity so I don't have to look at multiple logs or nodes I just look in one place and I can see all the unique relevant information and I have my pivot points if I want the
children I just asked for the children I say get children right I don't have to search for the child pigs or anything like that and hope that I get the information back so that's all the the sort of graph stuff for people that's the detection and the response and the identification of it there is also another important word with grapple and that is that it is a platform grapple does not intend to solve every single problem on its own that would be silly instead it is built to be very modular and extendable and it actually provides a plug-in system on top of that everything in grapple works through a vent submission or receiving so you have these AWS lambdas those are
just server lists compute functions they get triggered every time something is uploaded to specific AWS s3 buckets that's just a storage interface and they can read and write to these buckets and Avot emit new events right so it's very easy to extend because if I want to add say a custom parser all you have to do is subscribe to the right event stream grapple provides a plug-in system for this the plug-in system is still in early stages but this is fairly representative it'll only get better from here there are three components to building type in this case I'm gonna walk you through what it looks like to set it up for our duty that's an Amazon offering where you pay
the money and they send you logs to tell you when something bad is happening in your environment so we're gonna build a a subgraph generator it's gonna parse logs and turn them into graphs that's what you see here we're gonna build that that query construct like we saw that process query right we want to be able to build analyzers around these ec2 instances and guard duty alerts as well as a view construct so that we can represent it's in that graph the first component is going to be built in rust the others are built in Python I do not expect anyone to be particularly rust savvy this is just pretty simple code it's mostly boilerplate and the macros
are going to take care of a lot of it so so what we're gonna do here is just focus on this AWS ec2 instance you can see at the top here I'm just gonna put whatever property is exist in a node you can see there's an Arn that's the AWS resource name it uniquely is that resource am user anything any of us identify we also have a launch I mean there's all these other properties that I've omitted here just for screen space I've added a macro that is not showing up super well on there gray on gray but essentially what we're saying here is turn this structure into a dynamic node right that dynamic node is a construct
that grapple knows how to understand and will identify that node using a static strategy so earlier you saw the session based strategy statics easier it's just a lookup we can say the Arn maps exactly to its canonical ID right that macro is going to generate two things for us one is the dynamic node version of that structure so it'll be a AWS ec2 instance node and then an interface for that structure implementing that interface is pretty trivial it is one method and it is always the same exact code and that's gonna basically allow grapple to do all these things on top of that node everything from ear is pretty simple we get logs we parse them using a standard
JSON parsing library we get a structure out we create our node we just instantiate it by calling new we're going to pass in that static strategy method that's generated by the macro so you don't have to implement that or anything and at this point we just populate that node with information we'll set the yarn we'll set the launch time we put it into a graph description concept or construct and and that's it this is all the code that's necessary my opinion is that if you do this once it'll be really easy to do it a second time you'll probably run into a couple of things just not necessarily knowing rust very well it's it's really quite simple once you know
what you're doing everything from here is going to be a Python and it'll be even easier this is the ec2 instance query you saw the process query earlier right this is how our analyzers are going to start looking for sketchy patterns that have ec2 instances in them really technically the only thing you have to do is write this code here it's just a constructor we're going to inherit from the dynamic node query and it will provide all of these interfaces under the hood for us but can provide a kind of prettier API we'll wrap those internal interfaces with ones that have nicer names like with launch time or with instanceid but that is it this is
all code you need to start building at this point so if use our what we use in engagements and our what we actually consume from the analyzers when something is updated so we'll create a view construct for this AWS ec2 instance it's really quite simple we have a constructor that has to take a couple of values the DeGraff client the graph database that the master graph uses a node key a youíd and then just whatever properties our node has pretty simple just construct that you're your superclass and then mostly we're gonna be adding helper classes but there are two methods that we have to go and implement here pretty simple everything is just a mapping of field name to type
so launch time is an integer R is a string that's because the Python code doesn't know the schema of the graph database you kind of have to create these mappings for it same thing for the edge types there are reverse edges denoted by tilde so AWS ec2 instances have no forward edges but they do have reverse edges like all the guard duty alerts that they are a part of right so we say for any finding resource reverse edge there can be many guard duty alert views because we might be a part of multiple alerts and from an - instance perspective talk about those alerts we call them guard duty findings right so it's sort of the the mapping of a
reverse edge to a forward edge and again we will add these helper methods so this is all pretty simple these are all of the constructs that you technically need to implement a plug-in and grapple this is still a work in progress I'm hoping to cut some of this down and provide some more intuitive interfaces but really not much work I built this guard duty plug-in which included users and and alerts and all these other things I think it was our and I was building the system as I was doing it so it's pretty pretty quick there is only one more piece here and that's the actual deployment technically you can deploy this however you want as
long as it goes into ec2 but grapple provides a construct to the Amazon Cloud development kit so that's an infrastructure as code group of libraries and and things like that grapple provides a library and typescript it'll be in Python soon but Python was not supported when I started building this pretty simple we'll use the event emitter construct we're gonna create a new event emitter for guard duty logs so a few us will just ship those off into an s3 bucket and it's all set up all the events and notifications a service construct that's gonna set up our AWS lambda which will actually run the subgraph generator and we'll set up a an integration with the output bucket
the police we're going to emit new events to in this case the unidentified subgraph bucket and that's it you can run deploy cdk deploy all of your code is going to go up there it'll all be managed by AWS really nice and easy setting up grapple is intended to be as easy as possible if you clone the repo butt to the grapple - cdk folder you can fill out a dot env file there is one field in that file and it is a bucket prefix just use an organ a m-- anything that's like not going to be taken by somebody else it just has to be unique and run the deploy all script and that's
it it'll take about 15 minutes but you don't have to sit there and even hit yes it'll just take its time at setup those resources at this point once you've run this script the lambdas are all set up the graph database is set up everything needed for identification the s3 buckets the user interface that we saw earlier for engagements that's it right so about 50 minutes couple of commands there is one last thing that has to be done we're gonna provision the schemas for that graph database so that grapple knows how to talk to it properly for this we can go to our AWS console select sage maker we can just pick the notebook that
grapple has already created for us right down there at this point either create a new notebook or you can just use the one that's provided by grapple run this notebook it's going to provision everything and at this point you're done send up some test data which is also these are system on logs you can see upper dot exe and the malicious SPC host you can investigate those check out what the network traffic was right dropper dot exe pulled that file from somewhere you can figure out from where you can look at the the child processes and see what those are doing and just you know perform your own investigations so I believe I should have time for questions
cuz I went as quick as I possibly could but like I said grapples open source if you're interested in contributing interested in using it feel free to hit me up always happy to talk to people about it [Applause] yeah nice job couple questions so how do you think about recursive state so for example if you look at those ec2 instances network firewall rules might be on/off on/off changed how do you guys think about that and then second question is two entities multiple edges because there can be multiple relationships between them how do you guys think about that yeah yeah those are both really good questions I would say that the hardest things I deal with
with grapple are have really big implications for the workflows and that sort of thing so answer your second question first it's a little easier what that comes down q is just a decision so example right now grapple does not have a concept of like multiple times store all the metadata and multiple times or right that's usually the abstraction and then the interface can abstract over that very very easily it's really just a question of whether you want those different rights and that sort of thing with grapple a connections are another good example which has an edge to an inbound connection which has an edge to a process right so there's these intermediary nodes that we can hold that
information in so really just making that call as recursive systems I'm not sure I fully understand exactly what you're asking maybe if you could clarify I think I kind of understand the the IP so it's not as much about recursive systems it's about successive state changes so if you think about something like a firewall rule typically what happens in vulnerability gets sick it's open gets closed that time sequence it's not clear how that's represented these it's the same state being changed multiple times on the same entity yeah yeah that's that's a really good question and again one of the tougher modeling questions that I've run into state changes are something you can abstract away by saying like here's a
node representing the firewall rule for this time to this time and another node with this new firewall rule right so if you wanted to expose that for something like a firewall rule that makes a lot of sense and you could build an entity to plug in you have a are you give a clarify I was just gonna say both those cases those somewhat permute the constant time calculation piece right because those grow linearly or exponentially based on the number of connections or stay right yeah so let's say your firewall changed like a hundred times right then you have to perform a hundred edge expansions the good news is that edge expansions are extremely efficient and hopefully your firewall
isn't changing like millions of times but yeah totally reasonable thing there one thing that I've thought about the nice thing about being an AWS and about being a platform is that we're not constrained to the the graph database even right if I wanted to I could have a dynamodb table that just tracks firewall State for everything and then the analyzer would write to that table and then query the table and say like okay summarize this information has it changed for this port right so in theory if you wanted to solve that problem there's there's nothing stopping you from just setting up a new system in terms of represented in the graph it's a hard call to make it really depends for
a firewall I might be inclined to put that into the graph because I don't expect on tons of changes for something else you know graphs are awesome for for a huge amount of these workloads I think they're a great like native fit for most cases but if something doesn't fit into it set up another database put your data in there right optimize for that for the workload you're looking to solve yeah cool hey thanks for a great talk and of course for open sourcing it yeah I was just wondering I don't know to what extent you have used this or deployed this at scale and relied on it but sort of the fundamental basically the Splunk
problem that everybody's got is sort of the volume of logs that you've got to deal with and it sounds like to some extent you know you're getting rid of a bit of the redundancies that you would deal with all these like tons of logs revolving around the same thing yeah do you have a sense of sort of the storage efficiency that you can reach by having sort of everything already identified codified into this graph database versus holding on while the logs that you would over a month two months three months for an entire fleet yeah yeah that's a good question so in terms of scalability it's it's kind of variable right so the logs that I work with at home are gonna be
sis Mon logs and system on logs just and they have so much redundant information I have something like 60 megabytes of I run tests with those in seconds that's that's nothing and the the actual storage property is about an order of magnitude less than that in terms of the data that grapple actually has to hold on to should scale really well as you add more and more redundant data but it's gonna be super workload dependent right so if you have I think the good news is that for the systems that are the worst offenders for something like Splunk they're actually the best case for grapples so an extremely noisy process that's doing tons and tons of
things that's grapples best case because very few of those things will actually be unique in terms of logs for systems where it's like tons and tons of you different processes and files executing it will certainly be no worse than Splunk its worst case is linear scaling so yeah it's it's hard to give a good metric there because it's so use case dependent the system itself has a huge factor on it so it's it's hard to really answer that directly yeah but it it is no worse than Splunk certainly and I have felt those exact bands that's always the the goal yeah anything else
do you see a standardization coming down the pike for like predicate names types or like RDF namespaces as this concept gets more popular yeah absolutely so biggest focus that I have been having over the months is getting to stability API stability that's actually why the plug-in system exists so that I can stabilize the core of start moving other concepts to separate systems that can stabilize at their own pace most of what you saw is entirely stable so the query interface for processes should be stable that's not an API guarantee yet but I intend it to be very soon the competent formation model that I'm using is standard it's it's a little bit modified because I have that but for the most
part those properties are absolutely stable edge names it's it's subject to change at this point on top of that I mentioned that I'll probably have these sort of intermediary nodes to handle things like writes once that's out of the way which is probably a matter of weeks I I will be stabilizing it and I'll make straight the API guarantees yeah that's it's a big focus right now
okay [Applause]
Related talks
 8:26:49
8:26:49 37:51
37:51 29:14
29:14 29:35
29:35 36:05
36:05 45:20
45:20